
技术摘要:
本发明公开了一种基于深度学习的视觉SLAM定位方法,基于神经网络,并集数据预处理、视觉里程计、闭环检测、后端优化于一体,实现了机器人的定位。相较于传统的视觉SLAM算法流程而言,本发明基于深度学习鲁棒性能更好,对环境的适应性更强。相较于目前的基于深度学习的 全部
背景技术:
随着人工智能以及机器人领域的快速发展,利用深度学习来实现机器人的自主定 位导航逐渐成为机器人研究领域重要研究方向。其中,视觉SLAM成为近年来机器人定位导 航研究领域中最为活跃的领域之一。它也是整个视觉定位导航里面非常突出的一种技术, 它被各种各样的领域所需要,如无人机领域、服务机器人领域、清洁机器人及工业机器人领 域等。 一个完整的视觉SLAM系统需要几个关键模块,如图1所示,包括数据处理、视觉里 程计、后端优化、地图构建和闭环检测。它的一般实现流程为:首先从传感器中获取图像数 据信息;然后通过前端的视觉里程计,估算相邻帧间相机运动的情况;然后利用闭环检测识 别机器人是否到达过当前位置;最后通过后端的图优化将视觉里程计与闭环检测的结果进 行进一步优化,从而可以借助估计的机器人轨迹与姿态完成地图构建。 根据生成方法的不同,视觉SLAM可以分成:间接方法、直接方法以及在神经网络方 面的方法。其中间接方法首先对测量数据进行预处理来产生中间层,通过稀疏的特征点提 取和匹配来实现的,也可以采用稠密规则的光流,或者提取直线或曲线特征来实现,然后计 算出地图点坐标或光流向量等几何量,因此间接方法优化的是几何误差。直接方法跳过预 处理步骤直接使用实际传感器测量值,例如在特定时间内从某个方向接收的光,在被动视 觉的情况下,由于相机提供光度测量,因此直接方法优化的是光度误差。传统的视觉SLAM在 环境的适应性方面依然存在瓶颈,深度学习有望在这方面发挥较大的作用。 目前,深度学习已经在语义地图、重定位、闭环检测、特征点提取与匹配以及端到 端的视觉里程计等问题上有了相关工作,例如CNN-SLAM在LSD-SLAM基础上将深度估计以及 图像匹配改为基于卷积神经网络的方法,并且可以融合语义信息,得到了较鲁棒的效果;剑 桥大学开发的PoseNet,是在GoogleNet的基础上将6自由度位姿作为回归问题进行的网络 改进,可以利用单张图片得到对应的相机位姿《;视觉SLAM十四讲》一书的作者高翔,利用深 度神经网络而不是常见的视觉特征来学习原始数据的特征,实现了基于深度学习的闭环检 测;LIFT利用深度神经网络学习图像中的特征点,相比于SIFT匹配度更高。UnDeepVO(基于 非监督深度学习的单目视觉里程计)能够通过使用深度神经网络估计单目相机的6自由度 位姿及其视野内的深度。UnDeepVO有两个显著的特点:一个是采用了无监督深度学习机制, 另一个是能够恢复绝对尺度。UnDeepVO在训练过程中使用双目图像恢复尺度,但是在测试 过程中只使用连续的单目图像。虽然目前有许多有关基于深度学习的视觉SLAM领域的算法 研究,但大多都是基于SLAM中某个单独的模块利用深度学习算法进行研究,如基于深度学 习的视觉里程计算法研究,基于深度学习闭环检测算法研究等,因此探究基于深度学习的 视觉SLAM算法研究非常重要。 4 CN 111578956 A 说 明 书 2/5 页
技术实现要素:
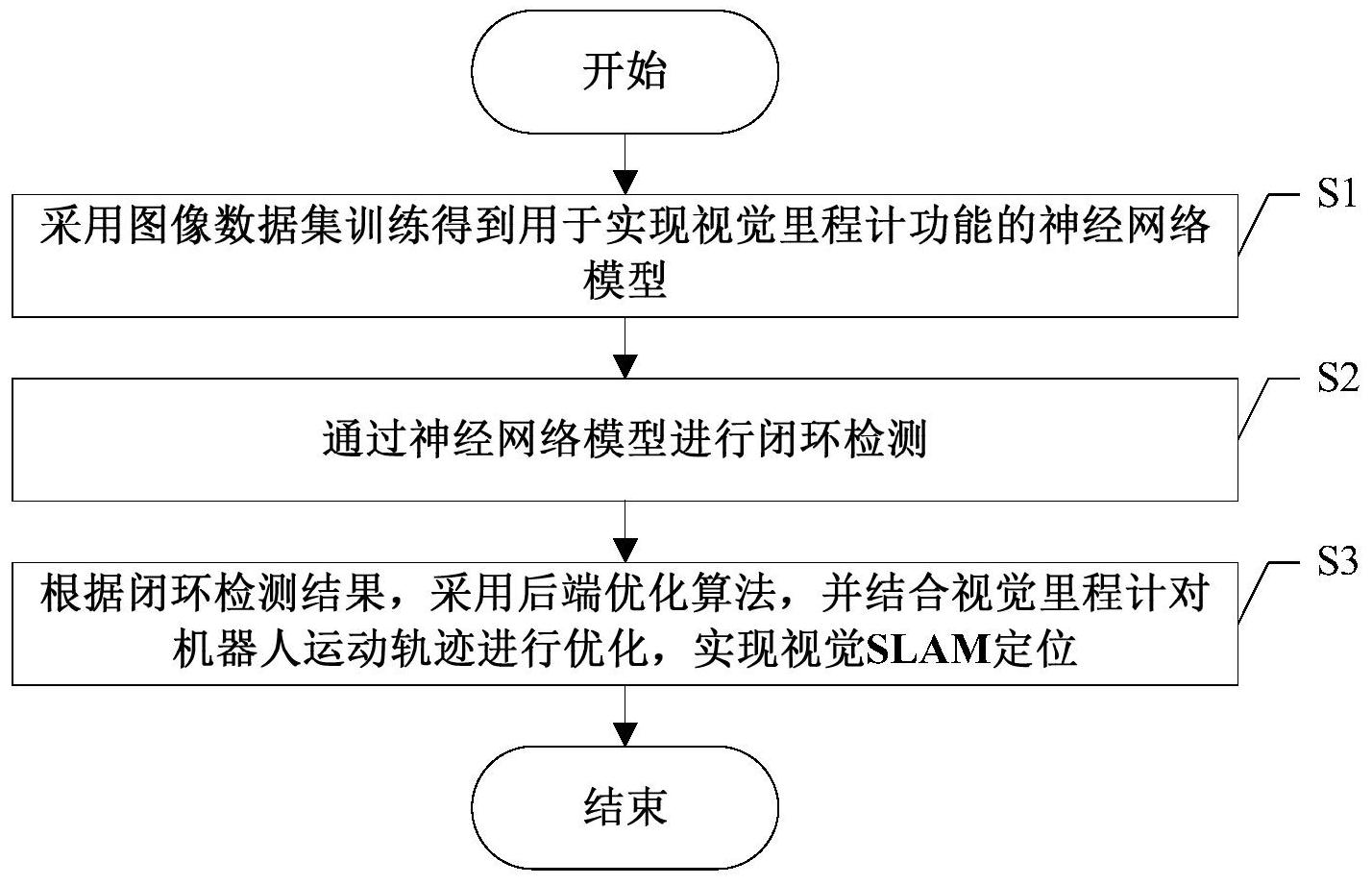
本发明的目的是针对现有的基于深度学习的视觉SLAM定位算法只使用神经网络 训练的模型来实现SLAM算法中的某个单一模块而非整个算法流程的问题,提出了一种基于 深度学习的视觉SLAM定位方法,通过神经网络来实现整个视觉SLAM定位算法的功能。 本发明的技术方案为:一种基于深度学习的视觉SLAM定位方法,包括以下步骤: S1、采用图像数据集训练得到用于实现视觉里程计功能的神经网络模型。 S2、通过神经网络模型进行闭环检测。 S3、根据闭环检测结果,采用后端优化算法,并结合视觉里程计对机器人运动轨迹 进行优化,实现视觉SLAM定位。 进一步地,步骤S1包括以下分步骤: S11、对图像数据集中的图像数据进行预处理,并将图像数据集分为训练集、测试 集和验证集。 S12、采用训练集训练用于实现视觉里程计功能的神经网络模型。 S13、采用验证集对训练后的神经网络模型进行验证,若验证效果合格则进入步骤 S14,否则查找问题、返回步骤S12继续训练或者更换神经网络模型。 S14、采用测试集对验证效果合格的神经网络模型进行测试,若测试效果符合算法 阈值则选定当前的神经网络模型用于实现视觉里程计功能,否则查找问题、返回步骤S12继 续训练或者更换神经网络模型。 进一步地,步骤S11中对图像数据集中的图像数据进行预处理包括图像数据去噪 和图像大小的调整。 进一步地,步骤S12中训练用于实现视觉里程计功能的神经网络模型包括确定神 经网络的输入和输出、采用卷积层和池化层的数量以及采用的激活函数。 进一步地,步骤S2包括以下分步骤: S21、提取神经网络模型不同网络层的输出特征,并对输出特征进行降维处理。 S22、根据不同网络层的输出特征降维的形式,采用多层网络特征级联的方式作为 图像描述符,并选定最佳组合方式。 S23、根据最佳组合方式得到图像描述子,并对图像描述子进行归一化操作。 S24、根据归一化后的图像描述子,采用相似性算法,计算图像数据集的相似度矩 阵,并优化相似度矩阵,做出闭环的判断。 进一步地,步骤S23中对图像描述子进行归一化操作的公式为: 其中img_proc表示归一化后的图像描述子,img表示特征级联之后的图像特征矩 阵, 表示img的L2范数,d表示神经网络模型某一层的输出维度。 进一步地,步骤S24具体为:计算第i帧图像li与第j帧图像lj的相似度Sim(i,j): 5 CN 111578956 A 说 明 书 3/5 页 其中 表示第i帧图像li归一化后的图像描述子, 表示第j帧 图像lj归一化后的图像描述子, 表示第i帧图像li与第j帧图像lj 的差异大小,Sim(i,j)∈[0,1]。 确定阈值Th,若Sim(i,j)≥Th,则判断为闭环,否则判断为非闭环。 进一步地,步骤S3具体为:若检测到有闭环存在,则采用后端优化算法进行反向优 化,得到精确的机器人的运动轨迹,并构建地图,实现视觉SLAM定位。 本发明的有益效果是:本发明基于神经网络,并集数据预处理、视觉里程计、闭环 检测、后端优化于一体,实现了机器人的定位。相较于传统的视觉SLAM算法流程而言,本发 明基于深度学习鲁棒性能更好,对环境的适应性更强。相较于目前的基于深度学习的方法, 本发明利用一个神经网络架构便能够同时实现闭环检测和视觉里程计的功能,并基于该神 经网络模型实现了整个视觉SLAM定位方法的流程,避免了不同模块采用不同的网络结构, 进一步解决了由于网络结构的复杂性使得整个算法流程更加复杂,实时性能也会受到影响 的问题。 附图说明 图1所示为现有的经典视觉SLAM定位算法总体框架图。 图2所示为本发明实施例提供的基于深度学习的视觉SLAM定位方法总体框架图。 图3所示为本发明实施例提供的基于深度学习的视觉SLAM定位方法流程图。











