
技术摘要:
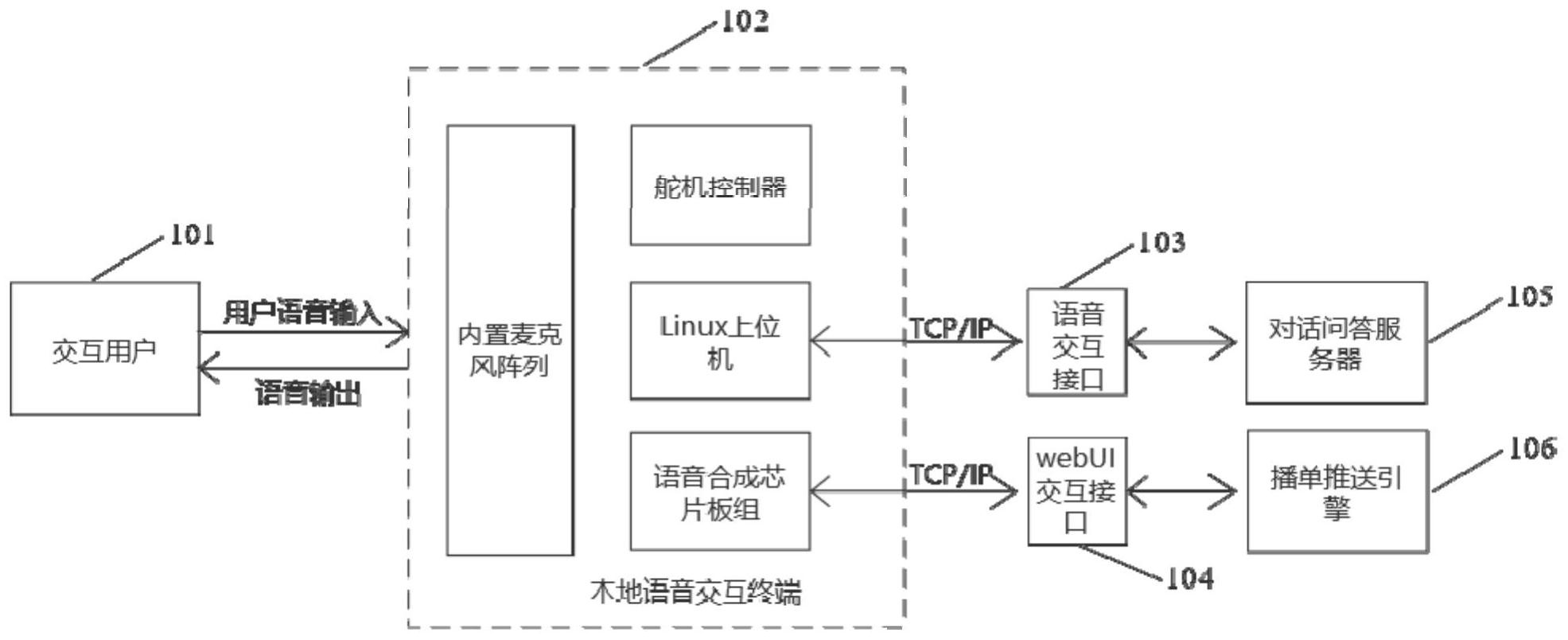
本发明公开了一种基于Text‑CNN的影音播单推送方法及影音播单推送系统,其包括本地语音交互终端、对话系统服务器和播单推荐引擎,对话系统服务器、播单推荐引擎分别与本地语音交互终端相连;本地语音交互终端包括麦克风阵列、上位机和语音合成芯片板,麦克风阵列与语音 全部
背景技术:
在信息爆炸的时代,信息过载困扰着人们日常生活,最重要的信息检索系统也存 在明显的缺陷,检索后的结果数量庞杂。因此如何提高检索准确性,过滤冗余信息,为用户 提供其真正关心的信息是一个技术难题。 在目前交互式资讯推荐系统中,一般通过用户主动订阅相关信息后才会进行相关 资讯的推送,不能根据用户关心的问题或者猜测用户的兴趣点来进行推荐播送,这种被动 交互式推荐系统越来越难以满足人们的日常生活中的各个使用场景的多样化需求。
技术实现要素:
有鉴于此,本发明的目的一种基于Text-CNN的影音播单推送方法及影音播单推送 系统,以解决被动交互式推荐系统存在用户与观影系统交互的便捷性差、不能为用户提供 个性化播单推送服务等技术问题。 本发明基于Text-CNN的影音播单推送方法,其特征在于:包括以下步骤: 1)构建用户基本信息库和影音信息数据库; 2)利用文本数值化技术处理影音信息数据库中的影音简介文本,得到全数值的结 构化数据并将其作为text-CNN神经网络的输入,由下式计算影音简介文本隐特征: 其中W为text-CNN神经网络输入层特征提取权重系数,K为隐藏层特征提取权重系 数,且 q∈RN,投影层Xw由输入层的n-1个词向量构成 的长度为(n-1)m的向量构成; 经过计算得到yw={yw,1,yw,2,…,yw,N}后,设定wi代表由影音简介文本构成的语料 库Context(wi)中的一个词,通过softmax函数归一化得到词wi在用户评分中电影的相似概 率: 上式中iw为词w在语料库Context(wi)中的索引, 表示语料库为Context(w)时 词w在语料库Context(wi)中索引为iw的概率; 整个卷积过程中,设定得到的电影简介文本隐特征为F,且F={F1,F2,…,FD},设Fj 为电影简介的第j个隐特征,则: 5 CN 111581333 A 说 明 书 2/6 页 Fj=text_cnn(W,X) (3) 其中W为text-CNN神经网络输入层特征提取权重系数,X为影音简介文本数值化后 的概率矩阵; 3)text-CNN神经网络的卷积层对概率矩阵X进行评分特征提取,将卷积窗的大小 设定为D×L;池化层对经卷积层处理后影响用户评分的特征放大提取为若干个特征图,即 全连接层以N个一维向量HN作为输入;最后全连接层和输出层将代表电影主要特征信息的 一维数值向量映射为用户评分矩阵维度大小为D的关于用户评分的电影隐特征矩阵V; 4)从Movielens 1m开放式数据集中统计历史用户初始评分信息并根据归一化函 数转为[0,5]的数值化评分矩阵,用户集合为N和电影集合为M,Rij表示用户ui对电影mj的评 分矩阵,用户整体初始评分矩阵为R=[R D×Nij]m×n,R分解得到用户评分隐特征矩阵U∈R 和电 影隐特征矩阵V∈RD×N,特征矩阵维度为D,同时计算用户相似度uSim(ui,uj),将相似度大于 0.75的用户归为近邻用户; 上式中RM为具有评分结果的电影集合,ui,uj分别为参与评分的用户, 为用户ui 对电影m的评分, 为其评分的均值; 5)将用户整体初始评分矩阵R进行基于模型的概率分解,σU为分解Rij得到的用户 隐特征矩阵的方差,σV为分解Rij得到的电影隐特征矩阵的方差;构建用户潜在评分矩阵 即用户的评分预测器, 具体过程如下: 用户整体初始评分矩阵R的概率密度函数分别为: 上式中N为零均值高斯分布概率密度函数,σ为用户整体初始评分矩阵方差;I为用 户观影后是否评分的标记函数,为在拟合过程中得到最能表示用户和电影的隐特征矩阵, 通过梯度下降法,对U和V不断迭代更新直到损失函数E收敛; 上式中Iij为用户i对电影j是否评分的标记函数,参与评分Iij值为1,否则Iij值为 0;φ,φU,φF为防止过拟合的正则化参数; 将损失函数E通过梯度下降法求用户隐特征矩阵U和电影隐特征矩阵V即: 6 CN 111581333 A 说 明 书 3/6 页 再对U和V不断迭代更新求出用户隐特征矩阵U和电影隐特征矩阵V,直到E达到收 敛; 上式中ρ为学习率; 6)将步骤5)训练后的算法模型存为模型文件,在播单推送引擎的服务程序中调用 该模型文件; 7)在对话服务器中定义智能影音播单场景下的语义槽,一旦与近邻用户在智能影 音播单场景下进行语音问答时,触发语义槽中定义的和影音播单相关的实体则为其提供影 音播单推荐功能。 本发明中基于Text-CNN的影音播单推送方法的影音播单推送系统,其包括本地语 音交互终端、对话系统服务器和播单推荐引擎,所述的对话系统服务器、播单推荐引擎分别 与本地语音交互终端相连; 所述的本地语音交互终端包括:麦克风阵列、上位机和语音合成芯片板,所述的麦 克风阵列与语音合成芯片板连接,所述语音合成芯片板和上位机连接,所述上位机与对话 系统服务器连接;所述播单推荐引擎和语音合成芯片板。 进一步,所述的麦克风阵列用于采集用户的语音信息,并将采集的语音信息传送 给上位机,上位机对语音信息进行处理后发送给对话系统服务器; 所述的对话系统服务器对上位机发送的语音信息通过语义匹配形成合适的问答 文本信息,并根据TCP/IP协议将问答文本信息发送到上位机,上位机解析对话系统服务器 发送的问答文本信息,并将解析后的问答文本信息发送给语音合成芯片板,语音合成芯片 板将问答文本信息转换成语音信息并发送给麦克风阵列向用户播报; 所述的播单推荐引擎用于根据用户的问答信息为对话用户生成影音播单信息,并 根据TCP/IP协议将影音播单信息传送到语音合成芯片板;语音合成芯片板根据影音播单信 息生成语音播单推送消息,并将语音播单推送消息发送给麦克风阵列向用户播报。 本发明的有益效果: 本发明基于Text-CNN的影音播单推送方法及影音播单推送系统,其能给用户提供 便捷的交互方式,改善传统UI或者手动点击等交互方式便捷化程度低的缺点,并且本发明 在电影点播等智能家居场景下可有效与其他以语音控制为核心的软硬件服务进行集成,为 用户提供更加便捷化的服务同时满足用户个性化电影点播需求,让产品或者服务在原本的 基础设计上更加深入理解用户需求并适时对输出结果进行调整。 附图说明 图1为实施例中基于Text-CNN神经网络的影音播单推送系统的框架图。 图2为实施例中Text-CNN深度神经网络结构图。 图3为实施例中影音文本特征信息提取过程图。 图4为实施例中用户和电影基本信息的矩阵分解过程图。 图5为实施例中矩阵分解过程中引入概率模型图。 图6为实施例中基于Text-CNN神经网络的影音播单推送系统的程序流程图。 7 CN 111581333 A 说 明 书 4/6 页 图1中附图标记说明: 101-交互用户,102-本地语音交互终端,103-语音交互接口,104-webUI交互接口, 105-对话问答服务器,106-播单推送引擎。











