
技术摘要:
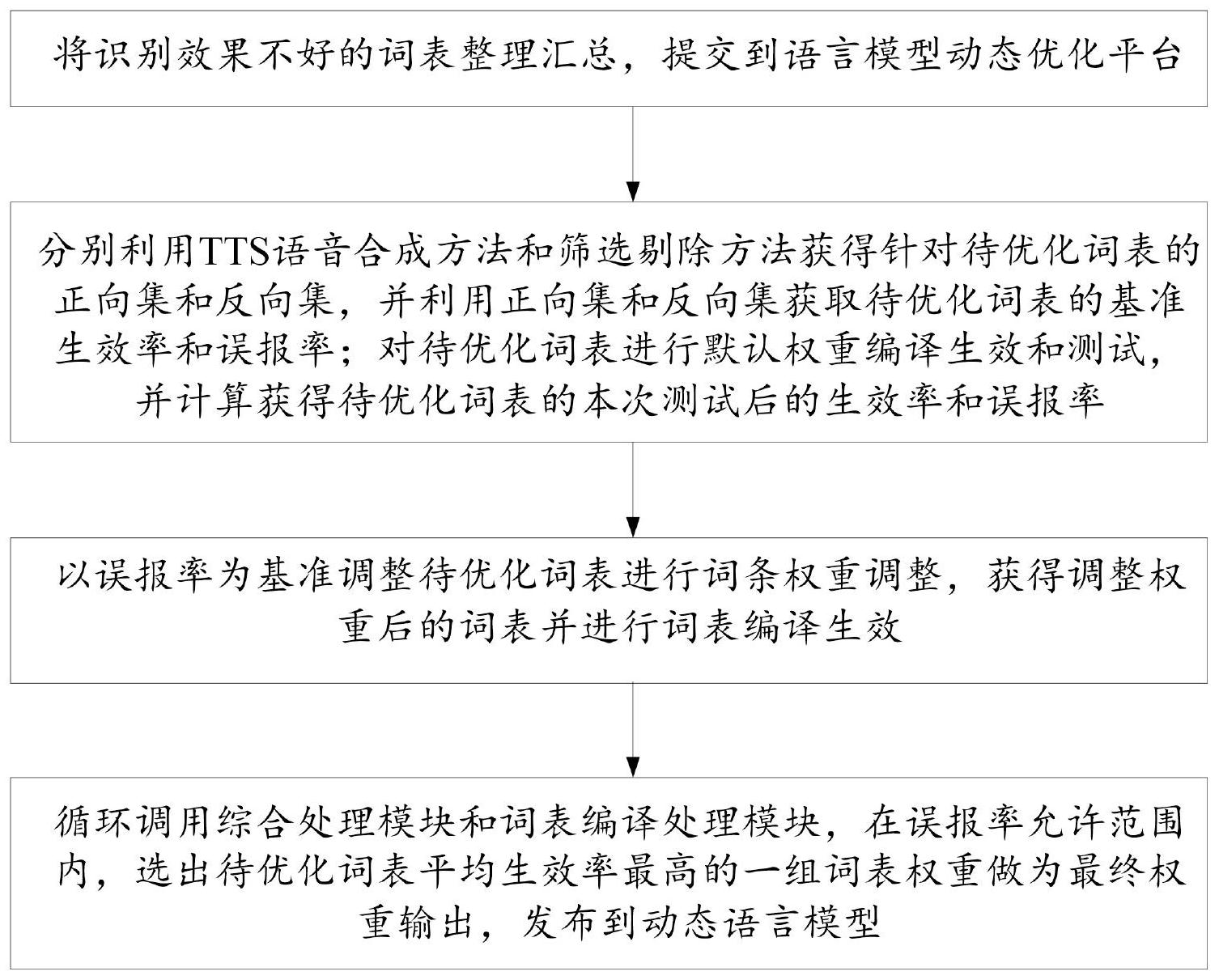
本发明提出了一种提升动态模型识别准确率的方法和系统,所述方法包括:首先,将识别效果不好的词表整理汇总并提交到语言模型动态优化平台,作为待优化词表;然后,分别获得针对待优化词表的正向集和反向集、基准生效率和误报率;对待优化词表进行默认权重编译生效和测 全部
背景技术:
目前语言模型主要包括静态模型即通用语言模型与动态模型即用户自定义模型 两部分。在进行ASR识别时,将动态模型与静态模型打包,送ASR引擎进行识别。静态模型优 化发布上线周期较长,对于一些热词,不能及时的进行识别,给用户识别带来一定问题。通 过动态模型定制优化,可以解决这种问题,但是存在部分词条实施后不生效或者乱识别的 问题。动态模型实施词条后,识别不生效或者乱识别,导致实施后没有达到预期效果。比如 实施一个品牌名称[携住科技],当用户说[介绍一下携住科技]时,识别结果却是[介绍一下 协助科技],实施的携住科技这个词条未生效。
技术实现要素:
本发明提供了一种提升动态模型识别准确率的方法和系统,用以解决现有方案 中,动态模型存在部分词条实施后不生效或者乱识别的问题,所采取的技术方案如下: 一种通过动态词表调权重以提升动态模型识别准确率系统,所述系统包括: 导入模块,用于将识别效果不好的词表整理汇总,提交到语言模型动态优化平台; 综合处理模块,用于分别利用TTS语音合成方法和筛选剔除方法获得针对待优化 词表的正向集和反向集,并利用正向集和反向集获取待优化词表的基准生效率和误报率; 对待优化词表进行默认权重编译生效和测试,并计算获得待优化词表的本次测试后的生效 率和误报率; 词表编译处理模块,用于以误报率为基准调整待优化词表进行词条权重调整,获 得调整权重后的词表并进行词表编译生效; 最终权重获取模块,用于循环调用综合处理模块和词表编译处理模块,在误报率 允许范围内,选出待优化词表平均生效率最高的一组词表权重做为最终权重输出,发布到 动态语言模型。 进一步地,所述导入模块包括: 待优化词表获取模块,用于筛选出识别效果不好的词表,并进行词表整理汇总; 词表导入模块,用于将整理汇总好的词表导入至语言模型动态优化平台,并将导 入至语言模型动态优化平台的词表作为待优化词表。 进一步地,所述综合处理模块包括: 正向集获取模块,用于利用TTS语音合成方法对所述待优化词表和语言模型动态 优化平台提前设置的若干句式进行合成处理,生成正向集; 反向集获取模块,用于利用固定的短语音测试集构成反向集; 基准获取模块,用于对正向集和调整后的反向集进行测试计算,获得待优化词表 5 CN 111597798 A 说 明 书 2/7 页 内的词条在未进行优化实施时的生效率和误报率,并将所述未进行优化实施时的生效率和 误报率作为基准生效率和基准误报率; 权重编译生效模块,用于对待优化词表中的每个词条进行默认权重编译生效,; 生效率获取模块,用于对正向集和调整后的反向集进行测试,计算获得待优化词 表中每个词条在本次测试后的生效率; 误报率获取模块,用于对正向集和调整后的反向集进行测试,计算获得待优化词 表中每个词条在本次测试后的误报率。 进一步地,所述正向集获取模块包括: 句式生成模块,用于利用语言动态模型优化平台对待优化词表的类别进行判断, 根据所述待优化词表的类别设置若干句式; 组合模块,用于将所述若干句式和所述待优化词表进行组合,获得组合单元; 正向集生成模块,用于将利用TTS语音合成方法对所述组合单元进行语音合成,将 合成后的语音作为正向集。 进一步地,所述反向集获取模块包括: 语音消除模块,用于消除所述短语音测试集中包含所述待优化词表的语音; 反向集生成模块,用于将消除包含所述待优化词表的语音后的短语音测试集构成 反向集。 进一步地,所述词表编译处理模块包括: 权重调整模块,用于以误报率为基准调整待优化低于基准生效率的词条的权重, 获得调整权重后的词表; 词表编译生效模块,用于将权重调整后的词表进行词表编译生效。 进一步地,所述权重调整模块包括: 权重增加模块,用于以误报率为基准,在误报率允许的范围内,不断增加待优化词 表中生效率低于基准生效率的词条的权重,权重增加范围为[0,2]; 误报率判断模块,用于判断增加权重的词条的误报率是否超过允许范围,如果误 报率超出允许范围,则启动权重降低模块; 权重降低模块,用于在所述词条增加权重后形成的历史权重的基础上,不断降低 词条的权重,直到所述词条的误报率恢复到允许范围; 词表编译获取模块,用于获取调整权重后的词条对应的词表编译。 一种如权利要求1-7任一所述系统对应的方法,所述方法包括: 将识别效果不好的词表整理汇总,提交到语言模型动态优化平台; 分别利用TTS语音合成方法和筛选剔除方法获得针对待优化词表的正向集和反向 集,并利用正向集和反向集获取待优化词表的基准生效率和误报率;对待优化词表进行默 认权重编译生效和测试,并计算获得待优化词表的本次测试后的生效率和误报率; 以误报率为基准调整待优化词表进行词条权重调整,获得调整权重后的词表并进 行词表编译生效; 循环调用综合处理模块和词表编译处理模块,在误报率允许范围内,选出待优化 词表平均生效率最高的一组词表权重做为最终权重输出,发布到动态语言模型。 进一步地,所述方法的具体过程包括: 6 CN 111597798 A 说 明 书 3/7 页 步骤1、将识别效果不好的词表整理汇总,提交到语言模型动态优化平台,作为待 优化词表; 步骤2、将所述待优化词表导入至动态模型实施平台; 步骤3、利用语言模型动态优化平台根据待优化词表的类别,提前设置若干句式, 将待优化词表和句式进行组合,然后通过TTS合成语音作为正向集; 步骤4、消除所述短语音测试集中包含所述待优化词表的语音,并将消除包含所述 待优化词表的语音后的短语音测试集构成反向集; 步骤5、对正向集和调整后的反向集进行测试计算,获得待优化词表内的词条在未 进行优化时的生效率和误报率,并将此时的生效率和误报率作为基准生效率和误报率; 步骤6、对待优化词表中的每个词条进行默认权重编译生效,默认权重为0; 步骤7、对正向集和调整后的反向集进行测试,计算获得待优化词表中每个词条在 本次测试后的生效率和误报率; 步骤8、以误报率为主,在误报率允许范围内,不断增加生效率较差的词条权重,权 重范围[0,2];如果误报率超出允许范围,则在该词条历史权重基础上不断降低词条权重直 到误报率恢复到允许范围,最终获得调整权重后的词表; 步骤9、将步骤8获得的调整权重后的词表编译生效; 步骤10、对步骤7、步骤8和步骤9进行若干次的循环调用,在误报率允许范围内,选 出待优化词表平均生效率最高的一组词表权重做为最终权重输出,发布到动态语言模型。 本发明有益效果: 本发明提出的一种提升动态模型识别准确率的方法和系统,给动态模型里加上权 重可调功能,以解决词条不生效或者乱冒的问题。在保证反向集不会乱冒的情况下,即误报 率控制在符合设定范围,来不断提高每个词条权重,用以提高词条生效率,使识别结果达到 最优。 附图说明 图1为本发明所述方法流程图; 图2为发明所述系统的结构示意图。











