
技术摘要:
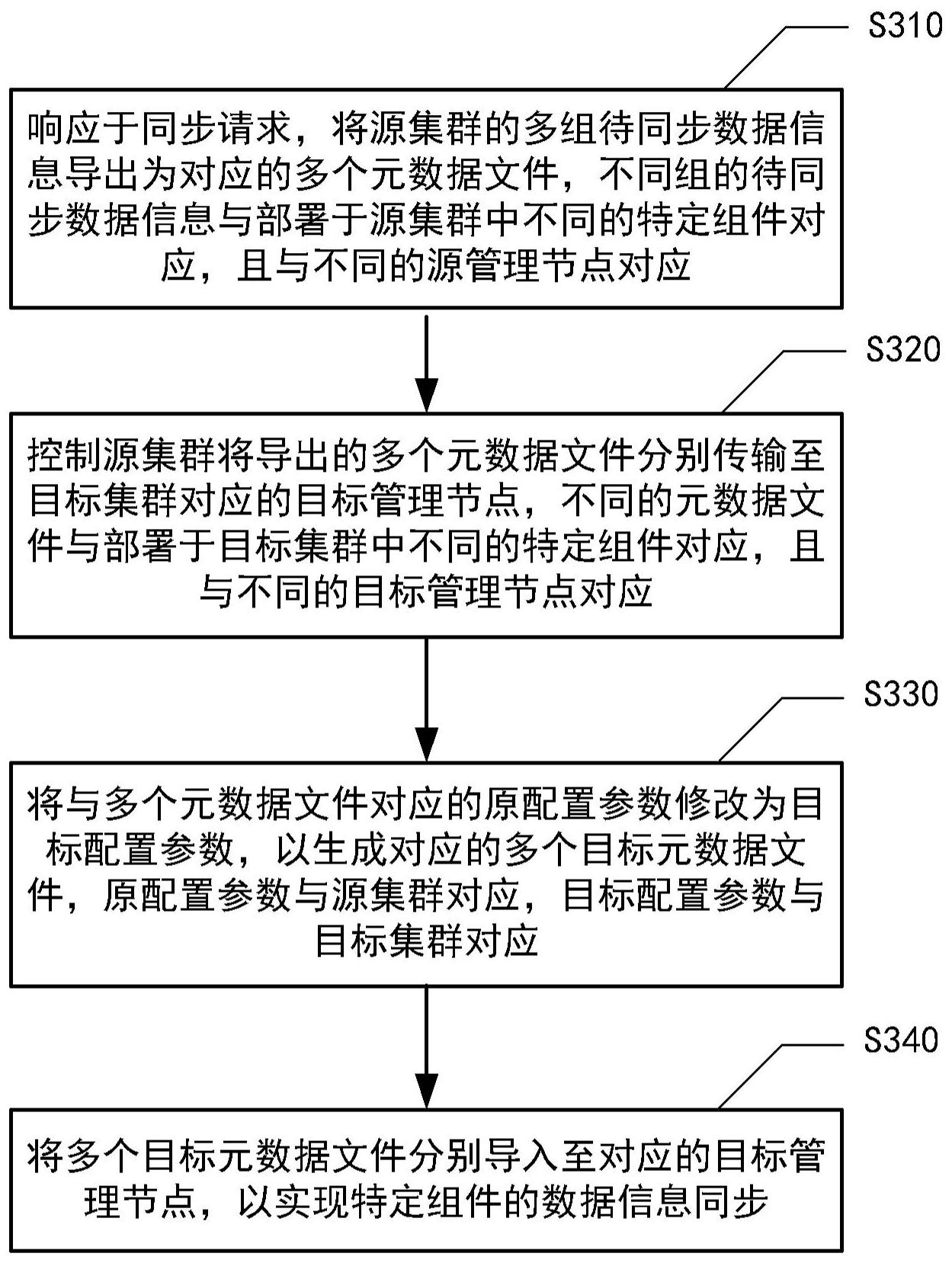
本公开提供了一种数据信息的同步方法,应用于控制服务器,包括:响应于同步请求,将源集群的多组待同步数据信息导出为对应的多个元数据文件,不同组的待同步数据信息与部署于源集群中不同的特定组件对应,且与不同的源管理节点对应;控制源集群将导出的多个元数据文件 全部
背景技术:
随着企业业务的不断扩展深入,在运营管理和生产过程中将会不断地产生海量的 数据,能否高效且快速地对这些产生的海量数据进行存储、整理、分析和计算,在一定程度 上将直接影响到大数据在实际应用中的价值和作用。 相关技术中对大数据进行管理的方式之一是使用基于Hadoop的集群技术建立数 据仓库或者数据集市。Hadoop是一种分布式系统的基础架构,可以将大量的数据分布到不 同的机器上进行处理。Hadoop集群包括多个不同的生态组件,例如LDAP(Lightweight Directory Access Protocol,轻型目录访问协议)、HIVE、HDFS(Hadoop Distributed File System,分布式的文件系统)以及YARN(Yet Another Resource Negotiator,另一种资源协 调者)。其中,LDAP是一个开放的,中立的,工业标准的应用协议,通过IP(Internet Protocol,网际互连协议)提供访问控制和维护分布式信息的目录信息。HIVE是基于Hadoop 的一个数据仓库工具,用来进行数据提取、转化、加载,是一种可以存储、查询和分析存储在 Hadoop中的大规模数据的机制。Hive数据仓库工具能将结构化的数据文件映射为一张数据 库表,并提供结构化查询语言(Structured Query Language,SQL)的查询功能。HDFS是适合 运行在通用硬件(commodity hardware)上的分布式的文件系统,与现有的分布式文件系统 有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度 容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规 模数据集上的应用。YARN的本质是资源管理器,用于控制整个集群并管理应用程序向基础 计算资源的分配。 随着数据量的不断增长,Hadoop集群的数量也呈现出日益增多的趋势,如何在多 个Hadoop集群之间的实现生态组件的元数据信息同步可以提高Hadoop集群的数据管理效 率,因此也成为必须要关注的一个研究方向。但是,相关技术中并无成型的技术方案可以将 一个Hadoop集群包含的生态组件的元数据信息同步给另一个Hadoop集群的生态组件。
技术实现要素:
有鉴于此,为了填补在现有分布式集群体系中,业界无成型的技术方案将多个 Hadoop集群之间的生态组件的元数据进行同步的空白,并因此实现将多个Hadoop集群之间 的生态组件的元数据进行同步的技术效果,本公开提供了一种数据同步方法、装置、电子设 备和介质。与现有技术不同,本公开提供的数据同步方法,用于在不同的Hadoop集群之间实 现各生态组件的元数据同步,而且是一种可视化、定制化以及自动化的数据同步方法,使得 用户可以使用基于Web的图形界面、可选式的进行不同分布式环境下Hadoop集群的任意一 个或者多个生态组件的元数据的同步。 5 CN 111581285 A 说 明 书 2/16 页 为实现上述目的,本公开的一个方面提供了一种数据信息的同步方法,应用于控 制服务器,上述方法包括:响应于同步请求,将源集群的多组待同步数据信息导出为对应的 多个元数据文件,不同组的待同步数据信息与部署于上述源集群中不同的特定组件对应, 且与不同的源管理节点对应,控制上述源集群将导出的上述多个元数据文件分别传输至目 标集群对应的目标管理节点,不同的元数据文件与部署于上述目标集群中上述不同的特定 组件对应,且与不同的目标管理节点对应,将与上述多个元数据文件对应的原配置参数修 改为目标配置参数,以生成对应的多个目标元数据文件,上述原配置参数与上述源集群对 应,上述目标配置参数与上述目标集群对应,将上述多个目标元数据文件分别导入至对应 的上述目标管理节点,以实现上述特定组件的数据信息同步。 根据本公开的实施例,上述将源集群的多组待同步数据信息导出为对应的多个元 数据文件包括:将源集群的用户数据信息导出为对应的用户数据信息元数据文件,上述用 户数据信息与用户信息源管理节点对应,将源集群的数据仓库元数据信息导出为对应的数 据仓库元数据信息元数据文件,上述数据仓库元数据信息与数据仓库元数据源管理节点对 应,将源集群的资源数据信息导出为对应的资源数据信息元数据文件,上述资源数据信息 与资源数据源管理节点对应。 根据本公开的实施例,上述控制上述源集群将导出的上述多个元数据文件分别传 输至目标集群对应的目标管理节点包括:控制上述源集群将导出的上述用户数据信息元数 据文件传输至上述目标集群的用户信息目标管理节点之后,控制上述源集群将导出的上述 数据仓库元数据信息元数据文件传输至上述目标集群的数据仓库元数据目标管理节点,同 时控制上述源集群将导出的上述资源数据信息元数据文件传输至上述目标集群的资源数 据目标管理节点。 根据本公开的实施例,在控制上述源集群将导出的上述多个元数据文件分别传输 至目标集群对应的目标管理节点之前,上述方法还包括:检测上述目标集群中是否已存在 数据信息,若是,则获取上述已存在数据信息,在上述目标集群中备份上述已存在数据信 息。 根据本公开的实施例,上述方法还包括:对上述目标集群执行禁止主备切换操作。 根据本公开的实施例,上述响应于同步请求,将源集群的多组待同步数据信息导 出为对应的多个元数据文件包括:接收上述源集群的源配置文件和上述目标集群的目标配 置文件,上述源配置文件包含源配置参数,上述目标配置文件包含目标配置参数,基于上述 源配置文件和上述目标配置文件,获取上述源集群和上述目标集群的登录状态,在上述登 录状态表明上述源集群和上述目标集群登录成功的情况下,响应于同步请求,将源集群的 多组待同步数据信息导出为对应的多个元数据文件。 根据本公开的实施例,在将上述多个目标元数据文件分别导入至对应的上述目标 管理节点之后,上述方法还包括:对上述目标集群取消上述禁止主备切换操作。 为实现上述目的,本公开的另一个方面提供了一种数据信息的同步装置,应用于 控制服务器,上述装置包括:导出模块,用于响应于同步请求,将源集群的多组待同步数据 信息导出为对应的多个元数据文件,不同组的待同步数据信息与部署于上述源集群中不同 的特定组件对应,且与不同的源管理节点对应,传输模块,用于控制上述源集群将导出的上 述多个元数据文件分别传输至目标集群对应的目标管理节点,不同的元数据文件与部署于 6 CN 111581285 A 说 明 书 3/16 页 上述目标集群中上述不同的特定组件对应,且与不同的目标管理节点对应,修改模块,用于 将与上述多个元数据文件对应的原配置参数修改为目标配置参数,以生成对应的多个目标 元数据文件,上述原配置参数与上述源集群对应,上述目标配置参数与上述目标集群对应, 导入模块,用于将上述多个目标元数据文件分别导入至对应的上述目标管理节点,以实现 上述特定组件的数据信息同步。 根据本公开的实施例,上述导出模块包括:第一导出子模块,用于将源集群的用户 数据信息导出为对应的用户数据信息元数据文件,上述用户数据信息与用户信息源管理节 点对应,第二导出子模块,用于将源集群的数据仓库元数据信息导出为对应的数据仓库元 数据信息元数据文件,上述数据仓库元数据信息与数据仓库元数据源管理节点对应,第三 导出子模块,用于将源集群的资源数据信息导出为对应的资源数据信息元数据文件,上述 资源数据信息与资源数据源管理节点对应。 根据本公开的实施例,上述传输模块包括:第一传输子模块,用于控制上述源集群 将导出的上述用户数据信息元数据文件传输至上述目标集群的用户信息目标管理节点之 后,第二传输子模块,用于控制上述源集群将导出的上述数据仓库元数据信息元数据文件 传输至上述目标集群的数据仓库元数据目标管理节点,第三传输子模块,用于同时控制上 述源集群将导出的上述资源数据信息元数据文件传输至上述目标集群的资源数据目标管 理节点。 根据本公开的实施例,在控制上述源集群将导出的上述多个元数据文件分别传输 至目标集群对应的目标管理节点之前,上述装置还包括:检测模块,用于检测上述目标集群 中是否已存在数据信息,获取模块,用于若是,则获取上述已存在数据信息,备份模块,用于 在上述目标集群中备份上述已存在数据信息。 根据本公开的实施例,上述装置还包括:禁止模块,用于对上述目标集群执行禁止 主备切换操作。 根据本公开的实施例,上述导出模块包括:接收子模块,用于接收上述源集群的源 配置文件和上述目标集群的目标配置文件,上述源配置文件包含源配置参数,上述目标配 置文件包含目标配置参数,获取子模块,用于基于上述源配置文件和上述目标配置文件,获 取上述源集群和上述目标集群的登录状态,导出子模块,用于在上述登录状态表明上述源 集群和上述目标集群登录成功的情况下,响应于同步请求,将源集群的多组待同步数据信 息导出为对应的多个元数据文件。 根据本公开的实施例,在将上述多个目标元数据文件分别导入至对应的上述目标 管理节点之后,上述装置还包括:取消禁止模块,用于对上述目标集群取消上述禁止主备切 换操作。 为实现上述目的,本公开的另一方面提供了一种电子设备,包括:一个或多个处理 器,存储器,用于存储一个或多个程序,其中,当上述一个或多个程序被上述一个或多个处 理器执行时,使得上述一个或多个处理器实现如上所述的方法。 为实现上述目的,本公开的另一方面提供了一种计算机可读存储介质,存储有计 算机可执行指令,上述指令在被执行时用于实现如上所述的方法。 为实现上述目的,本公开的另一方面提供了一种计算机程序,上述计算机程序包 括计算机可执行指令,上述指令在被执行时用于实现如上所述的方法。 7 CN 111581285 A 说 明 书 4/16 页 由上可见,本公开提供的数据信息的同步方法,考虑到Hadoop集群各生态组件元 数据信息底层使用的是关系型数据库存储,所以将源集群的数据库中对应的用户数据信 息、数据仓库元数据信息、资源数据信息这三部分内容分别导出成元数据文件,然后分别传 输到目标集群的对应目标管理节点,接着将元数据文件的配置信息修改为目标集群对应配 置信息,最后导入目标集群底层的关系型数据库中,一方面可以填补在现有分布式集群体 系中,业界无成型的技术方案将一个Hadoop集群包含的生态组件的元数据信息同步给另一 个Hadoop集群的生态组件的空白,另一方面可以实现Hadoop集群的生态组件的数据信息的 定制化同步以及自动化同步,简化数据信息同步的操作步骤,并因此可以实现避免过多集 群内部操作导致的Hadoop集群出现宕机或者服务不可用等技术问题。 附图说明 为了更完整地理解本公开及其优势,现在将参考结合附图的以下描述,其中: 图1示意性示出了适用于本公开实施例的数据信息的同步方法和装置的应用场 景; 图2示意性示出了适用于本公开实施例的数据信息的同步方法和装置的系统架 构; 图3示意性示出了根据本公开实施例的数据信息的同步方法的流程图; 图4示意性示出了根据本公开另一实施例的数据信息的同步方法的流程图; 图5示意性示出了根据本公开实施例的数据信息的同步装置的框图; 图6示意性示出了根据本公开实施例的适于实现上文描述的数据信息的同步方法 的计算机可读存储介质产品的示意图;以及 图7示意性示出了根据本公开实施例的适于实现上文描述的数据信息的同步方法 的电子设备的框图。 在附图中,相同或对应的标号表示相同或对应的部分。











