
技术摘要:
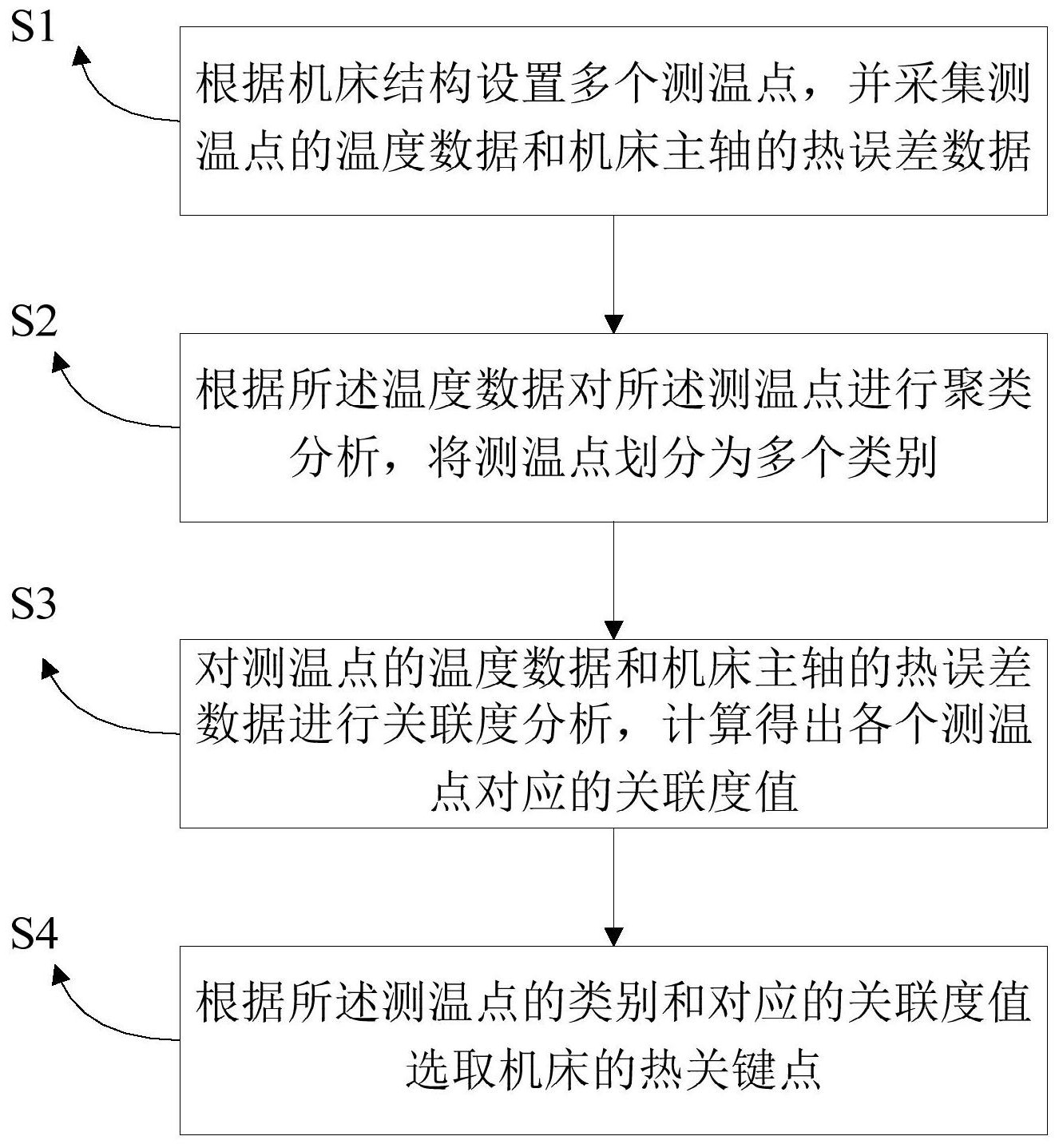
本发明公开了一种机床热关键点选取方法,包括:步骤S1,根据机床结构设置多个测温点,并采集测温点的温度数据和机床主轴的热误差数据;步骤S2,根据所述温度数据对所述测温点进行聚类分析,将测温点划分为多个类别;步骤S3,对测温点的温度数据和机床主轴的热误差数据 全部
背景技术:
随着数控加工逐渐向高速度、高精度方向的迅速发展,对数控机床的加工精度和 可靠性等提出了更高的要求,改善数控机床的热态特性,已经成为机械制造技术发展中最 重要、最迫切的研究课题之一。数控机床的热误差是指在机械加工过程中,由于机床温度升 高导致机床部件变形或膨胀而引起工件和刀具之间的相对位移发生变化。大量研究表明: 热误差是精密加工机床的最大误差源,约占机床总误差的70%左右,而且当对机床加工零 件精度的要求越高时,热误差所占总误差的比重越大。作为影响机床加工精度的主要误差, 热误差严重影响其加工精度。21世纪以来,随着科技的迅猛发展,各支柱产业对机械高端产 品精度要求日益提高。因此,机床热误差的补偿技术成为当前高精度加工亟待解决的问题。 选择合理的热关键点和建立准确、实时热误差预测模型是数控机床热误差补偿的 关键和技术难点。理论上,在建立机床热误差预测模型时,采用的温度测点数越多,模型的 预测结果越精确,补偿实施效果也就越好。但机床温度场具有复杂多变性,各测温点之间存 在不同程度的相关性、耦合性以及共线性问题。若采用过多的温度测点进行热误差预测建 模,不但会增加预测模型的复杂程度,同时由于温度测点之间的共线性,反而还会导致预测 模型精度的下降,而且补偿成本高。同样,若在热误差建模中采用的温度测点数过少,输入 的机床温度场信息不完整,也会降低热误差预测模型精度。目前,通常采用系统聚类分析法 对温度测点进行聚类优化。系统聚类分析法是用特定的数学方法,以某种相似性或者差异 性对样本进行亲疏关系的定量分析,按照分析结果对样本进行聚类。利用该方法可以将相 似的温度测点聚为一类,有效对温度测点进行优化,从而达到减小温度测点的目的。但是, 采用系统聚类分析法选择温度测量仍然存在一些问题,例如,某些温度测点温度曲线之间 虽然距离较大,但是相关性高,归为不同类会造成预测模型存在较大共线性问题,同时也存 在某些温度测点之间虽然相关度较高,但是其温度变化范围小,不宜归为一类的问题,因 此,采用现有的系统聚类分析法难以最优的选取机床热关键点。
技术实现要素:
鉴于以上问题,本发明的目的是提供一种机床热关键点选取方法,以解决现有技 术难以优化选取机床热关键点的问题。 为了实现上述目的,本发明采用以下技术方案: 本发明所述机床热关键点选取方法,包括以下步骤: 步骤S1,根据机床结构设置多个测温点,并采集测温点的温度数据和机床主轴的 热误差数据; 步骤S2,根据所述温度数据对所述测温点进行聚类分析,将测温点划分为多个类 别; 4 CN 111580463 A 说 明 书 2/9 页 步骤S3,对测温点的温度数据和机床主轴的热误差数据进行关联度分析,计算得 出各个测温点对应的关联度值; 步骤S4,根据所述测温点的类别和对应的关联度值选取机床的热关键点。 优选地,所述步骤S2包括: 计算各测温点温度之间的距离系数,得到距离矩阵; 计算各测温点温度之间的相关系数,得到相关系数矩阵; 对所述距离矩阵和所述相关系数矩阵进行归一化处理; 根据归一化处理后的距离矩阵和相关系数矩阵得到聚类距离矩阵; 根据所述聚类距离矩阵对测温点进行聚类,将测温点划分为多个类别。 优选地,所述步骤S2还包括:对所述温度数据进行长度压缩处理。 优选地,通过下式对所述距离矩阵进行归一化处理: 其中,doij表示归一化处理后的距离矩阵元素,dij表示归一化处理前的距离矩阵元 素,dijmin表示归一化处理前的距离矩阵元素中的最小值,dijmax表示归一化处理前的距离矩 阵元素中的最大值; 通过下式对所述相关系数矩阵进行归一化处理: roij=1-|rij| 其中,roij表示归一化处理后的相关系数矩阵元素,rij表示归一化处理前的相关系 数矩阵元素。 优选地,所述聚类距离矩阵通过下式得到: D′=βDo Ro 其中,D′表示聚类距离矩阵,Do表示归一化处理后的距离矩阵,Ro表示归一化处理 后的相关系数矩阵,β表示系数,且0<β<1。 优选地,所述步骤S3包括: 根据机床主轴的热误差数据确定参考数列,并将各测温点的温度数据分别作为比 较数列; 对所述参考数列做归一化处理得到数据序列,对所述比较数列做归一化处理得到 温度数列; 根据所述数据序列和所述温度数列计算得到测温点对应的关联度值。 优选地,通过下式对比较数列做归一化处理得到温度数列: 其中,Toik表示温度数列的第k个元素,Tik表示归一化处理前的比较数列的第k个元 素,m表示比较数列的元素个数; 通过下式对参考数列做归一化处理得到数据序列: 5 CN 111580463 A 说 明 书 3/9 页 其中,xok表示数据序列的第k个元素,xk表示归一化处理前的参考数列的第k个元 素,m表示参考数列的元素个数。 优选地,根据所述数据序列和所述温度数列计算得到测温点对应的关联度值的步 骤包括: 计算所述数据序列对所述温度数列在各个序列点的关联度系数; 将各个序列点的关联度系数求和之后,取平均值作为关联度值。 优选地,所述关联度系数通过下式计算得到: 其中,εoik表示数据序列对温度数列在第k个序列点的关联度系数,i表示测温点的 索引,n表示测温点的数量,xok表示数据序列的第k个元素,Toik表示温度数列的第k个元素,m 表示元素个数,ρ为分辨系数。 优选地,所述步骤S4包括: 将所述关联度值按照从大到小的顺序排列; 在每个类别的测温点中各选取关联度值排序靠前的预设个数个测温点,作为机床 的热关键点。 与现有技术相比,本发明具有以下优点和有益效果: 本发明所述机床热关键点选取方法,通过对机床各测温点进行聚类分析,将测温 点聚类为不同类别,然后采用灰色关联度分析法对主轴热误差数据与各测温点的温度数据 的关联度进行分析计算,最后在各聚类中根据关联度值选取合理热关键点,在减少测温点 数量的同时,又保障了温度信息的完整,避免各测温点之间的耦合效应和多重共线问题,极 大地简化了机床热误差建模过程,提高热误差预测模型的精度以及鲁棒性,在机床主轴热 误差建模预测中具有重要的实用价值。 附图说明 图1本发明所述机床热关键点选取方法的流程示意图; 图2是本发明所述机床热关键点选取方法的实施例的流程示意图; 图3是实施例中机床温度场测量的测温点分布示意图; 图4是实施例中机床主轴热误差测量点的分布示意图; 图5是实施例中机床温度场测量试验所获取的温度变量曲线示意图; 图6是实施例中机床试验所获取的主轴热误差曲线示意图。











