
技术摘要:
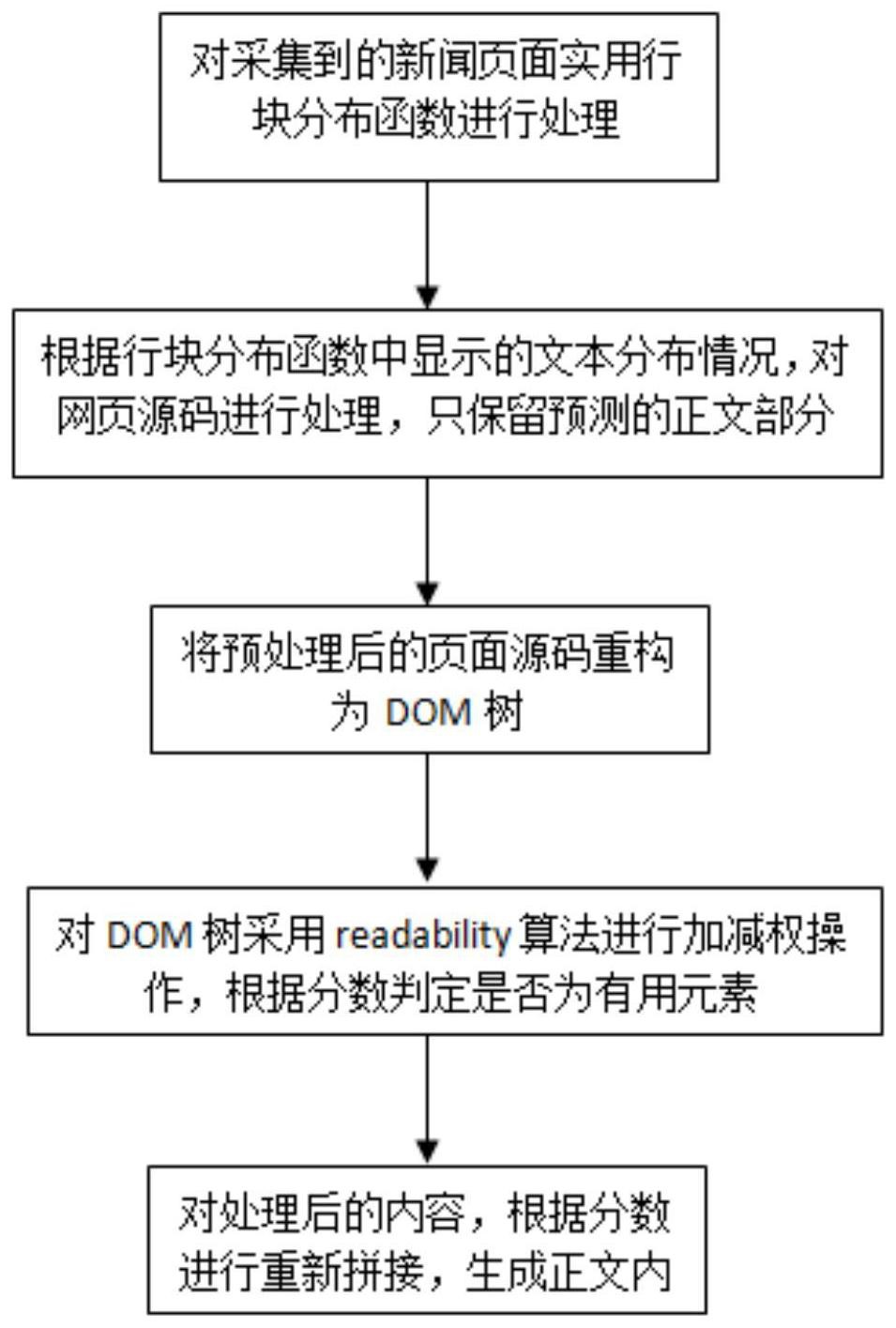
本发明涉及一种特定主体的跨网站通用新闻采集方法,包括:步骤1:引入疏密度判断的方法,对采集到的新闻页面使用行块分布函数进行预处理;步骤2:根据行块分布函数中显示的文本的分布情况,通过预先设定的阈值,确定可能包含正文的区域;步骤3:将预处理过的页面源码重 全部
背景技术:
互联网上存在海量的信息,而Web数据通常是非结构化的,这意味着它包含噪声和 无用数据,因此通过手动提取以从所有网站获取数据是不现实的,这样不仅要消耗大量的 时间、人力成本,也不能保证准确性和时效性。网络数据提取在很多领域都是普遍面临的问 题,其中涉及到广泛的科学工具和应用。目前很多技术的研究和发展是以数据为基础,如自 然语言处理所需要的文本数据、计算机视觉研究需要的图像数据等。在各种项目的实际应 用中,数据的收集也是必不可少的部分。而如何高效准确的抓取数据,保证数据的时效性, 减少人工的参与,是系统实现主要面临的问题。本系统开发主要面向财经领域,财经新闻数 据的特点可以很好地衡量系统的有效性,数据量大、时效性高,所获取的数据也可用于进一 步的分析与处理。 目前国内外对于网页正文提取的算法主要分为4大类: 基于模板规则。这类算法从大量网页中生成模板,进而通过模板匹配来过滤网页 噪音从而生成网页正文。通常,不同的网站拥有不同的网页布局,同一网站下的网页拥有相 似网页布局。基于模板规则的正文提取方法复杂度较低,但由于其主要针对一个或相似网 页布局的网站,不具有通用性。 基于视觉分块。这类算法根据网页中的位置视觉信息来确定正文区域块,虽然提 取效果很好但其依赖于浏览器内核代码,耗时长,算法复杂度高。 基于启发式规则。这类算法首先将HTML解析成DOM树或某种特定格式,根据正文特 征如文本长度、纯文本比率、标点,人为指定若干规则最终找到正文块并提取正文内容,复 杂度较低,针对新闻、博客类网站有较好的正文提取效果。 基于机器学习。这类算法使用机器学习算法,如粒子群算法、决策树算法,对网页 正文特征,如文本特征密度、特征标签个数、标点个数或标点密度等确定其影响因子权值, 根据目标函数最大值确定正文内容。该类算法适应性较高,但其运算量较大,算法复杂度较 高。 Readability内容分析算法作为一种启发式算法,以其高效过滤网页噪音,目前已 被应用到多种浏览器的文本浏览应用中。该算法通过遍历DOM对象,结合标签和属性值对节 点进行加权计分(部分加减权如表1所示),根据分数和文本特性重新整合出页面内容。 表1正则表达式匹配 3 CN 111581478 A 说 明 书 2/4 页 1 .原始Readability算法在应用到不同风格的网页正文抽取中时,容易遗漏正文 内部数据信息。 2.Readability算法对网页处理过程中需要将页面重构为DOM树,虽然可以保证高 准确率,但是处理时间过长,在面对海量数据时有待优化。 3.目前的研究主要集中在算法部分,而系统架构也是影响提取效果的重要因素, 面向实际应用目的进行开发而不能只考虑准确率,也是当前技术方案需要解决的问题。
技术实现要素:
针对现有技术之不足,一种特定主体的跨网站通用新闻采集方法,所述方法包括: 步骤1:引入疏密度判断的方法,对采集到的新闻页面使用行块分布函数进行预处 理; 疏密度判断包括基于对网页的内容分析,可以得出页面内数据的分布情况; 步骤2:根据行块分布函数中显示的文本的分布情况,通过预先设定的阈值,确定 可能包含正文的区域,并对网页源码进行处理,只保留预测的正文区域部分; 步骤3:将预处理过的页面源码重构为DOM树; 步骤4:此时DOM树中包含的元素相对刚开始的完整页面已大大减少,对其使用 readability算法进行加减权操作,根据设定的分数要求,判断正文内容或无用元素; 步骤5:对处理后的内容,根据分数进行重新拼接,重组后生成正文内容。 根据一种优选的实施方式,在确定了正文的区域后,提取正文区域的HTML源代码, 使用readability算法进行进一步的精准提取,输出正文文本内容,步骤4具体步骤包括: 步骤41:HTML解析,将HTML解析成一棵DOM树,通过遍历树节点,操作HTML标签; 步骤42:遍历标签节点,提取其类别属性和ID属性进行正则匹配; 步骤43:确定正文主块节点,针对段落标签p,对其父节点和祖父节点进行计分;计 分因子包括段落标签所含文本长度、包含标点个数、节点标签名,若段落标签文本长度达 标,将其父节点和祖父节点加入候选节点列表,最后通过遍历候选节点,结合纯文本比率选 出最高分数的标签节点作为正文主块节点; 步骤44:正文块生成,遍历正文主块节点的同辈节点,判断其是否为正文节点; 首先评估其节点分数,若节点分数达标则标注为正文节点,否则判断其是否为段 落标签p节点,若为段落标签p节点且其文本特性达标则同样标注为正文节点; 然后创建一容器节点作为正文块节点,将筛选得到的正文节点与正文主块节点拼 接到正文块节点中; 步骤45:剪枝,对正文块节点中的特定标签进行清理,遍历其中的
、、
4
CN 111581478 A 说 明 书 3/4 页











