
技术摘要:
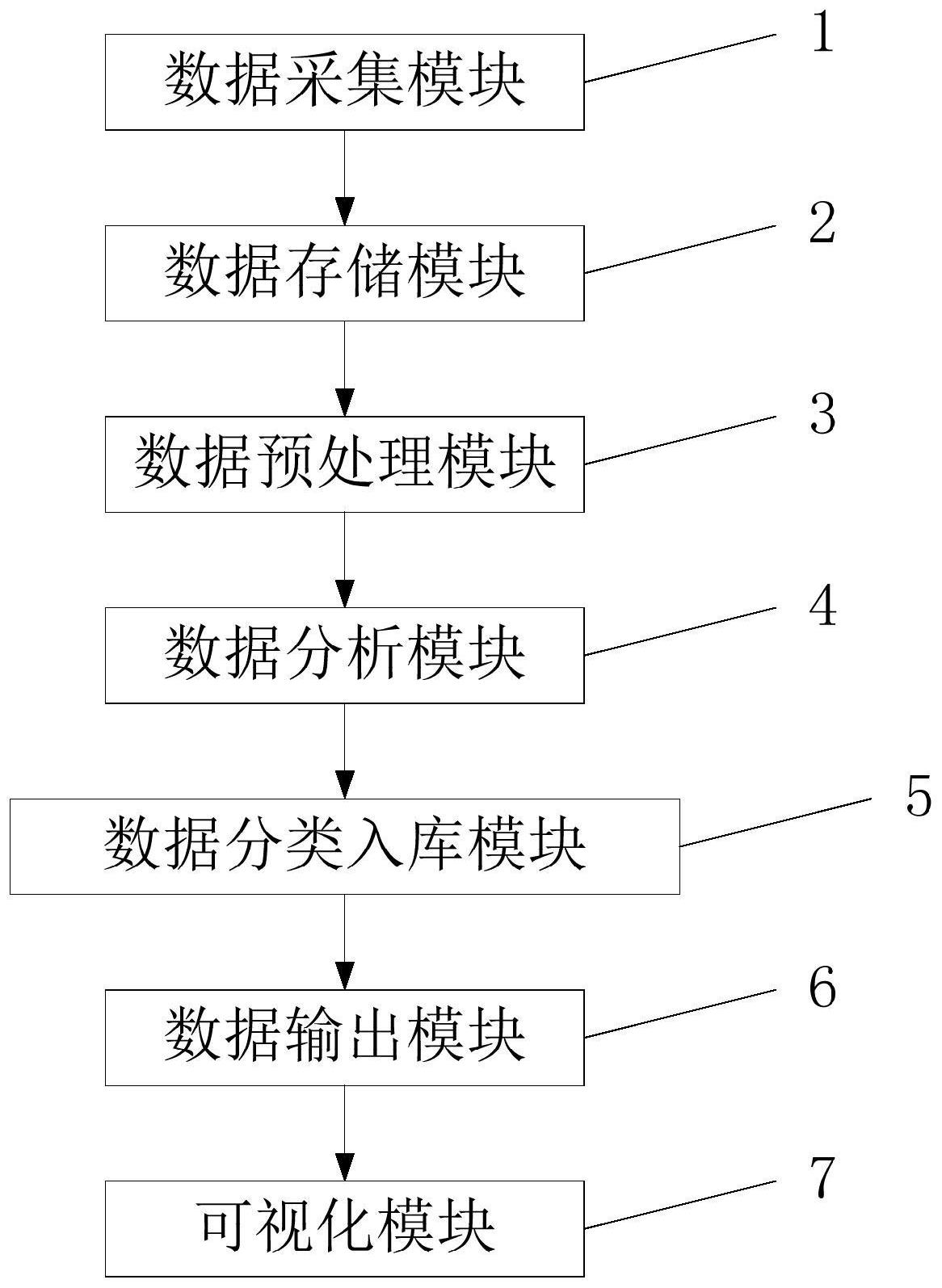
本发明涉及基于Spark的大数据可视化分析系统及其方法,包括数据采集模块,数据采集模块的输出端与数据存储模块的输入端相连接,数据存储模块的输出端与数据预处理模块的输入端相连接,数据预处理模块的输出端与数据分析模块的输入端相连接,数据分析模块的输出端与数据 全部
背景技术:
大数据是当前学术界和产业界的研究热点,正影响着人们日常生活方式、工作习 惯及思考模式,大数据分析是大数据研究领域的核心内容之一。通常,数据的分析过程往往 离不开机器和人的相互协作与优势互补,可以从两方面出发,一是从机器或计算机的角度 出发,强调机器的计算能力和人工智能,以各种高性能处理算法、智能搜索与挖掘算法等为 主要研究内容,另一个从人作为分析主体和需求主体的角度出发,强调基于人机交互的、符 合人的认知规律的分析方法,意图将人所具备的、机器并不擅长的认知能力融入分析过程 中,这一研究分支以大数据可视分析(visual analytics of big data)为主要代表。当大 数据以直观的可视化的图形形式展示在分析者面前时,分析者往往能够一眼洞悉数据背后 隐藏的信息并转化知识以及智慧。 大数据可视化分析是大数据分析不可或缺的重要手段和工具。事实上,在科学计 算可视化领域以及传统的商业智能(business intelligence,简称BI)领域,可视化一直是 重要的方法和手段。如何设计出能集成海量、多源、异构数据且实现数据动态更新的数据中 心框架,如何实现数据标准统一,以完成环境数据的统一规划、集成和管理,提高数据产品 加工和服务能力等,通过数据帮助管理者进行决策的都是难点问题。 有鉴于上述的缺陷,本设计人积极加以研究创新,以期创设基于Spark的大数据可 视化分析系统及其方法,使其更具有产业上的利用价值。
技术实现要素:
为解决上述技术问题,本发明的目的是提供 为实现上述目的,本发明采用如下技术方案: 基于Spark的大数据可视化分析系统,包括数据采集模块,数据采集模块的输出端 与数据存储模块的输入端相连接,数据存储模块的输出端与数据预处理模块的输入端相连 接,数据预处理模块的输出端与数据分析模块的输入端相连接,数据分析模块的输出端与 数据分类入库模块的输入端相连接,数据分类入库模块的输出端与数据输出模块的输入端 相连接,数据输出模块的输出端与可视化模块的输入端相连接。 作为本发明的进一步改进,数据采集模块利用Cloudera提供的分布式日志采集系 统Flume进行数据采集处理。 作为本发明的进一步改进,数据存储模块利用DDB分布系存储系统来进行数据存 储处理。 作为本发明的进一步改进,数据预处理模块利用Spark计算框架对DDB分布系存储 系统上存储的数据进行预处理。 3 CN 111581257 A 说 明 书 2/4 页 作为本发明的进一步改进,数据分析模块获取预处理后的特征数据,对特征数据 进行频繁序列挖掘和聚类分析,得到分析结果。 作为本发明的进一步改进,数据分类入库模块将分析结果传输至Mysql数据库内 进行分类储存。 作为本发明的进一步改进,数据输出模块将Mysql数据库内数据的分析结果传输 至可视化模块,并通过可视化模块进行可视化处理并展示。 基于Spark的大数据可视化分析方法,包括以下步骤: 步骤S1,数据采集:数据采集模块利用Cloudera提供的分布式日志采集系统Flume 进行数据采集处理; 步骤S2,数据存储:数据存储模块利用DDB分布系存储系统来进行数据存储处理; 步骤S3,数据预处理:数据预处理模块利用Spark计算框架对DDB分布系存储系统 上存储的数据进行预处理; 步骤S4,数据分析:数据分析模块获取预处理后的特征数据,对特征数据进行频繁 序列挖掘和聚类分析,得到分析结果; 步骤S5,数据分类入库:数据分类入库模块将分析结果传输至Mysql数据库内进行 分类储存; 步骤S6,数据可视化:数据输出模块将Mysql数据库内数据的分析结果传输至可视 化模块,并通过可视化模块进行可视化处理并展示。 作为本发明的进一步改进,步骤S6中,数据输出模块通过TCP/IP数据协议将Mysql 数据库内数据的分析结果通过可视化模块进行可视化图形或者数字处理并展示。 借由上述方案,本发明至少具有以下优点: 本发明基于Spark的大数据可视化分析系统,可以综合解决在互联网中海量数据 处理的问题,实现数据标准统一,以完成环境数据的统一规划、集成和管理,提高数据产品 加工和服务能力;本发明利用框架中大数据平台的特点,能够有效地处理数据信息,提供数 据的存储和分析以及展示,使数据处理过程更加高效完善,有较强的可扩展性和容错性。 上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段, 并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。 附图说明 为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附 图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对 范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这 些附图获得其他相关的附图。 图1是本发明基于Spark的大数据可视化分析系统的结构示意图。 其中,图中各附图标记的含义如下。 1数据采集模块 2数据存储模块 3数据预处理模块 4数据分析模块 5数据分类入库模块 6数据输出模块 7可视化模块 4 CN 111581257 A 说 明 书 3/4 页











