
技术摘要:
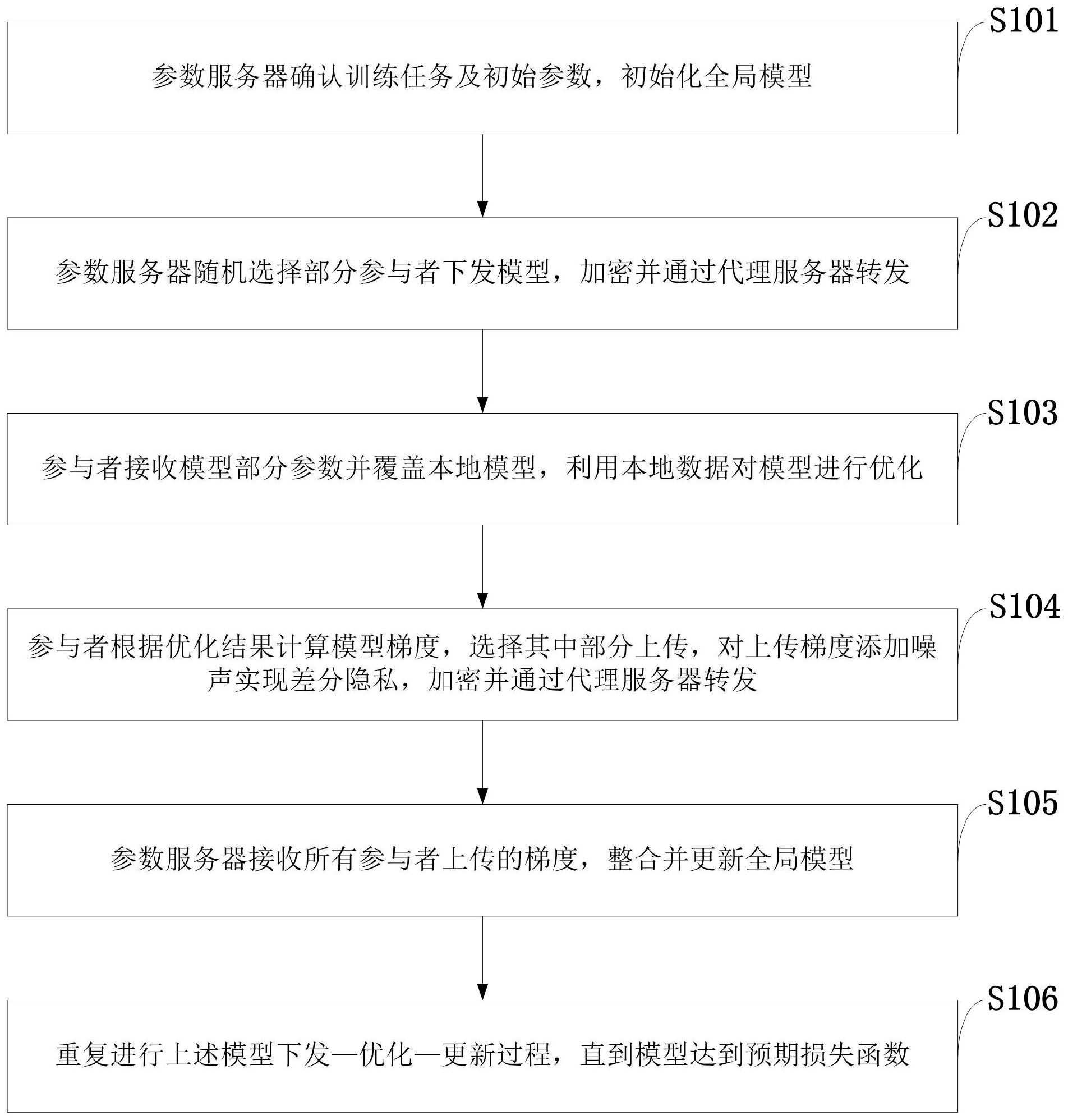
本发明属于无线通信网络技术领域,公开了一种联邦学习信息处理方法、系统、存储介质、程序、终端,参数服务器确认训练任务及初始参数,并初始化全局模型;参数服务器随机选择部分参与者下发模型参数,加密并通过代理服务器转发;参与者接受模型部分参数并覆盖本地模型 全部
背景技术:
目前,随着物联网,大数据和5G网络架构的快速发展和广泛应用,网络边缘设备生 成的海量数据和实时服务需求已远远超过了传统云计算模型的能力,边缘计算将云服务扩 展到网络边缘,具有低延迟,较小的带宽和隐私保护的优势。边缘计算充分利用了大量分布 式边缘节点的计算能力,从而降低了云数据中心的计算压力,但是,边缘节点的管理也更加 复杂,一些安全性较差的边缘节点可能会受到入侵者的恶意攻击,此外网络边缘的用户或 设备生成的数据可能包含用户的隐私数据,例如位置信息,身体状况和活动记录。为了充分 利用边缘数据,基于人工智能的方法挖掘数据信息,发现新的模式和知识,以提取新的和有 价值的信息,但是,直接在多个边缘节点之间共享私有数据可能会导致很大的隐私泄露风 险。 联邦学习(Federated Learning)是一种基于分布式数据训练模型的可行方法,该 方法将私有数据保留在边缘节点中,通过共享参数训练模型,从而防止了原始数据的隐私 泄露。但是,恶意参与者可能会通过共享参数推测他人的隐私,同时,好奇的服务器能够将 参数与参与者链接起来。基于差分隐私的方法,可以为数据提供强隐私保护,通过在参数上 添加噪声,减少模型隐私泄露的可能性。同时,同态加密和安全多方计算方法,通过隐藏原 始数据,保证数据的隐私。 然而,现有的方案依旧没有完全解决如何平衡模型隐私与效率的问题。 通过上述分析,现有技术存在的问题及缺陷为: (1)联邦学习分享参数泄露用户隐私,如何保证数据的隐私,防止参数隐私泄露是 一个技术难题。 (2)在保证参数服务器与参与者通信的情况下,如何防止服务器将参与者与参数 链接起来,实现参与者身份匿名是一个技术难题。 (3)大多数方法以降低模型性能或系统效率为代价提供隐私,如何平衡隐私与效 率是一个技术难题。 解决以上问题及缺陷的难度为:(1)联邦学习分享参数泄露用户隐私,如何保证数 据的隐私,防止参数隐私泄露是一个技术难题。 (2)在保证参数服务器与参与者通信的情况下,如何防止服务器将参与者与参数 链接起来,实现参与者身份匿名是一个技术难题。 (3)大多数方法以降低模型性能或系统效率为代价提供隐私,如何平衡隐私与效 率是一个技术难题。 解决以上问题及缺陷的意义为:联邦学习信息处理方法,实现参与者的匿名,同时 防止模型参数泄露参与者隐私,适用性高,能够用于边缘计算等实际场景。 5 CN 111611610 A 说 明 书 2/8 页
技术实现要素:
针对现有技术存在的问题,本发明提供了一种联邦学习信息处理方法、系统、存储 介质、程序、终端。 本发明是这样实现的,一种联邦学习信息处理方法,所述联邦学习信息处理方法 包括: 第一步,参数服务器确认训练任务及初始参数,并初始化全局模型; 第二步,参数服务器随机选择部分参与者下发模型参数,加密并通过代理服务器 转发; 第三步,参与者接受模型部分参数并覆盖本地模型,利用本地数据对模型进行优 化; 第四步,参与者根据优化结果计算模型梯度,选择其中部分上传,对上传梯度添加 噪声实现差分隐私,加密并通过代理服务器转发; 第五步,参数服务器接受所有参与者的梯度,整合并更新全局模型; 第六步,重复进行模型的下发—训练—更新过程,直到达到预期损失函数。 进一步,所述第一步的模型初始化包括:参数服务器确定训练任务,训练过程,以 及相应的参数,并初始化全局模型 进一步,所述第二步的模型下发包括: 步骤一,参数服务器随机选择m个参与者,全局模型 分别用这m个参与者的公钥 (PK1',PK2',…,PKm')加密,得到模型的密文数据: 步骤二,参数服务器将加密数据发送至代理服务器,代理服务器再转发给所有参 与者。 进一步,所述第三步的本地优化包括:所有参与者接收密文数据后,用自己的私钥 解密,若能解密得到明文,则随机选择 个参数,并替换对应本地模型上的参数值,得 到本地模型W ti ,并在本地数据集Di上优化模型,最小化损失函数: 其中,ni是数据集的样本数,xj表示某一样本,f(xj,W ti )是样本通过模型输出的标 签,yj是样本本身标签; 通过小批量梯度下降法优化模型,将数据集Di分为大小为b_size大小的子数据集 的集合Bi,对于Bi中每个子数据集b,根据梯度下降更新模型参数: W t ti ←Wi -αΔL(W ti ;b); 其中,α是学习率,ΔL是损失函数在b上的梯度,对Bi中所有子数据集更新完一次 后即为一个epoch,经过多个epoch后得到预期优化模型。 进一步,所述第四步的梯度上传包括: 步骤一,计算模型梯度,即优化后模型与原全局模型的参数差值: 6 CN 111611610 A 说 明 书 3/8 页 步骤二,选择其中最大的λ×|ΔW tu i |个梯度上传,保持梯度不变,其余梯度置为0, 将要上传的梯度范围限制在[-r,r],敏感度Δf不超过2r,为每个梯度添加噪音,满足ε-差 分隐私: 其中,f(D)代表原梯度值,A(D)代表添加噪音之后的梯度值,d取值1; 步骤三,将添加噪音之后的梯度用参数服务器公钥加密,并发送到代理服务器,然 后由代理服务器转发给参数服务器。 进一步,所述第五步的模型更新包括:参数服务器接收并解密来自m个参与者的梯 度值,整合优化得到全局模型 全局模型的任一参数 为: 其中, 是原全局模型的参数值, 是参与者i对应的梯度值; 所述第六步的迭代训练包括:继续上述的模型下发—优化—更新过程,直到模型 达到预期损失函数: 本发明的另一目的在于提供一种接收用户输入程序存储介质,所存储的计算机程 序使电子设备执行权利要求任意一项所述包括下列步骤: 第一步,参数服务器确认训练任务及初始参数,并初始化全局模型; 第二步,参数服务器随机选择部分参与者下发模型参数,加密并通过代理服务器 转发; 第三步,参与者接受模型部分参数并覆盖本地模型,利用本地数据对模型进行优 化; 第四步,参与者根据优化结果计算模型梯度,选择其中部分上传,对上传梯度添加 噪声实现差分隐私,加密并通过代理服务器转发; 第五步,参数服务器接受所有参与者的梯度,整合并更新全局模型; 第六步,重复进行模型的下发—训练—更新过程,直到达到预期损失函数。 本发明的另一目的在于提供一种存储在计算机可读介质上的计算机程序产品,包 括计算机可读程序,供于电子装置上执行时,提供用户输入接口以实施所述的联邦学习信 息处理方法。 本发明的另一目的在于提供一种实施所述的联邦学习信息处理方法的联邦学习 信息处理系统,所述联邦学习信息处理系统包括: 模型初始化模块,用于实现参数服务器确认训练任务及初始参数,初始化全局模 型; 模型下发模块,用于实现参数服务器随机选择部分参与者下发模型,加密并通过 代理服务器转发; 7 CN 111611610 A 说 明 书 4/8 页 本地优化模块,用于实现参与者接收模型部分参数并覆盖本地模型,利用本地数 据对模型进行优化; 梯度上传模块,用于实现参与者根据优化结果计算模型梯度,选择其中部分上传, 对上传梯度添加噪声实现差分隐私,加密并通过代理服务器转发; 模型更新模块,用于实现参数服务器接收所有参与者上传的梯度,整合并更新全 局模型; 迭代训练模块,用于重复进行上述模型下发—优化—更新过程,直到模型达到预 期损失函数。 本发明的另一目的在于提供一种终端,所述终端搭载所述的联邦学习信息处理系 统。 结合上述的所有技术方案,本发明所具备的优点及积极效果为:本发明实现多源 数据的人工智能模型训练,保证数据分离,无需分享原数据,从而防止数据的直接隐私泄 露;本发明通过分享更少的参数实现模型训练,减少隐私泄露;同时在参数上添加噪声实现 差分隐私,实现强隐私保护,从而防止数据的间接隐私泄露;本发明引入代理服务器用于参 数服务器与参与者的通信,减少参数服务器的通信开销;而且实现参与者身份匿名,防止参 数服务器将参数与参与者链接起来。 附图说明 为了更清楚地说明本申请实施例的技术方案,下面将对本申请实施例中所需要使 用的附图做简单的介绍,显而易见地,下面所描述的附图仅仅是本申请的一些实施例,对于 本领域普通技术人员来讲,在不付出创造性劳动的前提下还可以根据这些附图获得其他的 附图。 图1是本发明实施例提供的联邦学习信息处理方法流程图。 图2是本发明实施例提供的联邦学习信息处理系统的结构示意图; 图中:1、模型初始化模块;2、模型下发模块;3、本地优化模块;4、梯度上传模块;5、 模型更新模块;6、迭代训练模块。 图3是本发明实施例提供的联邦学习信息处理方法实现流程图。 图4是本发明实施例提供的联邦学习信息处理方法准确率—上传率图; 图中:(a)MNIST MLPλd=1;(b)MNIST CNNλd=1。 图5是本发明实施例提供的联邦学习信息处理方法准确率—下载率图; 图中:(a)MNIST MLPλu=1;(b)MNIST CNNλu=1。 图6是本发明实施例提供的联邦学习信息处理方法准确率—隐私预算图; 图中:(a)MNIST MLPλd=1,r=0.001;(b)MNIST CNNλd=1,r=0.001。 图7是本发明实施例提供的联邦学习信息处理方法准确率—参与者数目图。 图8是本发明实施例提供的联邦学习信息处理方法多个应用场景下效果图。











