
技术摘要:
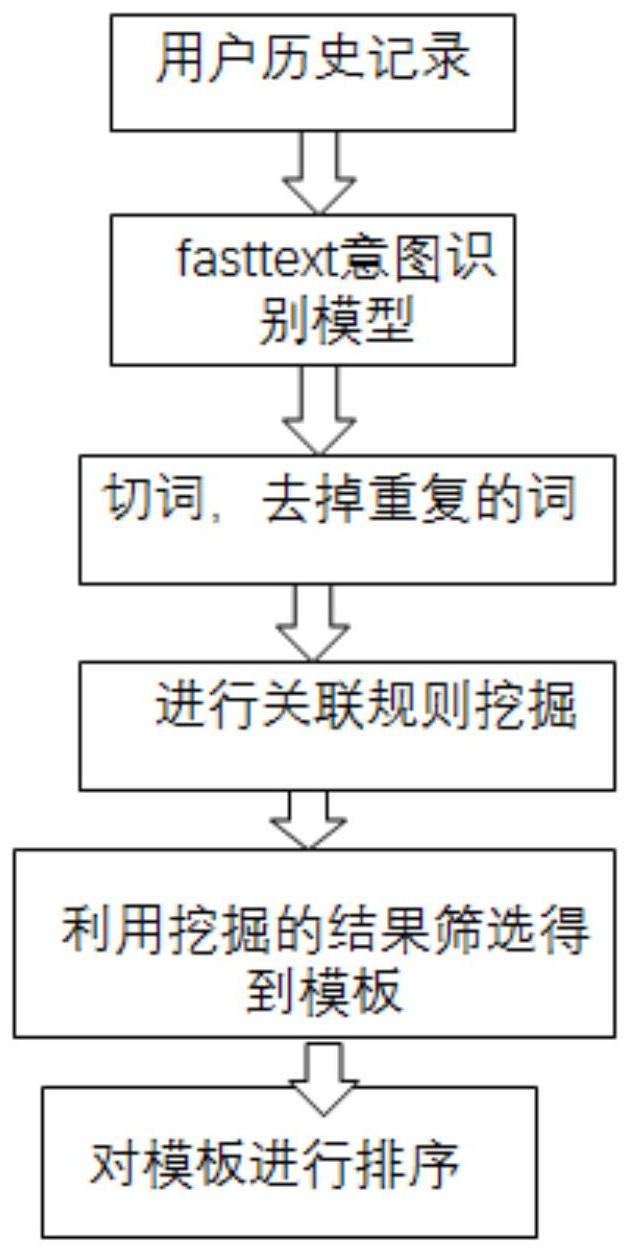
本发明公开了基于频繁项集的模板自动挖掘系统及其方法。所述系统包括意图识别模块、类目词替换模块、频繁项集挖掘模块、筛选模板模块、模板排序模块;意图识别模块对用户的历史搜索记录进行意图识别;类目词替换模块用于对经过意图识别以后的记录进行切词,替换类目词 全部
背景技术:
在垂直搜索中,当用户的搜索关键词与数据库中的规则词匹配时,就会返回数据 库中的相关数据。实际应用中,用户的搜索关键词是多样的,很难手动配置所有的匹配词, 随着搜索种类数目的增加,手动配置显然是一个不现实的做法,因此设计算法自动挖掘出 用户常用的搜索模板就很有必要。当前的研究主要是从用户的历史数据中挖掘搜索模板, 典型的代表为百度的搜索技术专利《需求识别模板的自动挖掘方法、需求识别方法及对应 装置》,该技术提供了一种识别模板的自动挖掘方法。具体的步骤为:在搜索日志中确定预 设类型对应的记录集合;从集合中选择对应预设类型被点击次数超过预设次数的记录,组 成种子模板;将种子模板中的预设类型词与预设词典的词语进行匹配,替换成类型属性词; 得到模板。 该技术的缺陷主要表现在:会丢弃一些具有潜在模板意图的记录。比如“七天酒店 多少钱”,“如家酒店多少钱”这两个记录公共的部分就是“酒店多少钱”,按照现有技术,如 果两个记录的点击量比较低就会剔除在外,实际上是有模板意图的。
技术实现要素:
为解决上述现有技术存在的问题,本发明提出了基于频繁项集的模板自动挖掘系 统及其方法,首先把记录切词,然后挖掘频繁项,这里的频繁项是“酒店”,“多少钱”,然后把 同时包含着两个频繁项的记录都保留下来,因此可以保持一些长尾低支持度高质量的记 录。 本发明的目的至少通过如下技术方案之一实现。 基于频繁项集的模板自动挖掘系统,包括意图识别模块、类目词替换模块、频繁项 集挖掘模块、筛选模板模块、模板排序模块; 所述意图识别模块用于对用户的历史搜索记录进行意图识别,并将经过意图识别 后的记录发送至类目词替换模块; 所述类目词替换模块用于对经过意图识别以后的记录进行切词,替换类目词,并 将替换类目词后的记录发送至频繁项集挖掘模块; 所述频繁项集挖掘模块用于对替换类目词后的记录进行频繁项集挖掘并将挖掘 的结果发送至筛选模板模块; 所述筛选模板模块根据频繁项集挖掘模块得到的结果对替换类目词后的记录进 行筛选,得到初步的模板并将其发送至模板排序模块; 所述模板排序模块计算最初的模板的熵值以及与已有匹配词的相似度,并根据熵 值,相似度以及搜索记录的次数对模板进行排序,得到最终的模板。 4 CN 111597322 A 说 明 书 2/7 页 进一步地,所述意图识别模块中,采用相关记录训练意图识别模型,所述相关记录 指的是用户的搜索记录,所述意图识别模型包括fasttext模型,采用训练完的意图识别模 型对历史搜索记录进行意图识别; 所述训练意图模型是输入带有类目标签的数据,模型的输出为对应的类目标签, 比如输入有:‘酒店多少钱’,标签是‘酒店’;‘天气怎么样’,标签是‘天气’,训练的时候给模 型的输入是‘酒店多少钱’,‘天气怎么样’,输出是‘酒店’,‘天气’,输入大量带标签的数据 后这个模型就会去学习其中的参数,经过训练使得意图模型根据输入的记录计算该记录分 别属于各个类目的概率并输出其中概率最大的类目,比如新输入‘附近酒店’,模型给出的 概率中,酒店类的概率最大,就把这个分到酒店类,属于其他的概率比较小,就不会分到其 他类。 进一步地,所述类目词替换模块中,采用结巴分词对经过意图识别的记录进行切 词,比如输入是‘附近酒店多少钱’,切词以后就会得到:附近/酒店/多少钱。再用匹配算法 就可以得到每一个词‘附近’,‘酒店’,‘多少钱’;将记录中和固定类相关的词语替换成固定 类目词,比如要进行酒店类目的模板挖掘,七天酒店,如家酒店等统一替换成[hotel],此处 的统一符号包括但不仅限于 [hotel]的表达形式。 比如要进行美食类目的模板挖掘,快餐店,美食店等统一替换成[food]。此处的统 一符号包含但不仅限于[food]的表达形式。这里是对历史搜索记录进行替换,比如历史搜 索记录中有‘附近快餐店’‘附近美食店’,本身会有一个词表,里面会包含‘美食店’,‘快餐 店’这样的词,这个词表是已经有的,是服务商提供的,可以直接拿到,然后如果搜索记录中 的词在这个词表中能找到,那么就统一替换为[food],也就是把‘快餐店’,‘美食店’替换为 ‘[food]’,得到‘附近[food]’。 进一步地,所述频繁项集挖掘模块中,所述频繁项集挖掘模块中,对替换类目词后 的记录进行切词,类目词替换模块中的切词,输入是‘附近的快餐店’,切词以后是‘附近的/ 快餐店’,频繁项集挖掘模块中的切词,输入是‘附近的 [food]’,切词以后是‘附近的/ [food]’;对切词以后得到的单词进行去重并且去掉标点符号作为待挖掘的项,利用关联规 则挖掘算法进行挖掘,然后将挖掘得到的结果发送至筛选模板模块。 进一步地,所述关联规则挖掘算法,包括FP-Growth算法。 进一步地,所述筛选模板模块中,对满足置信度的频繁项保留下来,然后把包括特 定频繁项的记录保留得到挖掘模板,所述置信度的计算公式如下: 其中P(A)指的是A出现的概率,P(AB)指的是A和B同时出现的概率。 进一步地,所述模板排序模块中,计算同一类型模板中配模词的可能性,利用熵值 来评价模板的通用性,所述熵值排序,衡量的是带有固定类目词所包括的可能性个数,熵值 S的计算公式如下: S=-∑p(A)log(p(A)); 比如挖掘出的模板是[food]多少钱,因为[food]是经过替换过来的,可能包含很 多种情况,假设这里的[food]包含了‘快餐店’,‘美食店’,‘火锅店’三种情况,其中‘快餐店 多少钱’这个出现了5次,‘美食店多少钱’出现了3次,‘火锅店多少钱’出现了2次,‘[food] 5 CN 111597322 A 说 明 书 3/7 页 多少钱’这个模板的熵值是: 加入另外一个模板是‘[food] 好不好呀’,只有一个类型的‘快餐店好不好呀’跟这个模板 匹配得上,假设‘快餐店好不好呀’出现了5次,那么这个模板的熵值是: 这个 熵值比前面‘[food]多少钱’小,从实际上可以看出,也是‘[food]多少钱’这个模板更加具 有通用性。 用余弦相似度计算与已有词表的相似度,模板挖掘是一个多次迭代的任务,每次 挖掘出来的单词会把排在前面的几个单词添加到实际要用的词表中,下次挖掘出新的单词 如果跟实际应用是词表中的单词比较相似,那么也就有理由相信这个新挖掘的单词添加到 实际应用词表中是比较合适的。实际上每个单词都可以用多维的向量来表示,这个向量的 表示是提前训练好的,也就是每个单词都会对应有一个多维的向量表示,然后计算向量之 间的余弦值就可以得到向量之间的相似度。比如A单词的向量表达式[1 0 1 1 1],B单词的 向量是[0 1 1 1 0 1], 计算这两个向量的余弦值就可以得到这两个单词的相似度。根据 熵值和与已有词表的相似度,训练LR模型即排序模型对模板进行排序,排序模型用到的是 LR 算法(线性回归模型),首先训练模型得到排序优先度占比参数,比如经过训练以后,熵 值占比40%,相似度占比40%,搜索记录次数占比20%,再根据熵值,与已有词表的相似度, 搜索记录次数的优先度占比参数对模板进行排序。 进一步地,所述排序模型的训练方法是,首先人工收集历史记录数据,与训练类目 相关的数据打上标签‘1’,不相关的打上标签‘0’,比如收集到‘附近酒店’,‘最近天气’,然 后‘附近酒店’是酒店相关的,‘最近天气’是天气相关的,假设现在在做天气相关的类目,那 么‘最近天气’这个输入会手动打上标签‘1’,‘附近酒店’手动打上‘0’;然后输入到排序模 型里面去训练,得到排序模型的优先度占比参数,下次输入新的记录安装该参数进行排序。 基于频繁项集的模板自动挖掘方法,包括以下步骤: S1:输入用户的历史记录,采用意图识别模块对用户的历史记录进行意图识别; S2:采用类目词替换模块对经过意图识别的记录用结巴分词进行切词,将记录中 和固定类相关的词语替换成固定类目词,得到替换类目词后的记录; S3、采用频繁项集挖掘模块对替换类目词后的记录用结巴分词进行切词并且进行 去重,把切词以后得到的词语作为待挖掘的项; S4:把经过S3处理的项输入FP-Growth算法,筛选指标选择支持度以及置信度,采 用筛选模板模块把满足支持度,置信度阈值的结果筛选出来; S5:遍历S1中处理得到的记录,把同时包含S4中频繁项的结果保留下来得到初步 的模板; S6:根据S5得到的模板,采用模板排序模块根据模板的熵值、与已有词表的相似 度、搜索记录次数,训练排序模型进行排序。 同一个模板的类目匹配词包含的可能性越多,熵值越大,模板通用性就越强;模板 自动挖掘是一个实时迭代更新的过程,挖掘出来的词语已有词表的语义相似度越大说明价 值越大;模板的点击量越大,某种程度也说明模板的价值。 相比于现有技术,本发明的优点在于: 6 CN 111597322 A 说 明 书 4/7 页 相比于现有技术方案基于搜索次数的挖掘可以挖掘出更多的模板。 附图说明 图1是本发明基于频繁项集的模板自动挖掘方法的步骤流程图; 图2是本发明实施例中意图识别模型具体应用示意图; 图3是本发明实施例中酒店类目挖掘示意图; 图4是本发明实施例中本发明跟已有方案的对比图; 图5是本发明实施例中美食类模板挖掘示意图。











