
技术摘要:
本申请涉及一种文本处理方法、文本特征关系抽取方法及装置。文本处理方法包括:根据第一文本样本集中的第一文本样本、第一文本样本的权重训练目标模型,对目标模型进行模型参数更新,第一文本样本集中包括噪声文本样本;将目标模型的模型参数共享至参照模型;根据第二 全部
背景技术:
随着人工智能的发展,机器学习模型的使用越来越广泛。通过预先对机器学习模 型进行训练,使得机器学习模型能够进行数据处理。比如,预先训练关系抽取模型,使得关 系抽取模型能够识别文本中的实体以及实体之间的语义关系。 但是,训练所使用的样本数据大多存在噪声数据,噪声数据会引导机器学习模型 向错误的方向优化,进而影响机器学习模型的性能。
技术实现要素:
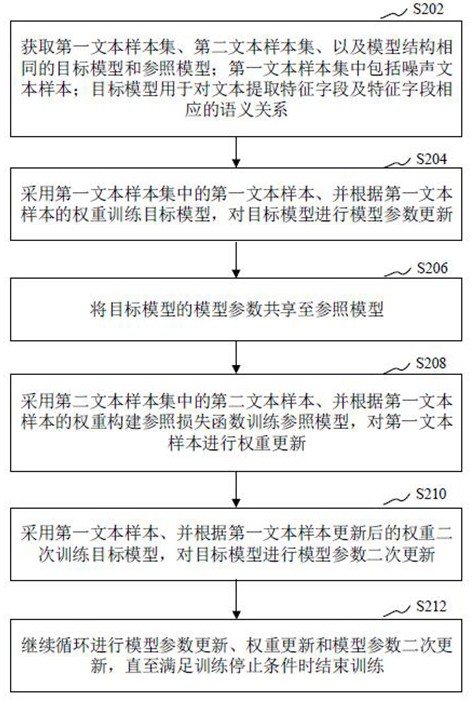
基于此,有必要针对上述技术问题,提供一种能够提升机器学习模型性能的文本 处理方法、文本特征关系抽取方法及装置。 一种文本处理方法,该方法包括: 获取第一文本样本集、第二文本样本集、以及模型结构相同的目标模型和参照模型;第 一文本样本集中包括噪声文本样本; 采用第一文本样本集中的第一文本样本、并根据第一文本样本的权重训练目标模型, 对目标模型进行模型参数更新; 将目标模型的模型参数共享至参照模型; 采用第二文本样本集中的第二文本样本、并根据第一文本样本的权重构建参照损失函 数训练参照模型,对第一文本样本进行权重更新; 采用第一文本样本、并根据第一文本样本更新后的权重二次训练目标模型,对目标模 型进行模型参数二次更新; 继续循环进行模型参数更新、权重更新和模型参数二次更新,直至满足训练停止条件 时结束训练;目标模型用于对文本提取特征字段及特征字段相应的语义关系。 一种文本处理装置,装置包括: 获取模块,用于获取第一文本样本集、第二文本样本集、以及模型结构相同的目标模型 和参照模型;第一文本样本集中包括噪声文本样本; 训练模块,用于采用第一文本样本集中的第一文本样本、并根据第一文本样本的权重 训练目标模型,对目标模型进行模型参数更新; 共享模块,用于将目标模型的模型参数共享至参照模型; 训练模块,还用于采用第二文本样本集中的第二文本样本、并根据第一文本样本的权 重构建参照损失函数训练参照模型,对第一文本样本进行权重更新; 训练模块,还用于采用第一文本样本、并根据第一文本样本更新后的权重二次训练目 标模型,对目标模型进行模型参数二次更新; 6 CN 111553170 A 说 明 书 2/23 页 训练模块,还用于继续循环进行模型参数更新、权重更新和模型参数二次更新,直至满 足训练停止条件时结束训练;目标模型用于对文本提取特征字段及特征字段相应的语义关 系。 一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计 算机程序时实现以下步骤: 获取第一文本样本集、第二文本样本集、以及模型结构相同的目标模型和参照模型;第 一文本样本集中包括噪声文本样本; 采用第一文本样本集中的第一文本样本、并根据第一文本样本的权重训练目标模型, 对目标模型进行模型参数更新; 将目标模型的模型参数共享至参照模型; 采用第二文本样本集中的第二文本样本、并根据第一文本样本的权重构建参照损失函 数训练参照模型,对第一文本样本进行权重更新; 采用第一文本样本、并根据第一文本样本更新后的权重二次训练目标模型,对目标模 型进行模型参数二次更新; 继续循环进行模型参数更新、权重更新和模型参数二次更新,直至满足训练停止条件 时结束训练;目标模型用于对文本提取特征字段及特征字段相应的语义关系。 一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时 实现以下步骤: 获取第一文本样本集、第二文本样本集、以及模型结构相同的目标模型和参照模型;第 一文本样本集中包括噪声文本样本; 采用第一文本样本集中的第一文本样本、并根据第一文本样本的权重训练目标模型, 对目标模型进行模型参数更新; 将目标模型的模型参数共享至参照模型; 采用第二文本样本集中的第二文本样本、并根据第一文本样本的权重构建参照损失函 数训练参照模型,对第一文本样本进行权重更新; 采用第一文本样本、并根据第一文本样本更新后的权重二次训练目标模型,对目标模 型进行模型参数二次更新; 继续循环进行模型参数更新、权重更新和模型参数二次更新,直至满足训练停止条件 时结束训练;目标模型用于对文本提取特征字段及特征字段相应的语义关系。 上述文本处理方法、装置、计算机设备和存储介质,先对目标模型进行模型参数更 新,接着将目标模型的模型参数共享至参照模型,通过参照模型调整第一文本样本的权重, 并利用第一文本样本、第一文本样本更新后的权重对目标模型进行模型参数二次更新,且 模型参数更新、权重更新和模型参数二次更新循环进行,这样,目标模型和参照模型交迭训 练,参照模型对目标模型每一步训练的样本权重进行调整,以降低噪声文本样本对目标模 型每一步训练的影响,进而提升模型性能,提高文本特征关系抽取的准确性。 一种文本特征关系抽取方法,该方法包括: 获取待处理文本; 确定待处理文本相应的文本特征向量; 将文本特征向量输入目标模型,通过目标模型输出待处理文本的特征字段及特征字段 7 CN 111553170 A 说 明 书 3/23 页 相应的语义关系; 其中,目标模型通过与参照模型交迭训练得到;训练目标模型包括采用第一文本样本 并根据第一文本样本的权重,对目标模型进行模型参数更新;训练参照模型包括共享目标 模型的模型参数,采用第二文本样本、并根据第一文本样本的权重构建参照损失函数,对第 一文本样本进行权重更新;训练目标模型还包括采用第一文本样本、并根据第一文本样本 更新后的权重,对目标模型进行模型参数二次更新。 一种文本特征关系抽取装置,装置包括: 获取模块,用于获取待处理文本; 确定模块,用于确定待处理文本相应的文本特征向量; 输出模块,用于将文本特征向量输入目标模型,通过目标模型输出待处理文本的特征 字段及特征字段相应的语义关系; 其中,目标模型通过与参照模型交迭训练得到;训练目标模型包括采用第一文本样本 并根据第一文本样本的权重,对目标模型进行模型参数更新;训练参照模型包括共享目标 模型的模型参数,采用第二文本样本、并根据第一文本样本的权重构建参照损失函数,对第 一文本样本进行权重更新;训练目标模型还包括采用第一文本样本、并根据第一文本样本 更新后的权重,对目标模型进行模型参数二次更新。 一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计 算机程序时实现以下步骤: 获取待处理文本; 确定待处理文本相应的文本特征向量; 将文本特征向量输入目标模型,通过目标模型输出待处理文本的特征字段及特征字段 相应的语义关系; 其中,目标模型通过与参照模型交迭训练得到;训练目标模型包括采用第一文本样本 并根据第一文本样本的权重,对目标模型进行模型参数更新;训练参照模型包括共享目标 模型的模型参数,采用第二文本样本、并根据第一文本样本的权重构建参照损失函数,对第 一文本样本进行权重更新;训练目标模型还包括采用第一文本样本、并根据第一文本样本 更新后的权重,对目标模型进行模型参数二次更新。 一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时 实现以下步骤: 获取待处理文本; 确定待处理文本相应的文本特征向量; 将文本特征向量输入目标模型,通过目标模型输出待处理文本的特征字段及特征字段 相应的语义关系; 其中,目标模型通过与参照模型交迭训练得到;训练目标模型包括采用第一文本样本 并根据第一文本样本的权重,对目标模型进行模型参数更新;训练参照模型包括共享目标 模型的模型参数,采用第二文本样本、并根据第一文本样本的权重构建参照损失函数,对第 一文本样本进行权重更新;训练目标模型还包括采用第一文本样本、并根据第一文本样本 更新后的权重,对目标模型进行模型参数二次更新。 上述文本特征关系抽取方法、装置、计算机设备和存储介质,通过目标模型提取待 8 CN 111553170 A 说 明 书 4/23 页 处理文本的特征字段及特征字段相应的语义关系,且该目标模型是与参照模型交迭训练得 到的,先对目标模型进行模型参数更新,接着将目标模型的模型参数共享至参照模型,通过 参照模型调整第一文本样本的权重,并利用第一文本样本、第一文本样本更新后的权重对 目标模型进行模型参数二次更新,且模型参数更新、权重更新和模型参数二次更新循环进 行,这样,参照模型对目标模型每一步训练的样本权重进行调整,以降低噪声文本样本对目 标模型每一步训练的影响,提高文本特征关系抽取的准确性。 附图说明 图1为一个实施例中文本处理方法的应用环境图; 图2为一个实施例中文本处理方法的流程示意图; 图3为一个实施例中文本处理方法的流程框图; 图4为一个实施例中更新后的权重的示意图; 图5为另一个实施例中文本处理方法的流程示意图; 图6为另一个实施例中文本处理方法的流程框图; 图7为一个实施例中文本特征关系抽取方法的流程示意图; 图8为一个实施例中医学知识图谱的示意图; 图9为一个实施例中文本处理装置的结构框图; 图10为一个实施例中文本特征关系抽取装置的结构框图; 图11为一个实施例中计算机设备的内部结构图。











