
技术摘要:
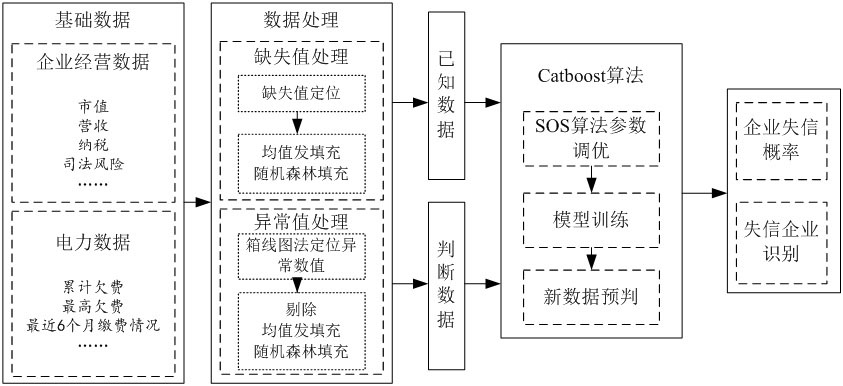
本发明涉及一种基于大数据模型的电力征信评估方法,其包括收集内部企业电力数据和外部企业经营数据的步骤,构建失信用电企业特征和高风险失信用电企业特征的步骤,采用AHP层次分析法、TOPSIS综合评价法构建企业征信评估模型为企业信用打分、确定阈值、依据分数范围确立 全部
背景技术:
企业信用体系建设在推动电力工业高质量发展、构建新型行业监管治理模式、维 护公平公正的电力市场秩序等方面具有重要意义。当前征信体系建设一般存在一下问题: 一是传统的企业信用体系未能包括全行业数据,评估维度不全面;二是传统失信企业识别 方法未采用大数据技术,人工干预程度高,合理性有待提升;三是传统征信评估体系一般直 接使用现有数据,只能区分已经失信和未失信企业,不能对潜在高风险失信企业进行有效 评估,失信治理和信用分类管理效果不佳。
技术实现要素:
本发明所要解决的技术问题是供一种提升企业信用体系建设水平及行业市场主 体信用资产价值,实现失信治理和信用分类管理的基于大数据模型的电力征信评估方法。 本发明采用如下技术方案: 本发明如下步骤: 步骤一、收集内部企业电力数据和外部企业经营数据,基于模糊匹配实现企业经 营数据和用电数据的融合,构建企业信用风险数据池; 步骤二、构建失信用电企业特征和高风险失信用电企业特征; 步骤三、构建企业征信评估模型为企业信用打分,确定阈值,依据分数范围确立用 户信用等级。 本发明失信用电企业特征构建采用如下步骤: A、使用已构建的企业信用风险数据池数据,对使用数据进行缺失值填充、异常数 据识别和处理; B、基于SOS算法优化参数的Catboost分类算法,使用已知失信用电企业数据中企 业基本信息、企业资金信息项、企业风险信息项、企业内部基本信息、企业用电欠费指标项、 企业用电缴费指标项作为输入特征训练Catboost分类算法,基于训练好的模型对所有用电 企业用户进行类别概率判定并设置概率阈值P,当与失信企业相似度>P时,确定为失信企 业。 本发明构建高风险失信用电企业特征采用如下步骤: A、对用电企业历史用电数据和企业经营数据进行数据预处理; B、基于企业历史用电量、缴费情况及经营情况数据,结合外部天气数据、节假日数 据和特殊事件数据,采用LightGBM算法对未来一段时间用电及企业经营情况分别进行预 测,得到未来一段时间企业用电量、欠费、缴费数值预测结果; C、使用改进KNN算法计算预测结果与失信企业相似度,确定用户未来可能发生失 信概率,设置阈值Q,当失信概率>Q时,定位高风险失信用电企业。 5 CN 111612323 A 说 明 书 2/13 页 本发明采用AHP层次分析法、TOPSIS综合评价法构建企业征信评估模型,包括如下 步骤: A、确定失信用电企业特征、高风险失信用电企业特征、企业缴费数据、企业欠费数 据、企业纳税等级和企业风险数据各个特征的层次结构, B、采用AHP层次分析法对上述各项指标赋值; C、采用TOPSIS综合评价方法对企业进行逐一评价,得到企业信用分值,并设置阈 值确定信用等级。 本发明步骤一中的内部企业电力数据和外部企业经营数据由采用python环境下 Fuzzy Wuzzy字符串模糊匹配融合形成用电企业信用风险数据池,所述Fuzzy Wuzzy为模糊 字符串匹配算法库,其依据Levenshtein Distance算法计算两个字符序列之间的差异。 本发明所述Catboost分类算法为处理类别型特征的梯度提升算法库,其对所有样 本进行随机排序,再针对类别型特征中的某个取值,每个样本的该特征转为数值型时都是 基于排在该样本之前的类别标签取均值,同时加入了优先级和优先级的权重系数;使用如 下公式将所有的分类特征值转换为数值,让σ=(σ1,…,σn),xσp,k代替为: P是添加的先验项, a是大于0的权重系数, σj,σp为第σj,σp行数据, 可降低类别特征中低频次特征带来的噪声; CatBoost使用oblivious树作为基本预测器,在oblivious树中,每个叶子节点的 索引可以被编码为长度等于树深度的二进制向量,计算公式为: 本发明所述SOS算法通过共生、共栖和寄生三步共生机制不断探索解空间,其基本 计算公式如下: 共生过程: Xinew=Xi rand(0,1)*(Xbest-Mutual_Vector*BF1) (3) Xjnew=Xj rand(0,1)*(Xbest-Mutual_Vevtor*BF2) (4) Mutual_Vector=(Xi Xj)/2 (5) 式中: rand(0,1)为[0,1]间的随机数; Xbest为当前最优值, Mutual_Vector为数据间的共生关系, Xinew,Xjnew为新生成的值; BF1和BF2取值为1或2,当BF取值为1时代表部分受益,取值为2时代表全部受益; 公式(5)为一种关系特性,即进化因素由当前两个个体的均值决定,当新进化个体 优于当前个体,才更新当前个体,否则淘汰; 6 CN 111612323 A 说 明 书 3/13 页 共栖过程: Xinew=Xi rand(-1,1)*(Xbest-Xj) (6) 式中: rand(-1,1)为[-1,1]间随机生成结果; (Xbest-Xj)为受益关系,由Xj提供优秀基因提升Xi的存活率,当新生个体更能适应 生态系统时,才接受新生个体,否则淘汰; 寄生过程: Parasite=rand(0,1)*Xi (7) 式中: rang(0,1)为[0,1]间的随机数。 本发明所述LightGBM基于Histogram的决策树算法,其采用如下变换函数: px(t)为概率密度函数; 在二叉树中可以通过利用叶节点的父节点和相邻节点的直方图的相减来获得该 叶节点的直方图,公式如下: Histogram(a)=Histogram(b)-Histogram(c) (9) 式中Histogram(b)为父节点直方图, Histogram(c)为相邻节点直方图, Histogram(a)为叶节点直方图。 本发明改进KNN算法主要依据下述公式改进度量方式: 式中: x为权重调整系数; D(a,b)为数据间欧氏距离; cov(a,b)为数据间余弦距离。 本发明所述TOPSIS综合评价方法为: C=S′/(S′ S″) (14) 其中S′代表目标向量与负理想解间距离,S″代表目标向量与正理想解间距离: 其中,fij表示目标向量,f′为负理想解,f″为正理想解。 本发明积极效果如下: 1、基于外部企业经营数据和内部用户实际的电力数据构建的企业信用风险数据 池,维度更为全面,数据可靠性更强。 2、本发明基于大数据分析技术构建失信用电企业特征,基于企业风险数据池数 7 CN 111612323 A 说 明 书 4/13 页 据,分析维度更为全面且可靠性强,使用SOS算法优化的Catboost算法构建失信用电企业识 别模型,计算方法具有先进性且结果更为精确。 3、本发明基于大数据分析技术构建高风险失信用电企业特征,采用LightGBM算法 构建企业未来用电量预测模型和欠费情况预测模型,能够实现企业未来一段时间用电量、 欠费情况的准确预估,该项指标能够体现未来企业发展趋势,增加企业信用分析维度。 4、多维度的企业征信评估模型,综合失信电用企业特征、高风险失信用电企业特 征、企业缴费数据、企业欠费数据、企业纳税等级、企业风险数据,采用层次分析法对各项指 标赋值,经过专家对赋值权重进行调整后采用TOPSIS综合评价方法对企业进行逐一评价, 得到综合企业外部经营数据的多维度企业信用分值,设置阈值确定的信用等级更为可靠。 附图说明 附图1为本发明失信用电企业识别模型流程图; 附图2为本发明高风险失信用电企识别模型流程图。











