
技术摘要:
本发明公开了一种基于深度强化学习的恶意软件家族分类规避方法,采用强化学习算法,创建环境并构造智能体,通过不断地与目标恶意软件分类器交互,智能体修改待测恶意软件,最终达到规避分类的目的。本发明方法与其他的恶意软件检测/分类的对抗方法相比,更易于实现且开 全部
背景技术:
恶意软件指实现了攻击者恶意目的的软件,是否存在恶意目的是判定软件是否为 恶意软件的依据。恶意软件能够蓄意删除一些文件或目录信息来破坏计算机硬盘设备,能 够在用户不知情的情况下窃取计算机用户的信息和隐私,也能够非法获得计算机系统和网 络资源的控制,破坏计算机和网络的可信性、完整性和可用性。随着新一代网络信息技术的 不断发展,越来越多的人开始使用互联网,互联网开始影响着生活的方方面面。 然而,互联网的发展也加速了恶意软件的传播。第44次《中国互联网络发展状况统 计报告》显示44.4%的网民2019年上半年在上网过程中遭遇过网络安全问题。针对我国境 内网站的境外攻击、控制事件不断增加。CNCERT新增捕获计算机恶意程序样本数量约3,200 万个,计算机恶意程序传播次数日均达约998万次;中国境内受计算机恶意程序攻击的IP地 址约3,762万个,约占我国活跃IP地址总数的12.4%;位于境外的约3.9万个计算机恶意程 序控制服务器控制了我国境内约210万台主机。计算机恶意程序对用户的感染情况非常严 重,这对经济和社会的各方面发展造成了极大的威胁。因此,对于恶意软件的分析研究刻不 容缓。 对于恶意软件的分析主要可分为检测与分类。其中,前者是判别一个未知的软件 是否存在恶意行为,而后者是建立在已知某个软件存在恶意行为的前提下,将其划分至更 细致的恶意软件家族门类中,以做进一步研究。杀毒引擎对属于同一家族的恶意软件生成 通用的签名,以便在该恶意软件再次入侵计算机系统的时候更快地将其捕获。通常而言,恶 意软件检测可以视为二分类问题,因此它与恶意软件分类问题本质上是一致的。在恶意软 件检测与分类中,现阶段主要采用基于静态/动态分析的机器学习算法构建检测与分类模 型。通过从恶意软件训练集中提取特征,构建特征向量并将其输入至选定的机器学习算法 中,进行模型训练,最终得到检测/分类模型。静态分析方法从恶意软件中提取诸如文件长 度、文件头部字段、信息熵等特征,而动态分析则需要在虚拟环境下动态运行恶意软件,提 取其函数调用关系、API、DLL的使用等特征。尽管上述的分析方法对检测与分类均能够达到 较高的准确率,然而近年来对抗机器学习技术的产生使得这些恶意软件检测与分类模型容 易遭受到攻击,从而影响检测与分类的结果。 目前,常见的对抗方法有基于生成对抗网络(GAN)的恶意软件检测分类规避方法 以及基于梯度的恶意软件检测规避方法。其中,基于GAN的恶意软件检测分类规避方法采用 生成对抗网络模型,通过生成器和判别器的不断博弈,最终产生能规避检测的恶意软件,达 到绕过检测与分类模型的目的。而基于梯度的恶意软件检测分类规避方法则采用神经网络 所产生的梯度信息来构造恶意软件。上述两种方法所涉及的模型训练流程均比较复杂,并 且计算量较大。 4 CN 111552971 A 说 明 书 2/5 页
技术实现要素:
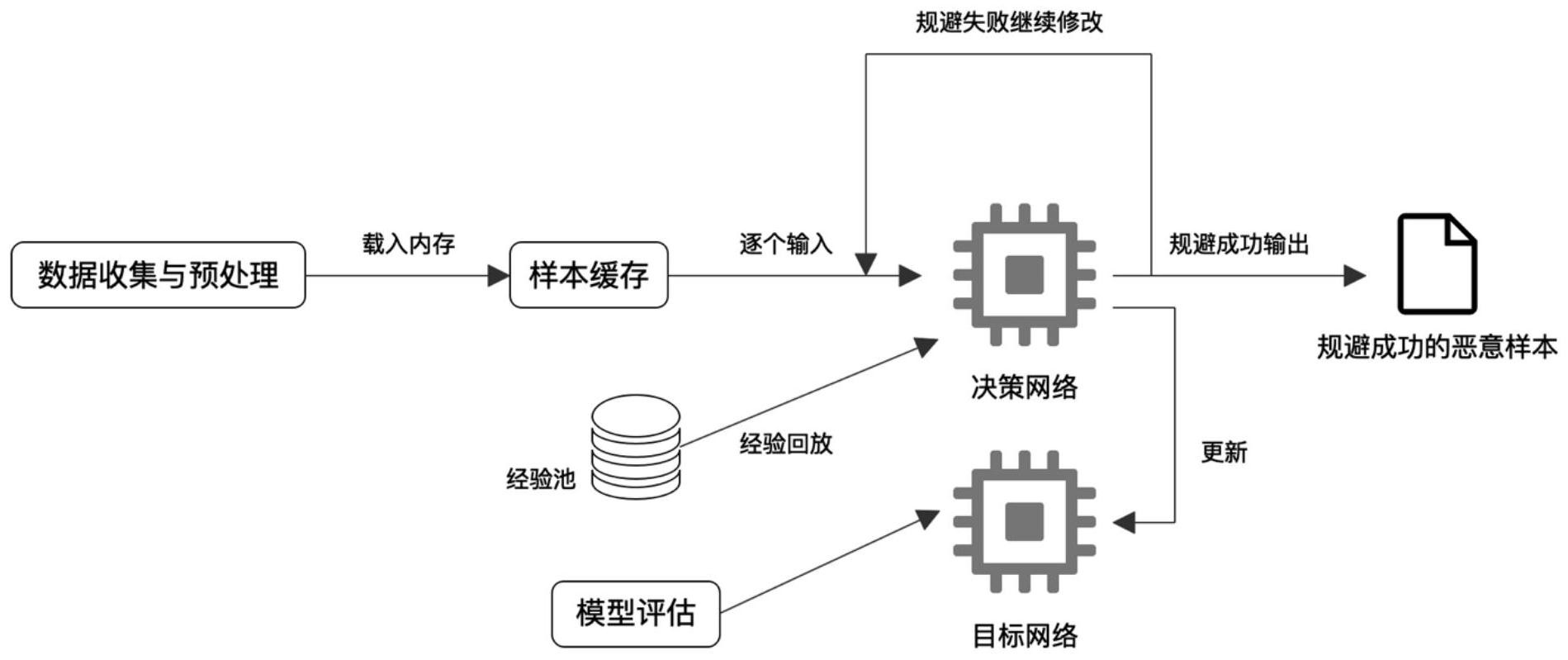
本发明提供一种基于深度强化学习的恶意软件家族分类规避方法,用于提升基于 机器学习算法的恶意软件检测与分类模型的鲁棒性,提升杀毒引擎的防御能力。 本发明采用的技术方案是: 一种基于深度强化学习的恶意软件家族分类规避方法,包括以下步骤: 步骤1:采集病毒样本,完成数据收集与数据清洗; 步骤2:构建智能体、定义强化学习动作空间与状态空间、确定奖励机制;选定待规 避的基于机器学习算法的恶意软件分类模型,初始化采用的深度强化学习模型类型与其超 参数; 步骤3:将一个恶意软件样本输入到待训练的深度强化学习模型中,智能体针对当 前的样本结构得到当前的状态,根据状态选取一个最优的修改动作,并对该恶意样本进行 修改; 步骤4:将修改后的恶意样本输入到选定的分类模型中,分类模型给出预测的该恶 意样本所属的家族类别,并将其与该恶意样本的真实家族类别进行比较,得到奖励; 步骤5:将所得到的当前的状态、当前的动作以及奖励反馈给智能体;如果修改后 的恶意样本被错分为其他家族类别,则对于本样本的修改结束,更新深度网络权值参数,并 跳至步骤3;否则,智能体做出下一个恶意样本修改动作,并对该恶意样本继续修改,循环步 骤5; 步骤6:在训练过程中对智能体进行评估,获得恶意软件分类规避模型。 进一步地,在步骤1中,病毒样本是基于Win32平台的来自Backdoor、Dos、Email、 Exploit、Net-worm、Rootkit、Trojan、Virus、Worm恶意软件家族门类的不同PE格式样本。 进一步地,在步骤1中,利用基于Python的lief解析库对所选用的样本进行解析, 删除lief解析出错的样本,完成数据清洗工作。 进一步地,步骤1还包括:在训练之前对所有样本进行缓存,将样本的二进制数据 全部读取到内存中,训练过程中获取文件的状态时,直接从内存中读取。 进一步地,在步骤2中,在不破坏恶意软件的功能性前提下定义了一系列动作对恶 意软件进行修改;动作空间包含对恶意样本的修改动作为,包括: 1)向恶意样本末尾添加随机字符串; 2)向导入地址表中添加一个包含随机函数名的库; 3)向恶意样本中添加一个随机命名的节表,节的类型在BSS、IDATA、RELOCATION、 TEXT、TLS中选择; 4)重命名所有节表; 5)向节表的空余空间中添加随机字符串; 6)从数据目录表中删除签名。 进一步地,步骤2中的奖励机制为: 1)如果经过智能体修改过的恶意样本能使得目标分类模型给出的预测家族类别 与其原始的家族类别相同,那么奖励值为0; 2)如果智能体修改恶意样本次数超过了设定的最大修改次数,那么奖励值为0; 3)如果经过智能体修改过的恶意样本能使得目标分类模型给出的预测家族类别 5 CN 111552971 A 说 明 书 3/5 页 与其原始的家族类别不相同,那么奖励值为: 式中,MAXTURN表示所允许的最大修改次数;TURN表示对于当前的恶意样本已经修 改过的次数。 进一步地,选用的深度强化学习模型为Double Deep Q-Learning网络。 进一步地,Double Deep Q-Learning网络的超参数设置为: 1)单个样本最大修改次数MAXTURN=80; 2)折扣系数gamma=0.99; 3)Q-Learning网络的更新间隔为100轮次; 4)单次输入网络的最小样本数量为32个; 5)采用经验回放机制,经验回放池的大小为50000; 6)开始采用经验回放机制的时机为算法执行了1000轮次以后; 7)采用探索和利用策略,一开始探索参数为1,终止条件为0.1。 与现有技术相比,本发明的特点是: 采用强化学习算法,创建环境并构造智能体,通过不断地与目标恶意软件分类器 交互,智能体修改待测恶意软件,最终达到规避分类的目的,为进一步提升杀毒引擎的鲁棒 性与防御水平提供帮助。与其他的恶意软件检测/分类的对抗方法相比,本发明中提出的规 避方法,训练开销小,更易于实现。 本发明中基于深度强化学习的恶意软件家族分类规避方法,对于各种利用不同特 征构建的恶意软件分类模型,都能有效地修改恶意软件,同时不会破坏其恶意性功能,最终 规避家族分类。与基于GAN和基于梯度的恶意软件规避方法相比,更便于实现。 附图说明 图1是基于深度强化学习的恶意软件家族分类规避框架图 图2是动作空间可执行的修改动作示意图。 图3是奖励值机制中奖励的变化情况图。 图4是深度强化学习模型网络结构示意图。 图5是规避对抗结果示意图。











