
技术摘要:
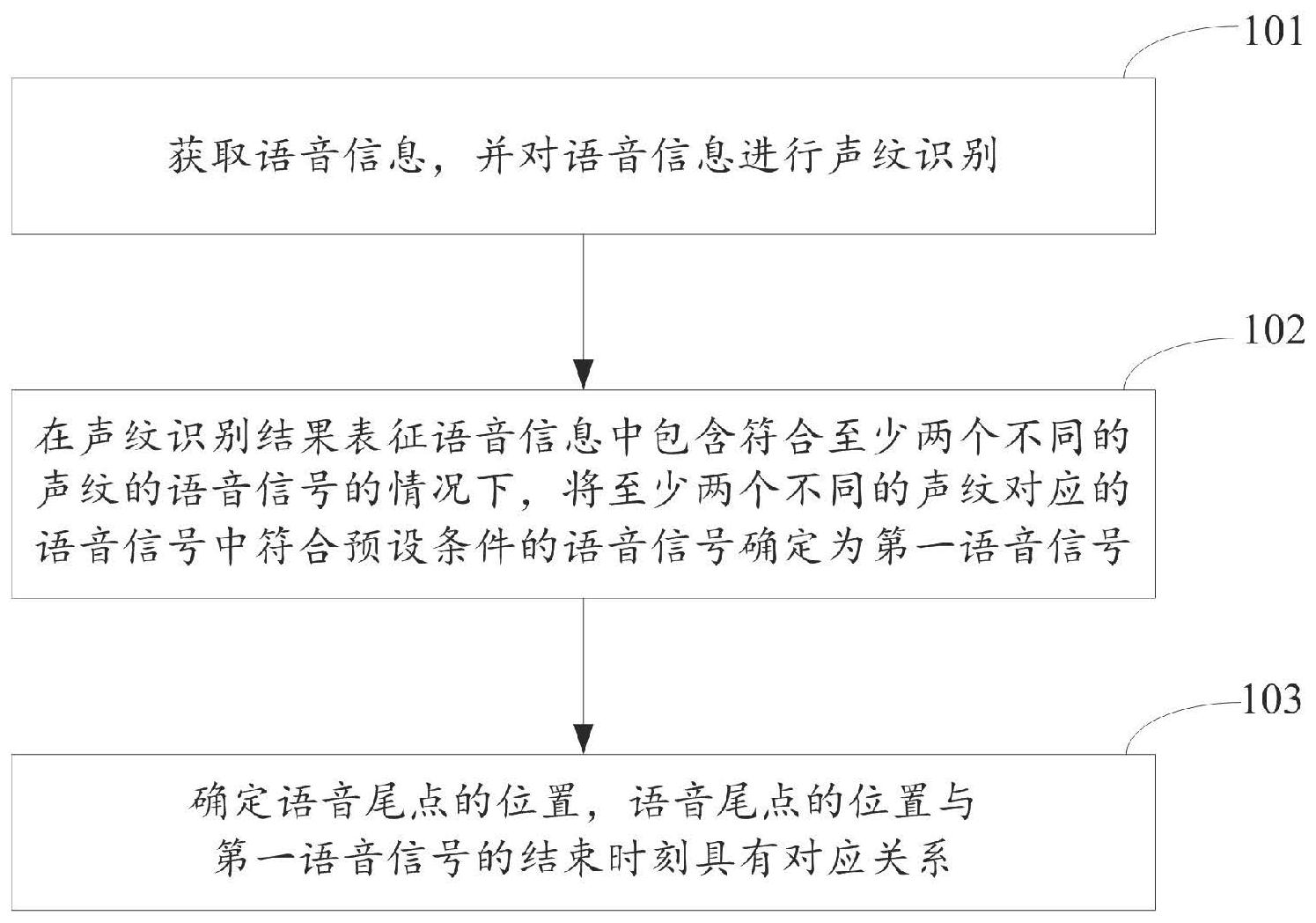
本申请公开了一种数据处理方法及装置,方法包括:获取语音信息,并对所述语音信息进行声纹识别;在所述声纹识别结果表征所述语音信息中包含符合至少两个不同的声纹的语音信号的情况下,将所述至少两个不同的声纹对应的语音信号中符合预设条件的语音信号确定为第一语音 全部
背景技术:
目前许多的电子设备都具备语音识别技术,以为用户提供更加方便的语音服务。 当前的语音识别技术中,基于自然语言识别来确定语音尾点,这种实现方式在环境中存在 多个人的声音,或在环境存在干扰声音的情况下,就会出现语音尾点的识别错误,影响语音 识别的准确率。
技术实现要素:
有鉴于此,本申请提供如下技术方案: 一种数据处理方法,包括: 获取语音信息,并对所述语音信息进行声纹识别; 在所述声纹识别结果表征所述语音信息中包含符合至少两个不同的声纹的语音 信号的情况下,将所述至少两个不同的声纹对应的语音信号中符合预设条件的语音信号确 定为第一语音信号; 确定语音尾点的位置,所述语音尾点的位置与所述第一语音信号的结束时刻具有 对应关系。 可选的,将所述至少两个不同的声纹对应的语音信号中符合预设条件的语音信号 确定为第一语音信号,包括: 将所述至少两个不同的声纹对应的语音信号中出现时间最早的语音信号或对应 声纹与设定声纹匹配的语音信号确定为第一语音信号。 可选的,所述确定语音尾点的位置,包括: 将所述第一语音信号的结束时刻对应位置确定为语音尾点的位置;或, 将所述第一语音信号的结束时刻后按照第一规则确认的位置确定为语音尾点的 位置。 可选的,在确定语音尾点的位置后,还包括: 将所述语音尾点前的语音段中除第一语音信号之外的语音信号删除和/或做静音 处理,所述静音处理包括滤波处理。 可选的,所述将所述语音尾点前的语音段中除第一语音信号之外的语音信号删除 和/或做静音处理,包括: 将所述语音尾点前的语音段中,与所述第一语音信号在时间维度上存在叠加的其 他语音信号做滤波处理;和/或与所述第一语音信号在时间维度上不存在叠加的其他语音 信号删除。 可选的,在所述将所述语音尾点前的语音段中除第一语音信号之外的语音信号删 4 CN 111583934 A 说 明 书 2/9 页 除和/或做静音处理后,还包括: 对处理后的语音段中的所述第一语音信号进行语义识别。 可选的,还包括: 在获取语音信息的过程中,实时的对获取的所述语音信息进行声纹识别。 可选的,还包括: 获取第一用户的声纹作为设定声纹。 可选的,在所述获取语音信息前,还包括: 获取语音采集指令; 对所述语音采集指令进行声纹识别,将所述语音采集指令对应的声纹确定为设定 声纹。 本申请还公开了一种数据处理装置,包括: 语音处理模块,用于获取语音信息,并对所述语音信息进行声纹识别; 语音确定模块,用于在所述声纹识别结果表征所述语音信息中包含符合至少两个 不同的声纹的语音信号的情况下,将所述至少两个不同的声纹对应的语音信号中符合预设 条件的语音信号确定为第一语音信号; 尾点确定模块,用于确定语音尾点的位置,所述语音尾点的位置与所述第一语音 信号的结束时刻具有对应关系。 经由上述的技术方案可知,与现有技术相比,本申请实施例公开了一种数据处理 方法及装置,方法包括:获取语音信息,并对所述语音信息进行声纹识别;在所述声纹识别 结果表征所述语音信息中包含符合至少两个不同的声纹的语音信号的情况下,将所述至少 两个不同的声纹对应的语音信号中符合预设条件的语音信号确定为第一语音信号;确定语 音尾点的位置,所述语音尾点的位置与所述第一语音信号的结束时刻具有对应关系。所述 数据处理方法及装置会对采集到的语音信息进行声纹识别,依据一定条件确定出语音信息 中的有效语音信号,进而根据有效语音信号的结束时刻确定语音尾点,从而能够屏蔽掉语 音尾点后与正确控制指令无关的语音信号,有助于提升语音识别的准确率。 附图说明 为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现 有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本 申请的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据 提供的附图获得其他的附图。 图1为本申请实施例公开的一种数据处理方法的流程图; 图2为本申请实施例公开的两种声纹对应的语音信号示意图; 图3为本申请实施例公开的第二种数据处理方法的流程图; 图4为本申请实施例公开的两段第一语音信号间存在其他语音信号的示意图; 图5为图4所示语音信号处理后的语音信号示意图; 图6为本申请实施例公开的第三种数据处理方法的流程图; 图7为本申请实施例公开的第四种数据处理方法的流程图; 图8为本申请实施例公开的一种数据处理装置的结构示意图。 5 CN 111583934 A 说 明 书 3/9 页











