
技术摘要:
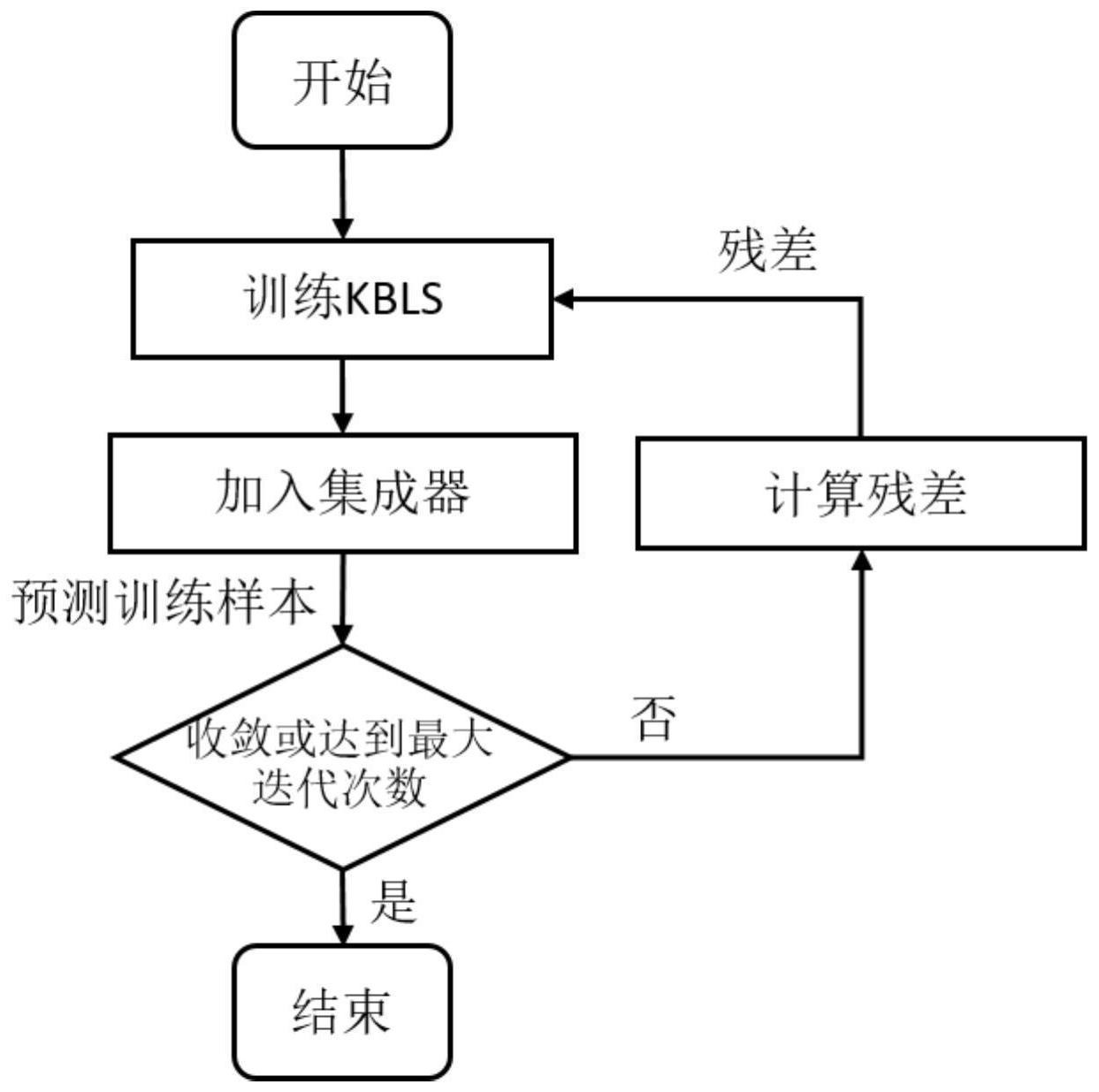
本发明公开了一种基于核宽度学习系统的渐进式集成分类方法,包括步骤:1)输入训练样本和测试样本;2)使用原始训练数据训练一个核宽度学习系统作为基分类器;3)根据第一个基分类器的训练结果计算预测残差,作为下一个基分类器训练的标签;4)当训练的损失函数值降低 全部
背景技术:
随着移动互联网的普及和飞速发展,智慧医疗应运而生。智慧医疗中,包括对生物 基因进行研究和分析的领域,而机器学习可以起到在生物信息中挖掘出潜在模式和特征的 作用。对生物信息进行数据挖掘是一项困难的任务,因为生物基因中包含很多不表达性状 的基因和由于采集技术不够先进而带来的数据噪声,使得一些样本与真实情景下的基因疾 病关联性不匹配,对生物基因的预测和分类造成影响,所以需要更鲁棒并且具有抵抗噪声 能力的机器学习模型。 深度学习算法虽然能提取深层的特征,但由于对数据集规模过度依赖,在数据量 不够大的时候经常会过拟合,而即使数据量足够也需要耗费冗长的训练时间。如何寻找一 种更高效,并且具有噪声抵抗力的模型是生物信息领域的热点问题。
技术实现要素:
本发明的目的在于克服现有技术的不足,提出了一种基于核宽度学习系统的渐进 式集成分类方法,可有效解决特征工程工作过于繁琐的问题,通过伪逆的计算来替代反向 传播求输出权重,提高了训练效率,并且结合了集成学习的方法,在提升核宽度学习系统分 类效果的同时避免陷入局部最优和过拟合,对生物信息中的噪声具有很好的抵抗力。 为实现上述目的,本发明所提供的技术方案为:一种基于核宽度学习系统的渐进 式集成分类方法,包括以下步骤: 1)输入训练样本和测试样本,对样本中的数据进行预处理; 2)训练一个核宽度学习系统(KBLS)作为第一个基分类器; 3)根据第一个基分类器的结果计算残差,其过程如下: 3.1)定义集成器及其损失函数,计算集成器损失函数的梯度; 3.2)求集成器损失函数的次梯度; 3.3)将步骤3.1)和步骤3.2)得到的结果进行结合,计算得到整体的残差; 3.4)将求得的残差作为下一个基分类器训练的标签; 4)计算损失函数值,当损失函数值与上一轮迭代的降低率低于阈值时视为收敛, 停止迭代; 5)使用集成分类器对测试样本进行分类,得到最后的预测结果。 进一步的,在步骤1)中,对生物基因数据进行数据清洗,包括对存在缺失值的数据 进行中值填充或和过滤含大量缺失值的属性,对数据类型进行统一,同时将数据标签转换 为独热编码,方便后续的计算。 进一步的,所述核宽度学习系统为一个两层的神经网络,第一层是特征节点和增 4 CN 111598187 A 说 明 书 2/5 页 强节点层,第二层是输出层,其中特征节点跟增强节点之间全连接,然后又拼接在一起全连 接到输出层。 进一步的,在步骤2)中,使用训练样本 来训练KBLS作为第一个基分类器, 其中N为样本数,具体过程为: 2.1)生成n组随机权重 和偏置项 训练样本的特征通过n组映射生成 特征节点: Zi=[XWi βi],i=1,2,...,n, 其中,Zi代表第i组特征节点,X代表输入的训练样本。所有的特征节点组被连接成 一层,形成特征层: Z=[Z1,Z2,...,Zn]; 2.2)通过径向基核函数(RBF)计算训练样本间的内积矩阵,将特征层映射为增强 节点层: 式中xk,xm分别代表第k个和第m个样本的特征向量,σ为RBF的参数,决定了高斯分 布的形状,计算出来的N*N(此处N与训练样本数N相等)个核距离构成核矩阵Ω,同时也作为 增强节点层; 2.3)通过求伪逆(pseudo inverse)的方式计算特征层到增强层的连接权重: 式中C代表正则项系数; 2.4)将特征层和增强层连接成一层隐含层: A=[Z,Ω], 2.5)输出层权重也通过求伪逆的方式得出,计算公式为: 式中Y代表训练样本的标签矩阵。 进一步的,在步骤3.1)中,定义集成器为: 其中B代表集成器中基分类器的数量,x代表当前训练样本,FB(x)代表前B个基分 类器的综合输出,fb(x)代表第b个基分类器的输出,损失函数为: 其中y代表x的标签,K代表类别数,yk代表y第k维的值(0或1),pk(x)代表第k类的预 测值,由FB(x)经过softmax函数计算得出。第B-1个集成器损失函数的梯度公式为: gB-1=-yt yt·pB-1,t, 式中t表示样本的真实类别,yt表示第t维即真实类别的标签值1,pB-1 ,t表示第B-1 个集成分类器对真实类别的预测值; 进一步的,在步骤3.2)中,求集成器损失函数的次梯度,计算公式为: hB-1=pB-1,t-p 2B-1,t 。 5 CN 111598187 A 说 明 书 3/5 页 进一步的,在步骤3.3)中,用求得的梯度g和次梯度h来计算当前迭代轮数的集成 器训练残差: 进一步的,在步骤3.4)中,将求得的残差作为下一个基分类器训练的标签,则新的 训练样本变成 其中ri,b表示第b个基分类器对第i个样本的预测值残差。 进一步的,在步骤4)中,计算当前迭代轮数损失函数值与上一轮的差值: ΔL=L(y,FB-1(x))-L(y,FB(x)), 当降低率ΔL低于阈值ε,即 时,视为迭代收敛,停止训练。 进一步的,在步骤5)中,使用集成分类器对测试样本进行测试,将初始基分类器和 根据每轮残差训练出来的基分类器的结果进行置信度即预测结果中各类的概率值相加,得 到对每个测试样本分别属于每个类别的概率值。 本发明与现有技术相比,具有下优点与有益效果:如 1、本发明有效解决了现有技术的训练过程冗长问题,降低了人工设计特征成本以 及能抵抗生物信息中噪声的特性,提高了生物基因数据分析效果分类效果。 2、本发明的核宽度学习系统中的隐藏层节点包括对生物信息的线性组合特征和 样本间的核距离特征;线性组合特征相当于对原始的特征进行随机抽样和加权,使单个分 类器具有较大随机性,集成器中各成员具有多样性和高方差;核距离特征将样本的相似性 作为一个度量构成特征,较原版宽度学习系统的随机映射更加合理并且降低了冗余,提高 核宽度学习系统的泛化能力。将多个不同的核宽度学习系统进行渐进式集成,一是有针对 性地在集成器的损失函数梯度和次梯度方向上训练新的基分类器,比单纯的集成总体偏差 更小,并且能根据收敛速度自动确定集成器的规模;二是通过多个基分类器来工决策,降低 核宽度学习系统总体方差,避免陷入局部最优,提高集成器的泛化能力。因为具有这样的特 性,本发明在带噪声的生物基因数据集上具有良好的分类效果。 附图说明 图1为本实施例基于核宽度学习系统的渐进式集成分类方法的流程图。











