
技术摘要:
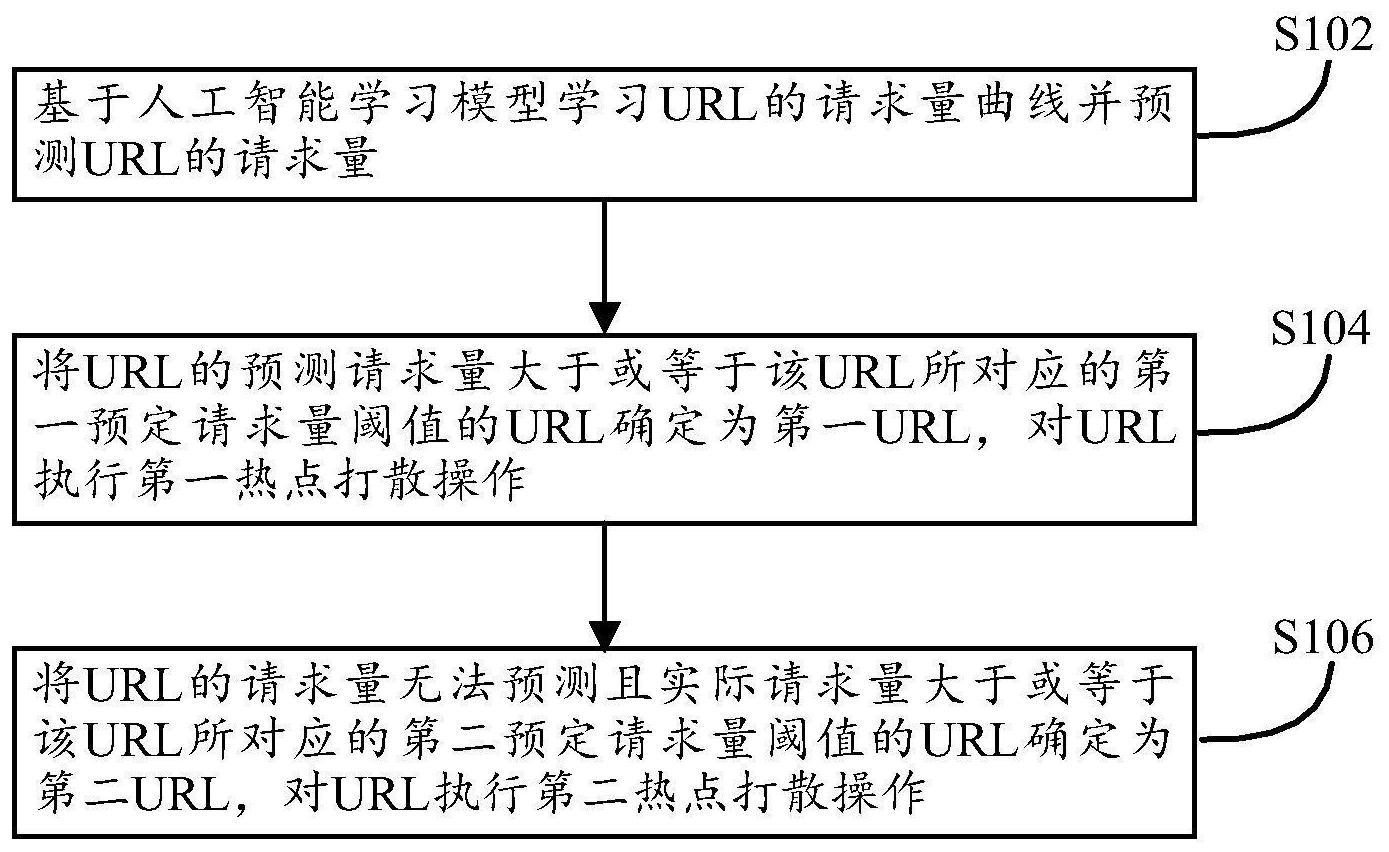
本发明公开了一种智能热点打散的方法、装置、存储介质及计算机设备。所公开的方法包括:基于人工智能学习模型学习URL的请求量曲线并预测URL的请求量;将URL的预测请求量大于或等于该URL所对应的第一预定请求量阈值的URL确定为第一URL,对URL执行第一热点打散操作;将UR 全部
背景技术:
为了减小服务器端的处理时延,改善用户体验,通常都需要对URL(特别是热点 URL)进行打散/均衡操作。 现有技术通常采用将集中的URL随机或均匀地分散到后端机器(例如,源站节点服 务器集群、边缘节点服务器集群)的方式,来实现针对热点URL的负载均衡。 然而,现有技术方案通常只是在热点URL出现之后,才执行打散操作,从而将针对 热点URL的请求分散地分配到多台机器,因此存在以下缺点: 1、没有在前期针对热点URL可能存在的趋势做出判断,做出预先处理。只是在发现 热点之后直接打散,没有缓存的机器会直接回上层节点或者源造成大量流量浪费。 2、即使采用组内共享缓存方案,将所有回源流量重新导回统一端口,在热点文件 较大(例如,文件大小超过1G)时,在各个机器取完文件之前,热点堆积现象将无法解决,该 统一端口的压力并没有减少。 为了解决上述问题,需要提出新的技术方案。
技术实现要素:
根据本发明的智能热点打散的方法,包括: 基于人工智能学习模型学习URL的请求量曲线并预测URL的请求量; 将URL的预测请求量大于或等于该URL所对应的第一预定请求量阈值的URL确定为 第一URL,对URL执行第一热点打散操作; 将URL的请求量无法预测且实际请求量大于或等于该URL所对应的第二预定请求 量阈值的URL确定为第二URL,对URL执行第二热点打散操作。 根据本发明的智能热点打散的方法,其对URL执行第一热点打散操作的步骤包括: 将第一URL的请求随机或均匀地分配到多个缓存服务器和/或源站服务器的进程。 根据本发明的智能热点打散的方法,其对URL执行第二热点打散操作的步骤包括: 查找第二URL的落点进程; 将第一URL的新请求随机或均匀地分配到多个缓存服务器和/或源站服务器的进 程中的、除了落点进程之外的进程;和/或 将第一URL的旧请求随机或均匀地重新分配到多个缓存服务器和/或源站服务器 的进程中的、除了落点进程之外的进程。 根据本发明的智能热点打散的方法,其对URL执行第二热点打散操作的步骤还包 括: 确定第二URL的请求文件的大小大于指定文件大小;和/或 4 CN 111585908 A 说 明 书 2/7 页 在落点进程执行完针对第二URL的请求的、获取并发送请求文件或发送请求文件 的响应之后,将第一URL的新请求随机或均匀地分配到多个缓存服务器和/或源站服务器的 进程,和/或,将第一URL的旧请求随机或均匀地重新分配到多个缓存服务器和/或源站服务 器的进程,和/或 基于人工智能学习模型学习URL的请求量曲线并预测URL的请求量的步骤包括: 采用聚类算法对URL进行聚类分析,将相同类别的URL在预设历史时段内的请求量 或实时请求量自动绘制为对应于该类别的URL的请求量曲线,根据该类别的URL的请求量曲 线来预测该类别的URL的请求量。 根据本发明的智能热点打散的装置,包括: 人工智能学习模型,用于学习URL的请求量曲线并预测URL的请求量; 第一热点打散模块,用于将URL的预测请求量大于或等于该URL所对应的第一预定 请求量阈值的URL确定为第一URL,对URL执行第一热点打散操作; 第二热点打散模块,用于将URL的请求量无法预测且实际请求量大于或等于该URL 所对应的第二预定请求量阈值的URL确定为第二URL,对URL执行第二热点打散操作。 根据本发明的智能热点打散的装置,其第一热点打散模块还用于: 将第一URL的请求随机或均匀地分配到多个缓存服务器和/或源站服务器的进程。 根据本发明的智能热点打散的装置,其第二热点打散模块还用于: 查找第二URL的落点进程; 将第一URL的新请求随机或均匀地分配到多个缓存服务器和/或源站服务器的进 程中的、除了落点进程之外的进程;和/或 将第一URL的旧请求随机或均匀地重新分配到多个缓存服务器和/或源站服务器 的进程中的、除了落点进程之外的进程,和/或 人工智能学习模型还用于: 采用聚类算法对URL进行聚类分析,将相同类别的URL在预设历史时段内的请求量 或实时请求量自动绘制为对应于该类别的URL的请求量曲线,根据该类别的URL的请求量曲 线来预测该类别的URL的请求量。 根据本发明的智能热点打散的装置,其第二热点打散模块还用于: 确定第二URL的请求文件的大小大于指定文件大小;和/或 在落点进程执行完针对第二URL的请求的、获取并发送请求文件或发送请求文件 的响应之后,将第一URL的新请求随机或均匀地分配到多个缓存服务器和/或源站服务器的 进程,和/或,将第一URL的旧请求随机或均匀地重新分配到多个缓存服务器和/或源站服务 器的进程。 根据本发明的存储介质,该存储介质上存储有计算机程序,程序被处理器执行时 实现上文所述方法的步骤。 根据本发明的计算机设备,包括存储器、处理器及存储在存储器上并可在处理器 上运行的计算机程序,处理器执行程序时实现上文所述方法的步骤。 根据本发明的上述技术方案,能够自动预测非突发的热点URL请求、从而提前进行 第一种打散操作,能够对不能预测的突发热点URL请求进行第二种打散操作,加快了热点业 务的处理。 5 CN 111585908 A 说 明 书 3/7 页 附图说明 并入到说明书中并且构成说明书的一部分的附图示出了本发明的实施例,并且与 相关的文字描述一起用于解释本发明的原理。在这些附图中,类似的附图标记用于表示类 似的要素。下面描述中的附图是本发明的一些实施例,而不是全部实施例。对于本领域普通 技术人员来讲,在不付出创造性劳动的前提下,可以根据这些附图获得其他的附图。 图1示例性地示出了根据本发明的智能热点打散的方法的示意流程图。 图2示例性地示出了根据本发明的智能热点打散的装置的示意框图。 图3示例性地示出了可以实现根据本发明的智能热点打散的方法的一个实施例的 示意图。 图4示例性地示出了根据本发明的智能热点打散的方法可以使用的人工智能学习 模型所匹配出来的模型图的示例。











