
技术摘要:
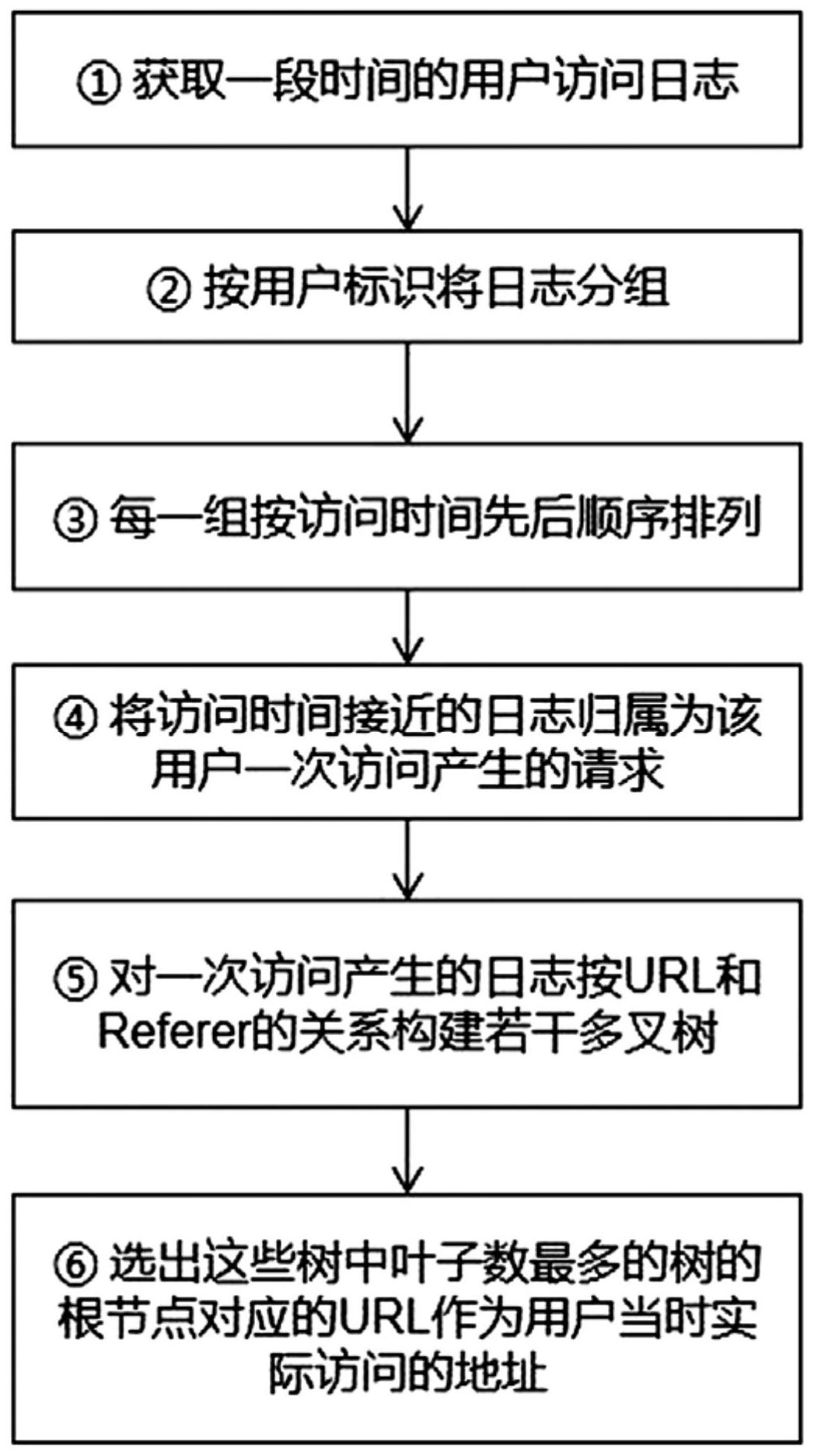
本发明提供了一种用户实际访问网址的识别方法,包括如下步骤:S01、收集服务器上产生的用户日志;S02、按第一特征进行分组;S03、将每一组的用户日志按第二特征进行排序;S04、将已经排好序的每一组用户日志,按第一合并规则合并为若干小组,每一小组内的用户日志归并 全部
背景技术:
随着互联网技术的飞速发展,使用终端接入运营商服务器并访问互联网网站的用 户数量快速增长。通常情况下运营商都需要对所接入用户的上网行为进行审计,而该审计 需要准确的识别出用户实际的访问网址。通常情况下记录用户访问的网址最准确的设备是 用户使用的终端设备的浏览器,但运营商是无法通过简单方法拿到用户使用的终端设备上 的数据的,所以最实际可行的方法是通过用户接入运营商服务器后,通过服务器所产生的 用户访问日志来进行分析,如图1所示。 但实际中,对于用户使用终端设备上的浏览器访问某个互联网网站的某个页面 时,浏览器向网站发出的请求的数量远大于用户在浏览器中输入的或者点击某个链接产生 的那一条请求。通常情况下用户访问一个网站页面,浏览器会发出几十乃至上百条数量不 等的请求给网站服务器,比如用户实际只打开某个新闻页面,而浏览器实际会额外请求若 干张网页上的图片,若干段广告文本,甚至音乐,动画等。对于用户接入的运营商的服务器 (网关代理等),服务器会把每一条请求都记录成一条日志,服务器只是处理记录这些请求, 其本身是无法区分出用户实际访问的那个链接请求的。 基于上述情况,运营商在每时每刻产生的海量访问记录面前,对用户上网行为的 审计将会产生较大偏差,例如某个用户在一小时内只访问了不到10个页面,但被运营商的 网关服务器记录了近1000条请求日志,其中包含了大部分的图片,广告等信息,而这些信息 对审计来说并没有什么价值,用户实际访问的网址被掩埋在大多数没有价值的数据中。所 以相对准确的识别出用户实际访问的网址将对运营商的用户行为审计产生关键的作用。 从海量访问日志中识别出用户实际访问的网址有一些方法,最常见的是过滤合并 方法,例如将访问日志中的URL字段中包含jpeg、mp3、js、css等关键字的日志过滤掉,将剩 下的日志中相邻的且URL字段相同的多条日志合并为一条,将这些日志识别为用户实际访 问的网址。但是,因为非用户实际访问的网址,也就是浏览器根据网页情况自动发送的请 求,这些请求中除了一些可以被简单通过关键字过滤掉的以外,还有很大一部分是和用户 实际访问的网址从结构来看没有区别,无法区分。这种情况下通过简单合并的结果会多出 大量的误报日志,严重影响后续审计的准确性。 还有一种通过大量数据统计的方法,例如,不断的记录访问网站用户的用户名列 表,以及所有被访问的URL的清单,同时也记录两者的对应关系,该方法认为,真正被用户访 问的URL的访问频率会相对较低,当数量足够大时,通过计算URL清单中每个URL被访问的频 率(一段时间内该URL被访问的次数/所有访问过该URL的用户总数),通过人工设定一个经 验阈值,低于该阈值的URL则判定为用户实际访问的网址。这种方法识别的准确性完全依赖 预先统计的数据的数量以及覆盖面,当数据量不够或者覆盖面较小的时候,识别的准确性 依然会大幅下降。同时因为需要预先统计数据,识别的实时性也不能保证。 3 CN 111611508 A 说 明 书 2/4 页
技术实现要素:
为了解决











