
技术摘要:
本发明公开了一种基于YOLOv3优化算法的交通灯检测方法,结合k‑means算法与标签统计的结果确定先验框,再通过简化的网络提取图像的特征,利用高斯分布特性增加对边界框准确度的判断。与原始的YOLOv3检测方法相比,本文提出的方法具有更优的检测速度和精度。本文采用BDD 全部
背景技术:
随着计算机视觉相关技术的不断突破与创新,目标检测算法在自动驾驶领域取得 了重大进展,行人、车辆、道路线等各类道路目标检测算法应运而生。交通灯是室外场景语 义视觉定位的重要标识物,同时交通灯对于辅助自动驾驶及构建高精度地图有着重要意 义。 2009年De等基于点光源的检测算法,研究了一种车载摄像头实时交通灯识别系 统。2012年Siogkas等结合颜色预处理模块,利用快速径向对称变换检测交通灯。2016年清 华大学张长水等采用自适应背景抑制算法研究了光照对交通灯检测的影响。传统基于颜色 的交通灯检测方法易受到光照、车辆尾灯等影响。深度卷积神经网络由于能够自主完成对 目标特征的学习,提取关键信息,因而具有较强的鲁棒性。近年来,主要利用目标候选框思 想和回归思想基于卷积神经网络构成目标检测算法。R-CNN、Fast R-CNN、Faster R-CNN等 基于目标候选框思想的Two-stage检测算法,首先提取目标候选框,再利用检测网络在目标 候选框的基础上完成模型训练。SSD、YOLO、YOLOv3等One-stage检测算法基于回归思想,摒 弃了提取目标候选框的步骤,直接利用检测网络产生目标的类别和位置信息,拥有更高的 检测速度。
技术实现要素:
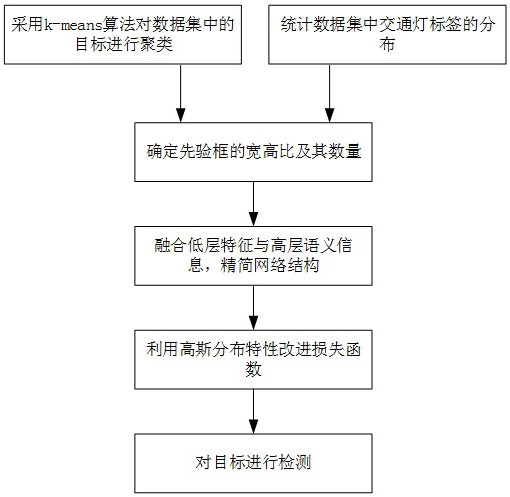
为解决上述问题,本发明公开了一种基于YOLOv3优化算法的交通灯检测方法,简 化了特征提取步骤,避免了随着网络的加深而导致的交通灯特征消失问题,增加了对边界 框可靠性的判断,相较于YOLOv3原始算法,可以有效提升交通灯的检测速度和精度。 为达到上述目的,本发明的技术方案如下: 一种基于YOLOv3优化算法的交通灯检测方法,首先采用k-means算法对数据集进 行聚类,结合聚类结果和对交通灯标签的统计,确定先验框的宽高比及其数量;然后,根据 交通灯尺寸特点,精简网络结构,分别将8倍降采样信息、16倍降采样信息与高层语义信息 进行融合,在两个尺度上建立特征目标检测层;同时,为了避免随着网络加深而产生的交通 灯特征消失问题,分别减少两个目标检测层前的两组卷积层,简化特征提取步骤;最后,在 损失函数中利用高斯分布特性增加对边界框准确度的判断。 步骤1.YOLOv3检测理论 YOLOv3将图像划分成S×S的网格,目标中心所在的网格负责完成对目标的预测。 为完成对C类目标的检测,每个网格需要预测B个边界框及C个条件类别概率,并输出表征边 界框中是否包含目标及输出边界框准确度的置信度信息。每个边界框对应的类别置信度计 算方法如下所示: 5 CN 111553201 A 说 明 书 2/5 页 式中,如果网格包含目标,也即目标的中心落在网格内,则Pr(object)的取值为1, 否则为0。 表示预测边界框与真实边界框的交并比。每个边界框属于某一类别的详 细置信度信息由每个边界框的类别置信度与条件类别概率的乘积构成,计算方法如下所 示: 式中,i=1,2,…,C. 预测得到的边界框中心坐标为(x0,y0),边界框的宽为w0,高为h0。为了增加网络的 收敛速度,对边界框的中心坐标、宽和高参数进行归一化处理,计算公式如下所示: 式中,(xc,yc)代表中心点所在的网格坐标;(wimg,himg)代表图像的宽度和高度;s代 表网格的列数或行数。根据每个网格的输出,计算得到网络的输出大小为S×S×(5×B C)。 步骤2.数据集标签聚类 先验框用来预测边界框偏移的参考框,具有固定的宽高值。先验框选择的优劣对 最终的检测结果有直接的影响。 本发明采用平均交并比(Avg IOU)作为度量标签相似性的指标,避免了由标签尺 寸大小在聚类过程中引入的误差,距离公式可表示为: d(box,centroid)=1-AvgIOU(box,centroid) (4) 本发明定义d(box,centriod)为标签到聚类中心的距离,AvgIOU(box,centroid) 代表标签和聚类中心的交并比。 对数据集中的交通灯标签进行聚类分析,从1开始不断增加聚类中心的个数,得到 聚类中心数量k与AvgIOU之间的关系。为了设置与交通灯的尺寸以及比例相匹配的先验框, 对数据集中的标签分布情况进行统计,得到目标标签的分布情况。本发明通过K-means算法 完成对被检目标尺寸的维度聚类分析,并结合对标签的统计结果确定先验框的参数,以减 少训练过程中的匹配误差。 步骤3.网络结构优化 首先将图像统一缩放到3通道分辨率为672×672像素的形式,再利用Darknet-53 提取交通灯目标的特征,交替使用3×3和1×1大小的卷积核进行运算,为得到更适合检测 交通灯目标的深度卷积神经网络,精简原始YOLOv3网络,并融合大特征图的细节信息和小 特征图的语义信息,在两个尺度上训练出最终的交通灯目检测模型。具体步骤如下: 步骤3.1、使用交替的1×1和3×3的卷积核,得到是原始图像1/8尺寸的特征图M1; 步骤3.2、在特征图M1后交替使用1×1和3×3的卷积核,降采样到其1/2,得到是原 始图像1/16尺寸的特征图M2; 步骤3.3、在特征图M2后交替使用1×1和3×3的卷积核,降采样到其1/2,得到是原 6 CN 111553201 A 说 明 书 3/5 页 始图像1/32尺寸的特征图M3; 步骤3.4、将特征图M3与M2通过1×1和3×3的卷积核进行特征融合,建立第一层目 标检测层; 步骤3.5、将特征图M3与M1通过1×1和3×3的卷积核进行特征融合,建立第二层目 标检测层; 步骤3.6、将先验框分别放到两个目标检测层,用于训练所述卷积神经网络。 步骤4.利用高斯分布优化损失函数 本发明在YOLOv3损失函数中利用高斯分布特性增加对每个检测框不确定性的判 断,以提升网络的精度。YOLOv3算法的损失函数的设计主要从边界框坐标预测误差、边界框 的置信度误差、分类预测误差这三个方面进行考虑。YOLOv3损失函数公式可表示为: 式中,S表示图像的网格数,B表示每个网格中预测的边界框数,C表示总类别数,P 表示目标属于某一类别的概率,c=0,1,…C为类别序号,C=0,1,…S2为网格序号,j=0, 1,…B为边框序号;xi表示属于第i个网格的边界框中心点的横坐标,yi表示属于第i个网格 的边界框中心点的纵坐标,wi表示属于第i个网格的边界框的宽度,hi表示属于第i个网格的 边界框的高度,λcoord为权重系数,λnoobj为惩罚权重系数。 表示第i个网格的第j个边界框 是否负责预测这个目标,取值为0或1。 本发明受Gaussian YOLOv3的启发,利用高斯分布特性改进损失函数,增加对交通 灯边界框可靠性的判断,以边界框中心点x方向坐标为例,修改后的边界框x坐标预测误差 计算方法如下所示: 式中,tx表示边界框的中心坐标相对于网格左上角x坐标的偏移量,W和H分别对应 预测层中网格的数目,k对应先验框的数目, 表示输出层第(i,j)个网格中第k个先 验框的tx的均值, 表示对应的tx的不确定性。 表示tx的真值,γijk表示权重参 数。 本发明的有益效果是: 7 CN 111553201 A 说 明 书 4/5 页 本发明提出一种基于YOLOv3优化算法的交通灯检测方法,与传统的YOLOv3算法相 比,本发明提到的交通灯检测方法在兼具检测速度的同时,可以提高检测精度;本发明提出 的方法可以将平均精准率提高9%;对于提高交通灯检测的精度和速度对于自动驾驶车辆 的安全行驶具有重要意义。 附图说明 图1是基于YOLOv3优化算法的交通灯检测方法的流程图; 图2是目标标签分布统计图; 图3是聚类分析结果图; 图4是YOLOv3优化算法网络结构图; 图5是YOLOv3优化算法平均损失函数及平均交并比曲线; 图6是YOLOv3网络的AP曲线; 图7是YOLOv3优化网络的AP曲线; 图8是不同场景和目标尺寸下网络的平均精准度对比图; 图9是不同场景和目标尺寸下网络的检测结果对比图。











