
技术摘要:
本发明提供了一种面向医疗领域的中文智能问答短文本相似度计算方法,涉及自然语言处理与智能问答领域。该方法针对中文医疗领域,采用SH‑CNN对用户输入的问句与智能问答系统中预设定的问题模板进行向量化,然后提取出两文本中的突出特征进行相似度计算,再结合TF‑IDF 全部
背景技术:
一直以来,医疗健康问题都是社会关注的焦点。由于我国人口众多,地区发展不平 衡,不可避免地导致医疗资源总量不足,部分地区医疗资源分配不合理,现有医疗条件难以 满足病患医疗需求的问题。在人工智能时代,人们希望能像科幻电影中一样,通过人机交互 的方式就能了解到自己的健康状况,实现简单的自我诊疗。智能问答的出现为上述问题提 供了解决方法——智能问答系统通过对用户输入的自然语言问题进行分析理解,获取用户 的搜索意图,并精确定位用户所需的提问知识,从而返回快速简洁的答案。然而,面向中文 医疗领域的智能问答系统的研究还处于初步发展阶段,其中存在的一个大的挑战在于如何 理解问答系统中用户输入的自然语言问句。模板匹配作为问答系统中的常用算法,可通过 计算用户提出的问句与系统中预设定的问题模板间的相似度来确定用户意图。 但这样做的难点在于中文的表达复杂多变,同一类的问句可以表现为不同的形 式,使得计算机难以区分。另一方面,由于用户输入的问句文本较短,导致个别噪音词语会 对整个文本的解析带来新的挑战。系统中包含的知识来源于结构化的知识图谱,只有当为 用户提出的问句匹配符合语义的问题模板时,系统才能返回准确的答案给用户。因此,设计 一个合理高效的短文本相似度算法是系统开发者必须考虑的问题。 现有的短文本相似度计算方法主要分为两类: (1)基于非深度学习的短文本相似度计算方法,分为两种。第一种是基于字面匹配 的方法,通过比较两句子中的每个单词是否相等来进行计算,比如TF-IDF、simhash等。第二 种是基于语义匹配的方法,计算方法一般是余弦相似度。 (2)基于深度学习的短文本相似度计算方法,主要是利用深度网络提取特征,计算 句子之间的匹配度,或者挖掘句子之间不同单词的匹配关系。 以上无论哪种方案,都可以计算短文本相似度,同时也都存在各自的缺点: (1)基于非深度学习的短文本相似度算法更侧重于文本本身的相似度,只考虑到 句子的表层信息,在计算过程中缺少对文本内容的预处理,不可避免的存在一些缺陷。 (2)基于深度学习的短文本相似度算法需要大量数据来训练神经网络,对大型数 据集的依赖程度很大,而面向中文医疗领域并没有合适的语料训练集。同时,一些深度模型 需要很长的时间来训练,大量的网络参数使得整个模型的训练性能难以提升。 虽然基于深度学习的方法被广泛应用于自然语言处理任务,并取得了优异的成 绩,但依靠少量的领域训练集难以训练出高性能的神经网络。因此我们需要结合传统的文 本相似度融合算法,从不同角度理解中文文本的语义信息,从而计算文本相似度。 4 CN 111581364 A 说 明 书 2/9 页
技术实现要素:
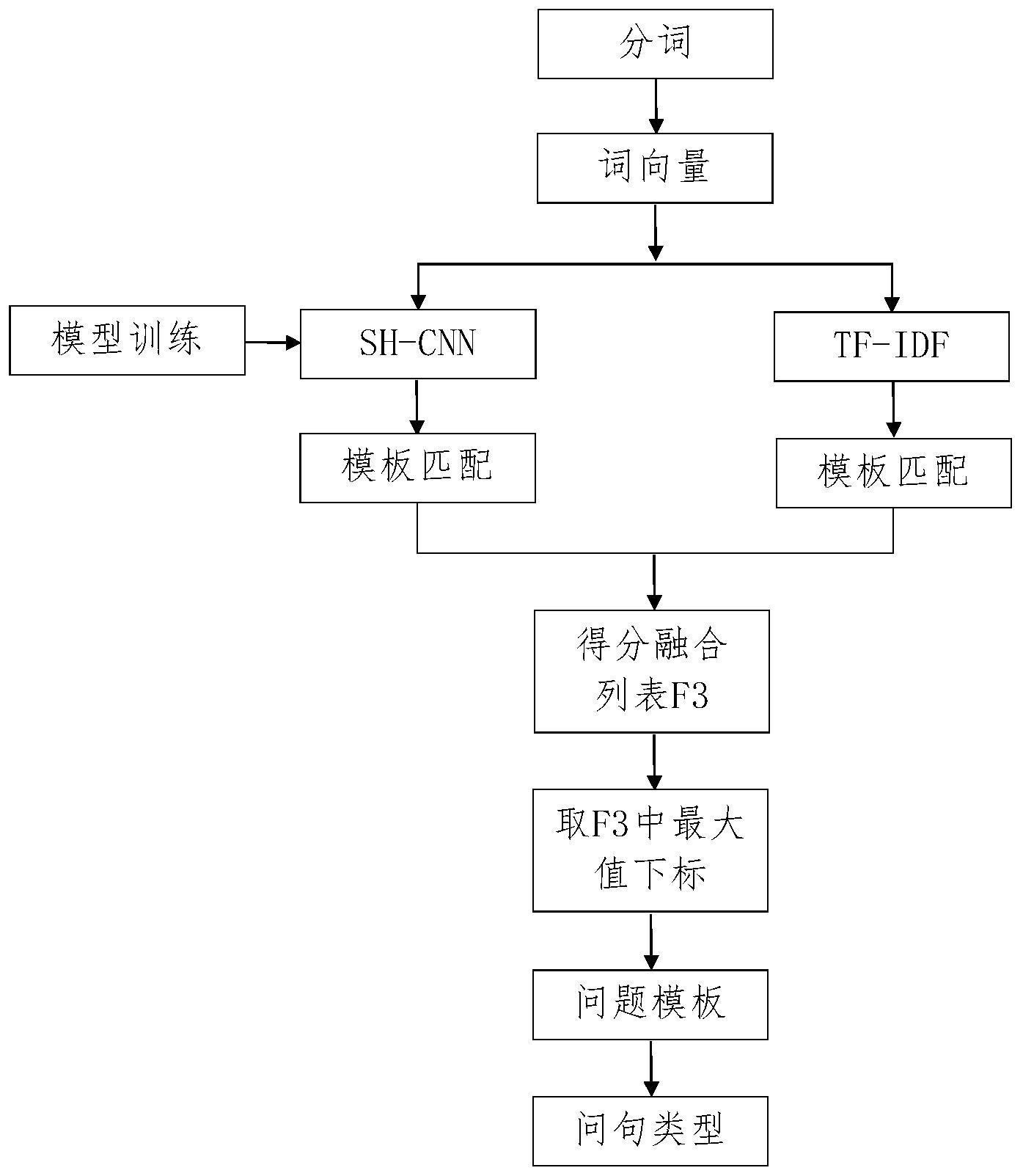
本发明为了缓解当前医疗资源紧缺,面向中文医疗领域的智能问答系统不能准确 理解用户意图的问题,提出一种智能问答短文本相似度计算方法,该方法针对中文医疗领 域并依此构建了智能问答系统,通过将用户输入的自然语言问句与系统中预设定的问题模 板进行相似度计算,获得最贴近用户输入问句语义的问题模板,从而达到准确理解用户输 入问句的目的 本发明使用到的一些缩略词释义如下: SH-CNN:基于共享层的卷积神经网络; TF-IDF:termfrequency-inverse document frequency,词频-逆文本频率指数。 本发明提供一种面向医疗领域的中文智能问答短文本相似度计算方法,融合SH- CNN和TF-IDF技术,来计算用户输入问句和系统问题模板之间的文本相似度,包括以下步 骤: 步骤P1,文本预处理:将训练SH-CNN模型的问句语料进行分词,对分词结果中出现 的所有单词建立一个词典V,并将每个单词都编码一个唯一的索引号;将问句语料中的每个 句子都加长到最大句子的长度,再将每个句子都转换成词向量矩阵; 步骤P2,将问句语料中包含的所有问题对的词向量矩阵分批依次输入SH-CNN中, 获得训练后的SH-CNN模型; 步骤P3,将用户输入问句和系统中所有问题模板进行分词,得到的每个单词均从 步骤P1生成的词典V中取出唯一的索引号,再将包含单词索引号的每个句子都加长到最大 句子的长度,然后将每个句子都转换成词向量矩阵,获得用户输入问句的词向量矩阵和系 统中所有问题模板的词向量矩阵; 步骤P4,将所述用户输入问句的词向量矩阵,每次结合一个问题模板的词向量矩 阵,依次输入所述训练后的SH-CNN模型,计算用户输入问句与每个问题模板之间的文本相 似度,获得列表L1; 步骤P5,为每个问题模板设置一个文件,所述问题模板和所述文件一一对应;所述 文件包含其对应模板中出现的一些重要单词及包含这些重要单词的短语或短句,同时剔除 一些对于确定问句类型没有帮助的单词,相当于对这些重要单词进行加权处理;然后利用 TF-IDF加权技术计算用户输入问句与每个问题模板之间的文本相似度,获得列表L2; 步骤P6,将步骤P4、P5中获得的列表L1、L2中的值相加,获取文本相似度融合列表 L3;根据L3中最大值所对应问题模板的问题类型,确定用户输入问句的问题类型。 优选地,步骤P1中,利用中文分词工具jieba对训练SH-CNN模型的问句语料进行分 词;步骤P3中,利用中文分词工具jieba对用户输入问句和系统中所有问题模板进行分词。 优选地,步骤P3中,所述将每个句子都加长到最大句子的长度,其中,句子的被加 长部分使用字符“











