
技术摘要:
本发明涉及基于编码的数据融合方法及系统;本发明方法使用不同数据持有者的公共字段对应信息进行编码实现实体唯一ID创建;并且根据所述实体唯一ID实现数据融合。在保证不暴露、或依赖隐私信息前提下,实现不同数据持有之间的同一实体重新标识的一致性,并满足唯一性, 全部
背景技术:
大数据分析中,越来越多的场景是联合分析,即两个以上的数据分析参与者们,各 自拥有自己的数据,但是各自的数据并不能建立比较全面的分析;必须将多方数据融合起 来,才能建立起准确的分析。 数据的高效融合成了大数据技术中需要解决的难题。给实体赋ID是解决数据融合 的技术途径之一。但是由于不同数据持有者之间由于数据格式字段等不同,往往采取了不 同的实体ID产生机制,且出于数据的安全性等方面的考虑,ID的产生方法在不断变化中。 自然状态下重名的实体很多,尤其是自然人,在没有身份证信息的情况下,和实体 对齐的前置条件下如果ID不同,则不能判断同名实体为同一实体,因此也不能进行数据融 合,为数据的融合和联合分析造成重大的障碍。
技术实现要素:
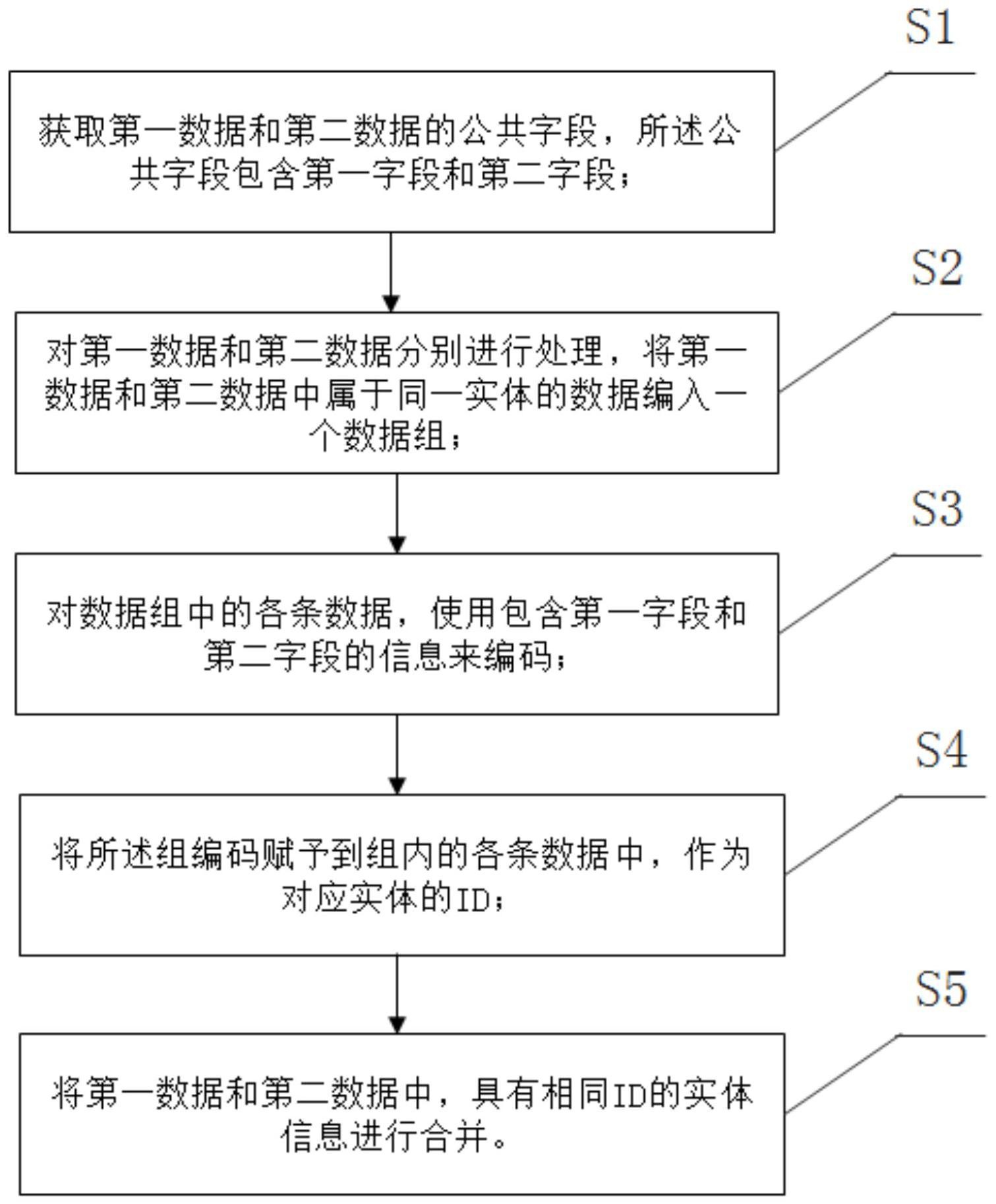
本发明的目的提供基于编码的数据融合方法及系统,在保证不暴露、或依赖隐私 信息前提下,实现不同数据持有之间的同一实体重新标识的一致性,并满足唯一性,稳定性 要求;且在编码基础上实现高效率的多源数据融合以及数据集成。 基于编码的数据融合方法,所述方法使用不同数据持有者的公共字段对应信息进 行编码实现实体唯一ID创建;并且根据所述实体唯一ID实现数据融合。 具体的,所述方法包含以下实现步骤: 获取第一数据和第二数据的公共字段,所述公共字段包含第一字段和第二字段; 对第一数据和第二数据分别进行处理,将第一数据和第二数据中属于同一实体的 数据编入一个数据组; 对数据组中的各条数据,使用包含第一字段和第二字段的信息来编码; 对获得的编码进行排序,选出一个编码作为对应数据组的组编码; 将所述组编码赋予到组内的各条数据中,作为对应实体的ID; 将第一数据和第二数据中,具有相同ID的实体信息进行合并。 作为一种优选,其中第一字段为实体名。 作为一种优选,所述步骤对数据组中的各条数据,使用包含第一字段和第二字段 的信息来重新编码;编码算法为hash算法。 作为一种优选,所述步骤对数据组中的各条数据,使用包含第一字段和第二字段 的信息来重新编码;编码算法为md5。 进一步的,所述步骤对数据组中的各条数据,使用包含第一字段和第二字段的信 息来重新编码中,使用包含第一标识、第一字段、第二标识和第二字段的信息来进行编码。 进一步的,所述步骤获取第一数据和第二数据的公共字段,所述公共字段包含第 3 CN 111597346 A 说 明 书 2/12 页 一字段和第二字段中,所述公共字段还包含第三字段。所述第三字段的信息可以是文字,数 据和或符号。 作为一种优选,所述步骤对获得的编码进行排序,选出一个编码作为对应数据组 的组编码中,以第三字段包含的信息为依据来进行排序。 作为一种优选,所述步骤对获得的编码进行排序,选出一个编码作为该数据组的 组编码中,使用第一字段和或第二字段中包含的信息来对编码进行排序。 进一步的,本发明提供基于编码的数据融合系统,所述系统使用所基于编码的数 据融合方法来实现数据融合。 进一步的,所述系统包含数据获取模块、存储模块和处理模块,所述数据获取模 块、存储模块和处理模块依次相连,所述数据获取模块用于获取待处理数据,所述数据获取 模块将获取到的数据输入到存储模块中进行存储;所述存储模块还用于存储所述处理模块 的输入输出数据,所述处理模块通过所述基于编码的数据融合方法来实现数据的融合。 有益效果: 本发明提供基于编码的数据融合方法及系统;本发明利用各个数据持有者所拥有 的公共字段来对实体进行编码实现ID构建,并且在相同ID的基础上实现数据的融合;为数 据集成,联合分析打下基础。通过本发明方法系统实现的数据融合,所需计算量小,融合效 率高,数据安全性强。 附图说明 为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附 图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对 范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这 些附图获得其他相关的附图。 图1为基于编码的数据融合方法的流程示意图。











