
技术摘要:
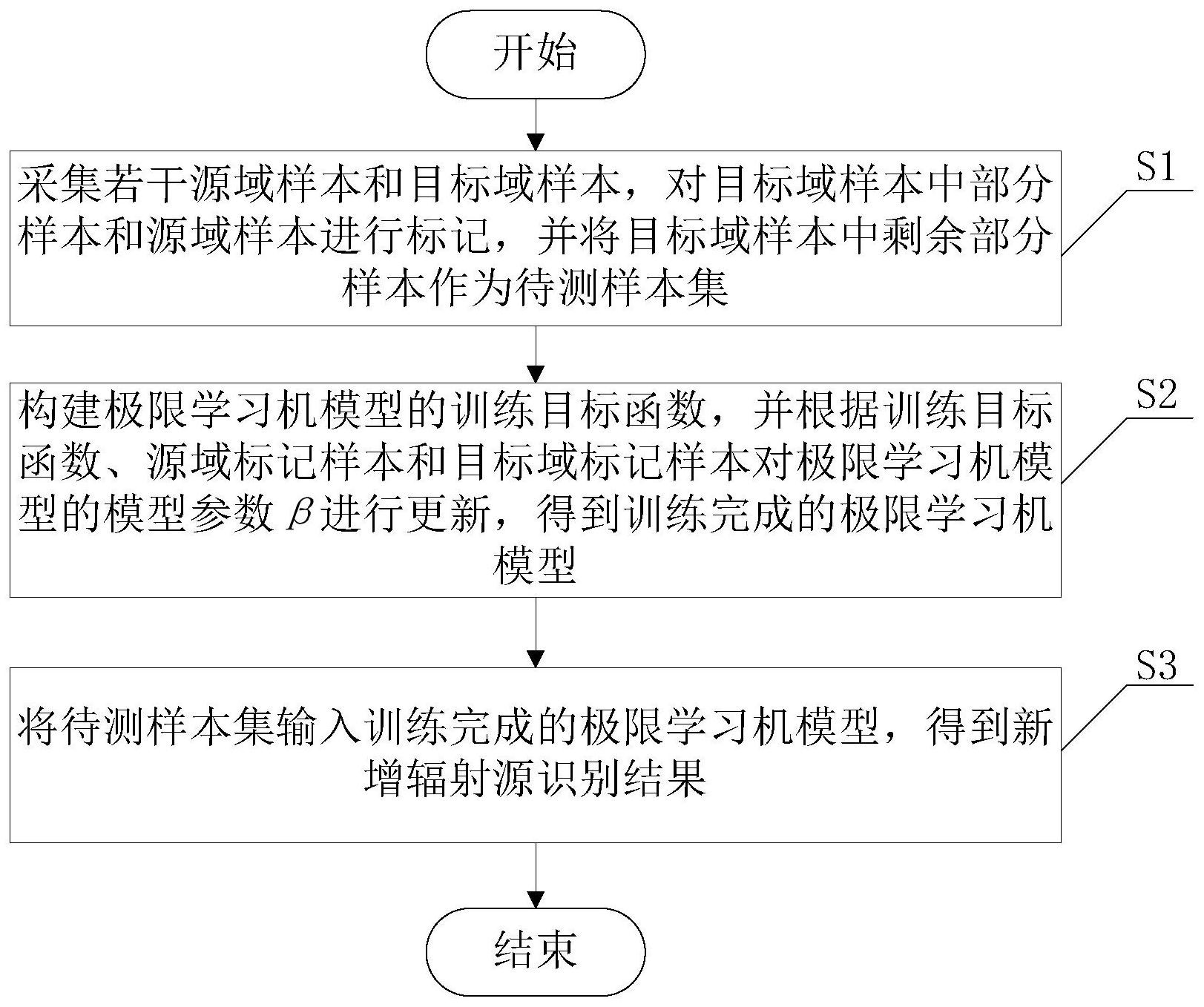
本发明公开了一种基于加权迁移极限学习机算法的辐射源识别方法,包括以下步骤:采集若干源域样本和目标域样本,对目标域样本中部分样本和源域样本进行标记,并将目标域样本中剩余部分样本作为待测样本集;构建极限学习机模型的训练目标函数,并根据训练目标函数、源域 全部
背景技术:
在现代电子战应用环境中,受时间、空间、作战需求等因素的影响,快速变化的战 场条件极大的增加了设备采集辐射源信号的难度,仅能获取少量带标签的辐射源样本数 据。因此在小样本条件下,辐射源新增个体的识别问题亟待解决。目前针对小样本条件下辐 射源个体的识别问题,主要有两种解决方案:基于卷积神经网络的迁移学习和迁移极限学 习机算法。基于卷积神经网络的迁移学习算法其基本思想是在已知数据集上训练好卷积神 经网络模型,然后通过快速简单的调整将该模型应用到另一个数据集上。即是利用大量已 知辐射源样本训练卷积神经网络模型,并保留模型中卷积层的参数不变,然后利用少量带 标签的新增辐射源样本训练模型的全连接层参数,进而识别新增辐射源个体。然而,由于深 度神经网络层数多,复杂度较高,因此网络参数量庞大,少量的标记样本难以使模型参数得 到充分训练,导致新增辐射源个体识别的错误率较高,识别性能难以满足应用需求。迁移极 限学习机算法是在极限学习机和迁移学习的基础上,利用大量源域辐射源标记样本和少量 新增辐射源标记样本构建极限学习机模型,使得该模型将从源域学习到的知识迁移至目标 域,从而实现目标域新增辐射源个体的识别。然而,由于不同的源域样本对建立目标模型的 有效性存在差异,直接使用源域中的各样本容易导致模型出现“负迁移”的问题,影响模型 在目标样本集上的识别性能,因此该算法下,模型的识别性能不稳定,当源域中存在坏样本 时,将直接干扰和影响目标模型的构建。
技术实现要素:
针对现有技术中的上述不足,本发明提供的一种基于加权迁移极限学习机算法的 辐射源识别方法解决了现有技术识别错误率高、模型识别性能不稳定以及算法严重依赖于 样本数量的问题。 为了达到上述发明目的,本发明采用的技术方案为:一种基于加权迁移极限学习 机算法的辐射源识别方法,包括以下步骤: S1、采集若干源域样本和目标域样本,对目标域样本中部分样本和源域样本进行 标记,并将目标域样本中剩余部分样本作为待测样本集; S2、构建极限学习机模型的训练目标函数,并根据训练目标函数、源域标记样本和 目标域标记样本对极限学习机模型的模型参数β进行更新,得到训练完成的极限学习机模 型; S3、将待测样本集输入训练完成的极限学习机模型,得到新增辐射源识别结果。 进一步地,所述步骤S2中训练目标函数LW-TELM为: 4 CN 111582373 A 说 明 书 2/6 页 所述 和 与β的关系分别为: 其中,s.t.表示条件限制,β表示极限学习机模型的模型参数,Cs表示源域s的预测 误差平衡常数,Ct表示目标域t的预测误差平衡常数,W表示源域样本的权重矩阵,Ns表示源 域样本总数,Nt表示目标域样本中的标记样本数, 表示第i个源域样本的预测误差, 表 示第j个目标域样本的预测误差, 表示源域样本对应的隐层输出, 表示目标域样本对 应的隐层输出, 表示第i个源域样本的标签,Y jt 表示第j个目标域样本的标签。 进一步地,所述步骤S2中根据训练目标函数、源域标记样本和目标域标记样本对 极限学习机模型的模型参数β进行更新的具体方法为: A1、将源域标记样本输入极限学习机模型,获取源域样本的隐层输出; A2、获取源域样本的权重矩阵; A3、将目标域标记样本输入极限学习机模型,获取目标域样本的隐层输出; A4、根据源域样本的隐层输出、权重矩阵和目标域样本的隐层输出,对极限学习机 模型的模型参数β进行更新。 进一步地,所述步骤A1中源域标记样本为 其中,Xs表示源 域样本集合,Ys表示源域样本标签集合, 表示第i个源域样本, 表示第i个源域样本标 签; 所述步骤A1中获取源域样本的隐层输出Hs的公式为: Hs=g(a·Xs b) 其中,g()表示激活函数,a表示输入权重参数,b表示隐层偏置。 进一步地,所述步骤A2中获取源域样本的权重矩阵为W=diag{Wi},diag( )表示对 角矩阵,所述权重Wi为: 其中,di表示第i个源域样本与目标域样本均值点之间的欧式距离,i=1,2,..., Ns,Ns表示源域样本总数。 进一步地,所述步骤A3中目标域标记样本为 其中,Xt表示 目标域样本集合,Yt表示目标域样本标签集合, 表示第j个目标域样本,Y jt 表示第j个目 标域样本标签,j=1,2,...,Nt,Nt表示目标域标记样本总数; 所述步骤A3中获取目标域样本的隐层输出Ht为: 5 CN 111582373 A 说 明 书 3/6 页 Ht=g(a·Xt b) 其中,g()表示激活函数,a表示输入权重参数,b表示隐层偏置。 进一步地,所述步骤A4具体为:将训练目标函数相对于模型参数β的梯度设置为 零,并判断训练样本数是否大于隐层节点数,若是,则令模型参数β等于第一最优解β1,否则 令模型参数β等于第二最优解β2,完成对模型参数β的更新。 进一步地,所述训练样本数包括目标域标记样本数和源域标记样本数。 进一步地,所述第一最优解β1为: 其中,Cs表示源域s的预测误差平衡常数,Hs表示源域样本的隐层输出,T表示转置, W表示源域样本的权重矩阵,Ct表示目标域t的预测误差平衡常数,Ht表示目标域样本的隐层 输出,Ys表示源域样本标签集合,Yt表示目标域样本标签集合。 进一步地,所述第二最优解β2为: 其 中 ,A 表 示 第 一 计 算 参 数 , B 表 示 第 二 计 算 参 数 , I表示单位矩阵,C表示第三计算参数, D表示第四计算参 数, 本发明的有益效果为: (1)本发明针对源领域样本对目标任务帮助存在差异性的问题,对源域样本进行 加权处理,从源域中挑选出有利于目标模型训练的样本并增加其权重,使得该分类器模型 能更适用于目标分类任务,解决了负迁移问题。 (2)本发明提升了知识迁移的效率,提高了小样本条件下,新增辐射源个体分类识 别的准确度和稳定度。 (3)本发明通过结合极限学习机理论,利用源域样本和目标域中有限的标记样本 建立目标分类器模型,使极限学习机具有知识迁移能力并且无需依赖大量样本进行反复迭 代训练,有效的满足了小样本的条件限制。 附图说明 图1为本发明提出的一种基于加权迁移极限学习机算法的辐射源识别方法流程 图。











