
技术摘要:
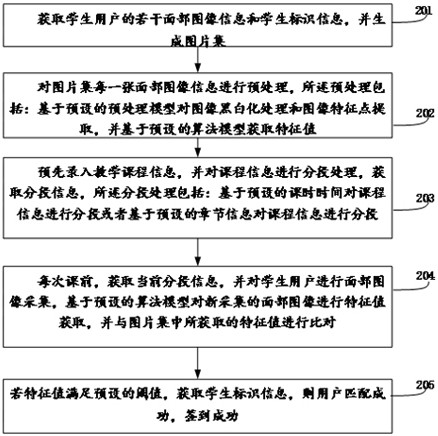
本申请实施例公开了一种基于图像识别的学生课堂签到方法、装置、设备及存储介质,属于数据服务技术领域,该方法包括:获取学生用户的若干面部图像信息和学生标识信息,并生成图片集;对图片集每一张面部图像信息进行预处理;预先录入教学课程信息,并对课程信息进行分段 全部
背景技术:
学生课前签到是上课前确定学生是否来到授课地点的一种传统方法,目前,生活 中最常用的签到方法分别为教师进行课前点名的方式。 近几年,由于互联网技术的快速发展,各大公司常用的签到打卡方法主流的方法 转变为了指纹验证进行打卡。但是,这种指纹打卡的方式,又不适用学生课前打卡操作,大 学班级的人数或者同时听讲一节课的人数可能会达到60人到200人不等,显然,学生依次进 行指纹打卡进行签到,不能满足实际的需求。由此可知,现有技术中教师上课时依靠传统的 签到方法进行点名签到,消耗大量时间的问题。
技术实现要素:
本申请实施例的目的在于提出一种基于图像识别的学生课堂签到方法、装置、设 备及存储介质,以解决现有技术中教师上课时依靠传统的签到方法进行点名签到,消耗大 量时间的问题。 为了解决上述技术问题,本申请实施例提供一种基于图像识别的学生课堂签到方 法,采用了如下所述的技术方案: 一种基于图像识别的学生课堂签到方法,包括: 获取学生用户的若干面部图像信息和学生标识信息,并生成图片集; 对图片集每一张面部图像信息进行预处理,所述预处理包括:基于预设的预处理模型 对图像黑白化处理和图像特征点提取,并基于预设的算法模型获取特征值; 预先录入教学课程信息,并对课程信息进行分段处理,获取分段信息,所述分段处理包 括:基于预设的课时时间对课程信息进行分段或者基于预设的章节信息对课程信息进行分 段; 每次课前,获取当前分段信息,并对学生用户进行面部图像采集,基于预设的算法模型 对新采集的面部图像进行特征值获取,并与图片集中所获取的特征值进行比对; 若特征值满足预设的阈值,获取学生标识信息,则用户匹配成功,签到成功。 进一步的,所述基于图像识别的学生课堂签到方法,所述获取学生用户的若干面 部图像信息和学生标识信息,并生成图片集包括: 获取n张面部正面图像和m张面部侧面图像,其中,n和m分别为正整数,且n与m的和值为 图片集中面部图像的总张数; 获取用户的姓名信息,并将所述姓名信息作为图片集的名称。 进一步的,所述基于图像识别的学生课堂签到方法,所述基于预设的预处理模型 对图像黑白化处理和图像特征点提取包括: 4 CN 111582143 A 说 明 书 2/9 页 通过加权的方式先对图像进行黑白化处理,再对经过黑白化处理后的图像获取若干特 征点; 所述的特征点在正面面部图像上使用(X、Y)坐标进行表示,在侧面面部图像上使用(Y、 Z)坐标进行表示,对不同的特征点进行标识区别,确定不同的特征点的(X、Y、Z)坐标,其中, 在进行坐标表示时,以像素单位作为坐标的1个坐标单位。 进一步的,所述基于图像识别的学生课堂签到方法,所述基于预设的算法模型获 取特征值包括: 预设特定的特征点作为原特征点,分别获取其他不同特征点与原特征点的向量值,生 成向量值集,作为特征值。 进一步的,所述基于图像识别的学生课堂签到方法,所述对学生用户进行面部图 像采集包括: 基于预设的拍照方式获取学生用户的面部图像信息,所述预设的拍照方式包括:正面 和侧面同时拍照,并分别获取一张正面面部图像和一张侧面面部图像。 进一步的,所述基于图像识别的学生课堂签到方法,所述基于预设的算法模型对 新采集的面部图像进行特征值获取,并与图片集中所获取的特征值进行比对包括: 通过加权的方式先对新获取的正面图像和侧面图像分别进行黑白化处理,再对经过黑 白化处理后的正面图像和侧面图像分别获取若干特征点; 对正面图像上的若干特征点使用(X、Y)坐标进行表示,对侧面图像上的若干特征点使 用(Y、Z)坐标进行表示,确定不同的特征点的(X、Y、Z)坐标,其中,在进行坐标表示时,以像 素单位作为坐标的1个坐标单位; 预设特定的特征点作为原特征点,分别获取其他不同特征点与原特征点的向量值,生 成向量值集,作为新面部图像的特征值; 将新面部图像的特征值与图片集中获取的特征值进行对比。 进一步的,所述基于图像识别的学生课堂签到方法,所述若特征值满足预设的阈 值,获取学生标识信息,则用户匹配成功,签到成功包括: 将新面部图像的特征值与图片集中获取的特征值的对比结果,使用百分比的方式进行 表示,若满足预设的百分比,则基于图片集的名称,获取学生的姓名信息,进行签到。 为了解决上述技术问题,本申请实施例还提供了一种基于图像识别的学生课堂签 到装置,采用了如下所述的技术方案: 一种基于图像识别的学生课堂签到装置,包括: 图片集获取模块,用于获取学生用户的若干面部图像信息和学生标识信息,并生成图 片集; 图片处理模块,用于对图片集每一张面部图像信息进行预处理,所述预处理包括:基于 预设的预处理模型对图像黑白化处理和图像特征点提取,并基于预设的算法模型获取特征 值; 课程信息处理模块,用于预先录入教学课程信息,并对课程信息进行分段处理,获取分 段信息,所述分段处理包括:基于预设的课时时间对课程信息进行分段或者基于预设的章 节信息对课程信息进行分段; 图片采集模块,用于每次课前,获取当前分段信息,并对学生用户进行面部图像采集, 5 CN 111582143 A 说 明 书 3/9 页 基于预设的算法模型对新采集的面部图像进行特征值获取,并与图片集中所获取的特征值 进行比对; 匹配签到模块,用于若特征值满足预设的阈值,获取学生标识信息,则用户匹配成功, 签到成功。 为了解决上述技术问题,本申请实施例还提供一种计算机设备,采用了如下所述 的技术方案: 一种计算机设备,包括存储器和处理器,所述存储器中存储有计算机程序,所述处理器 执行所述计算机程序时实现本申请实施例中提出的一种基于图像识别的学生课堂签到方 法的步骤。 为了解决上述技术问题,本申请实施例还提供一种非易失性计算机可读存储介 质,采用了如下所述的技术方案: 一种非易失性计算机可读存储介质,计算机可读存储介质上存储有计算机程序,所述 计算机程序被处理器执行时实现本申请实施例中提出的一种基于图像识别的学生课堂签 到方法的步骤。 与现有技术相比,本申请实施例主要有以下有益效果: 本申请实施例公开了基于图像识别的学生课堂签到方法、装置、设备及存储介质,通过 获取学生用户的若干面部图像信息和学生标识信息,并生成图片集;对图片集每一张面部 图像信息进行预处理,所述预处理包括:基于预设的预处理模型对图像黑白化处理和图像 特征点提取,并基于预设的算法模型获取特征值;预先录入教学课程信息,并对课程信息进 行分段处理,获取分段信息,所述分段处理包括:基于预设的课时时间对课程信息进行分段 或者基于预设的章节信息对课程信息进行分段;每次课前,获取当前分段信息,并对学生用 户进行面部图像采集,基于预设的算法模型对新采集的面部图像进行特征值获取,并与图 片集中所获取的特征值进行比对;若特征值满足预设的阈值,获取学生标识信息,则用户匹 配成功,签到成功。既方便学生用户在上课前进行网上签到,也节省了大量时间。 附图说明 为了更清楚地说明本申请中的方案,下面将对本申请实施例描述中所需要使用的 附图作一个简单介绍,显而易见地,下面描述中的附图是本申请的一些实施例,对于本领域 普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。 图1为本申请实施例可以应用于其中的示例性系统架构图; 图2为本申请实施例中所述基于图像识别的学生课堂签到方法的一个实施例的流程 图; 图3为本申请实施例中所述基于图像识别的学生课堂签到装置的一个实施例的结构示 意图; 图4为本申请实施例中图片集获取模块的结构示意图; 图5为本申请实施例中图片处理模块的结构示意图; 图6为本申请实施例中计算机设备的一个实施例的结构示意图。 6 CN 111582143 A 说 明 书 4/9 页











