
技术摘要:
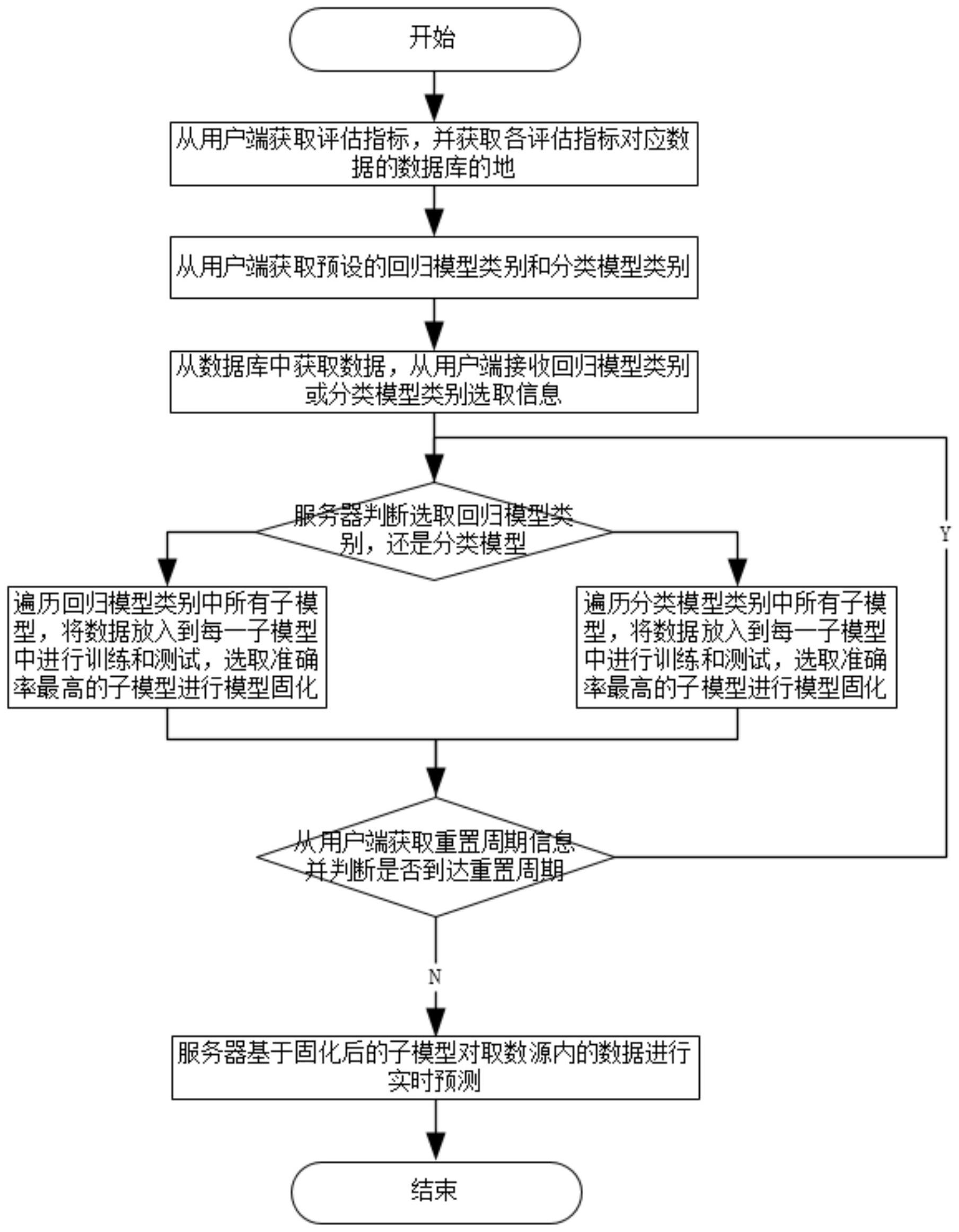
本发明涉及机器学习技术领域,具体公开了基于机器学习的QA辅助决策方法及系统,方法,包括如下步骤:S1、从用户端获取评估指标,并获取数据库的地址;S2、从用户端获取预设的回归模型类别和分类模型类别;S3、从数据库中获取数据,从用户端接收回归模型类别或分类模型 全部
背景技术:
银行中,传统的QA(质量保证)主要依靠评估人员根据经验来设置一定的规则,用 设置的规则对质量管理过程进行评估。这种方式的主要不足是,在需要评估的项目较多时, 由于评估人员的数量有限,通常需要耗费大量的时间;而且由于人的精力有限,在巨大的工 作量下,往往难以保证评估的准确性和稳定性。 随着机器学习相关技术的出现,利用机器学习取代人对质量管理过程等进行评估 成为了可能。机器学习包括数据、算法和算力三个要素,机器学习拥有丰富的算法模型,比 如逻辑回归模型(Logistics Regression)、支持向量机模型(SVM)、神经网络模型(Neural Network)、决策树(Decision Tree)等,这些算法本质是将数据模型化,并利用训练数据来 寻找最优的模型参数,以便准确的表达数据和处理数据。 在实际应用中为了保证评估的准确性,需要选择合适的算法模型;当前的做法通 常是确定一个准确性较高的算法模型后,便一直采用此算法模型进行数据的处理。但是,由 于不同的数据之间存在差异性,同样的算法模块并不能适应所有的数据处理,长期采用同 一个算法模块难以确保评估的准确性和稳定性。 为此,需要一种能提高QA辅助决策准确性和稳定性的方法及系统。
技术实现要素:
本发明提供了基于机器学习的QA辅助决策方法及系统,能够提高准确性和稳定 性。 为了解决上述技术问题,本申请提供如下技术方案: 基于机器学习的QA辅助决策方法,包括如下步骤; S1、服务器从用户端获取评估指标,并获取各评估指标对应数据的数据库的地址; S2、服务器从用户端获取预设的回归模型类别和分类模型类别,回归模型类别和 分类模型类别均包括若干子模型; S3、服务器从数据库中获取数据,从用户端接收回归模型类别或分类模型类别选 取信息; S4、服务器根据选取的回归模型类别或分类模型类别,遍历回归模型类别或分类 模型类别中所有子模型,将数据放入到每一子模型中进行训练和测试,选取准确率最高的 子模型进行模型固化; S5、服务器从用户端获取重置周期信息,在每个重置周期,重复S4; S6、服务器基于固化后的子模型对数据库内的数据进行实时预测。 基础方案原理及有益效果如下: 4 CN 111582498 A 说 明 书 2/5 页 本方案中,先获取回归模型类别或分类模型类别中的一种类别再进行后续操作, 能降低后续训练和测试的规模,节约服务器的计算资源。通过遍历回归模型类别或分类模 型类别中所有子模型,将数据放入到每一子模型中进行训练和测试,能提高子模型选取的 准确性;通过获取重置周期信息,在每个重置周期,重复S4步骤,能有效避免长期采用同一 个子模型带来的稳定性和准确性降低的问题。而且,采用本方案固化后的子模型对数据库 内的数据进行实时预测,能大大提高评估的效率。 进一步,所述S2中,服务器还包括从用户端获取预设回归模型类别和分类模型类 别下各子模型的参数配置。 通过预设参数配置,能使各子模型的针对性更强,以提高预测的准确性。 进一步,所述S1中,所述评估指标包括工作饱和度、缺陷发现率、自动化覆盖率和 缺陷遗漏率中的一种或多种。 对各类型评估指标支持的数量多,在实际QA评估中的适应性更好。 进一步,所述S2中,回归模型类别的子模型包括逻辑回归模型和线性回归模型;分 类模型类型的子模型包括贝叶斯分类模型和决策树分类模型。 提供较多的子模型供训练和测试,有助于选取到准确率最高的子模型。 进一步,所述S1中,数据库包括MYSQL、ES和ORACLE中的一种或多种。 支持的数据库种类多,在实际QA评估中的适应性较好。 进一步,所述S4中,当准确率最高子模型数量大于或等于两个时,获取每一子模型 的资源消耗数据,选择资源消耗最少的子模型进行模型固化。 选择资源消耗最少的子模型进行模型固化,能在保证评估准确率的同时,降低系 统资源消耗。 进一步,基于机器学习的QA辅助决策系统,包括用户端、数据库和服务器; 用户端用于输入评估指标,并设定各评估指标对应数据的数据库的地址;用户端 还用于输入回归模型类别和分类模型类别,回归模型类别和分类模型类别均包括若干子模 型; 数据库用于存储评估指标对应的数据; 用户端还用于输入回归模型类别或分类模型类别的选取信息;服务器用于从数据 库获取数据,基于回归模型类别或分类模型类别的选择信息,遍历回归模型类别或分类模 型类别中所有子模型,将数据放入到每一子模型中进行训练和测试;服务器还用于选取测 试中准确率最高的子模型进行模型固化; 用户端还用于输入重置周期信息,服务器还用于在每个重置周期重新遍历回归模 型类别或分类模型类别中所有子模型,将数据放入到每一子模型中进行训练和测试;并选 取测试中准确率最高的子模型进行模型固化; 服务器还用于将数据库内的数据输入固化的模型内进行实时预测,并输出预测结 果。 本方案中,服务器基于回归模型类别或分类模型类别的选择信息再进行后续操 作,能降低后续训练和测试的规模,节约计算资源。服务器遍历回归模型类别或分类模型类 别中所有子模型,将数据放入到每一子模型中进行训练和测试,能提高子模型选取的准确 性;通过设定重置周期,在每个重置周期,重新遍历子模型进行训练和测试,能有效避免长 5 CN 111582498 A 说 明 书 3/5 页 期采用同一个子模型带来的稳定性和准确性降低的问题。而且,采用本方案中预测模式采 用固化后的子模型对数据库内的数据进行实时预测,能大大提高评估的效率。 进一步,所述用户端还用于输入回归模型类别和分类模型类别下各子模型的参数 配置。 通过输入参数配置,能使各子模型的针对性更强,以提高预测的准确性。 进一步,所述回归模型类别的子模型包括逻辑回归模型和线性回归模型;分类模 型类型的子模型包括贝叶斯分类模型和决策树分类模型。 提供较多的子模型供训练和测试,有助于选取到准确率最高的子模型。 进一步,所述服务器还用于在准确率最高子模型数量大于或等于两个时,获取每 一子模型的资源消耗数据,选择资源消耗最少的子模型进行模型固化。 训练模块通过选择资源消耗最少的子模型进行模型固化,能在保证评估准确率的 同时,降低系统资源消耗。 附图说明 图1为实施例一基于机器学习的QA辅助决策方法的流程图。











