
技术摘要:
本发明涉及文本信息识别技术领域,尤其是一种基于统计模型识别短信文本模版的方法、设备及介质,本发明从短信文本内容去反推短信文本模板,通过先收集相似模板的短信文本再做后续处理,在进行两两对比时先获取两条短信中共同的字符;再按公共字符在两文本中出现的顺序进 全部
背景技术:
作为短信发送平台商,有义务保证在其平台发送的短信均合法合规。因此,需要大 量的人工对短信进行审核。在实际审核工作中,会出现大量文本重复审核的情况。如果能够 统计出短信文本的模板,则可以很大程度减轻审核人员的工作量。 为了实现这种需求,可以使用基于传统的相似度方法,也可以使用基于深度学习 的方法。然而,基于传统的相似度方法普遍是基于文本的模式匹配再计算相似度,当数据量 较大时,会导致效率低且准确率低。并且在短信平台,目前都是提前人工报备短信模板,发 送的时候在报备的短信模板上填写变量,最后发送。因此这类方法目前不能识别短信文本 的模板;另一种基于深度学习的方法,则需要大量的人工标注数据。 综上所述,目前需要一种不依赖人工标注数据,又能解决自动识别出短信文本模 板的方法。 现有技术相关知识点介绍: LSH相似度算法:一种从海量高维数据的高效快速最近邻查找的算法。当面临海量 的高维数据时,查找最近邻信息,如果使用线性查找,就显得非常耗时。一种特殊的哈希函 数可以解决这问题,使得2个相似度很高的数据以较高的概率映射成同一个hash值,而令2 个相似度很低的数据以极低的概率映射成不同的hash值。
技术实现要素:
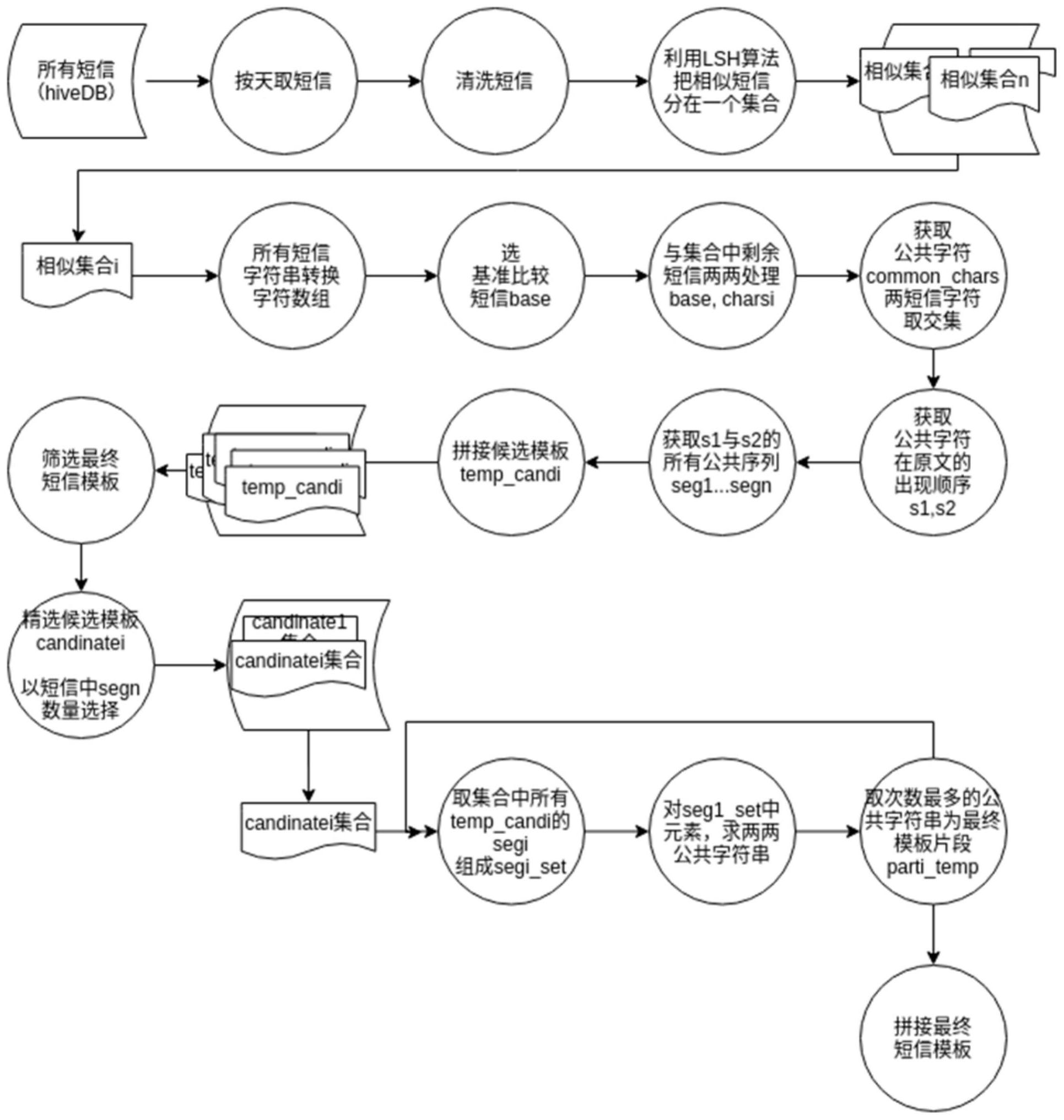
针对上述现有技术中存在的不足,本发明的目的在于提供了一种基于统计模型识 别短信文本模版的方法及装置,解决现有技术准确率低且效率低的问题。 为解决上述问题,本发明公开了一种基于统计模型识别短信文本模版的方法,包 括以下步骤: S1.筛选同一模板的短信文本集合,记作sms_pttDay; S2.清洗sms_pttDay中所有短信文本数据,删除短信中的网址链接,数字与标点符 号,清洗后的sms_pttDay,记作clean_sms_pttDay; S3.把同一模板的短信文本或者相似模板的短信文本筛选出来,具体方法为使用 文本相似度算法把相似度比较高的短信文本收集到一个集合,多个集合分别记作sms_ template_set_1~sms_template_set_i; S4.对每个sms_template_set_i都进行如下的操作: S41.把单条短信字符串变成有顺序的单字符数组,记作charsi; S42.任意取集合中的一条短信文本作为基准比较短信base; S43.用base去遍历剩余短信,提取base与charsi中的公共字符,base与charsi求 4 CN 111597806 A 说 明 书 2/7 页 交集,结果记作common_chars; S44 .定位公共字符common_chars在base与charsi中的位置,通过字符串查找函 数,按顺序依次提取common_chars在base与charsi中的字符,对应为s1,s2; S45.通过字符串模式匹配,找出s1与s2中所有公共序列,记作seg1...segn; S46 .顺序拼接seg1 ...segn,segn前后用{var}分隔,记作temp_cand1~temp_ candi; S47 .每个temp_candi中的segn总数记作number_seg ,选择number_seg相同的 temp_candi,组成的集合为candinate1~candinatei,然后对每个集合进行最终模板的选 择; S48.从sms_template_set_i中剩余的短信中选择任一条作为新的base,回到S43 进行循环,直到处理完sms_template_set_i所有数据; S5.按照S4的步骤依次提取sms_template_set_1~sms_template_set_i中的模 板,并且最终的模板都加入真模板集合template_sms。 作为优先,S1采用天为时间片筛选同一模板的短信文本集合。 作为优先,S3的具体步骤如下:采用融合simhash和minhash的LSH的相似度算法对 clean_sms_pttDay下所有短信文本进行两两计算,输出相似度的值;当两种算法对同样两 条短信文本都计算得出高相似度值时,才能把两条短信文本归属同一个模板集合;最后会 生成多个集合,每个集合中的短信文本都是彼此相似的,记作sms_template_set_1~sms_ template_set_i;相反,把没有选中模版集合的短信文本加入到下一天的sms_pttDay数据 中继续进行数据筛选。 作为优先,融合simhash和minhash的LSH的相似度算法还可替换为以下算法:基于 余弦相似性的Random Binary Projection LSH;基于欧式距离E2LSH;还有基于汉明距离的 Bit Sampling LSH。 作为优先,S46的具体步骤如下: S461.把segn字符数小于2的用{var}替换掉; S462 .替换后,当连续多个{var}一起出现时,则合并为一个{var} ,表现形式为 temp_candi={var}seg1{var}...{var}segn{var}。 作为优先,S47的具体步骤如下: 对每个candinatei都进行如下的操作: S471.依次取temp_cand1~temp_candi中seg1,组成seg1_set集合;在此集合中两 两遍历寻找公共字符串,取其中出现次数最多的公共字符串part1_temp为seg1_set的模 板; S472.依次取temp_cand1~temp_candi中segi,组成segi_set集合;在此集合中两 两遍历寻找公共字符串,取其中出现次数最多的公共字符串parti_temp为segi_set的模 板; S473 .最后candinatei集合为已识别出短信文本模板的短信文本,并且模板为 {var}part1_temp{var}part2_temp...{var}parti_temp{var} ,把最终的这个模板加到真 模板集合template_sms; S474.从sms_template_set_i中,剔除已识别模板的短信文本candinatei与base_ 5 CN 111597806 A 说 明 书 3/7 页 sms_i_chars,当number_seg孤立时与当segi不包含parti_temp时,则把对应的temp_candx 踢出candinatei。 为解决上述问题,本发明还公开了一种计算设备,包括: 一个或多个处理器; 存储器;以及 一个或多个程序,其中所述一个或多个程序存储在所述存储器中并被配置为由所 述一个或多个处理器执行,所述一个或多个程序包括用于执行根据所述的方法中的任一方 法的指令。 为解决上述问题,本发明还公开了一种存储一个或多个程序的计算机可读存储介 质,所述一个或多个程序包括指令,所述指令当由计算设备执行时,使得所述计算设备执行 根据所述的方法中的任一方法。 由于采用上述技术方案,本发明有着如下有益效果: A.从短信文本内容去反推短信模板,通过先收集相似模板的短信文本再做后续处 理,在进行两两对比时先获取两条短信中共同的字符;再按公共字符在两文本中出现的顺 序进行顺序提取,最后只比较上一步的字符;这样做有如下好处:1)不用全文匹配,省时省 力;2)只用选择重点区域比较,更有针对性;3)因为是同一模板,所以必定模板字符同时出 现在原文中。 B .由于本发明是基于规则的短信文本模板匹配,短信文本模板识别的正确性很 高。 C.本发明还可以减少短信的存储空间,达到约1:10000的存储空间优。 D.本发明还可以提升后续任务的计算速度。之前是对短信原文做处理,后续只用 对短信模板做处理,这可以把短信压缩成千上万倍,所以对应的计算时间也降低了成千上 万倍。 E.相对与深度学习识别短信模板的方法,本发明不依赖人工标注数据,不依赖模 型准确率,不依赖大量的计算资源去训练模型。 附图说明 图1是本发明的整体流程示意图; 图2是按天收集的同一模板的20条短信; 图3是筛选出的相似度较高的集合1和集合2; 图4为从候选模板集合中精确提取出的最终模板。











