
技术摘要:
本发明公开了一种基于充足视觉信息与文本信息的图像描述方法,本发明通过充将前两层的注意力作为输入,可以提高模型中所包含的视觉信息,充足的文本信息充分的利用隐含状态同时还一次性预测接下来的三个单词,可以提高模型中所包含的文本信息。将视觉信息和文本信息结 全部
背景技术:
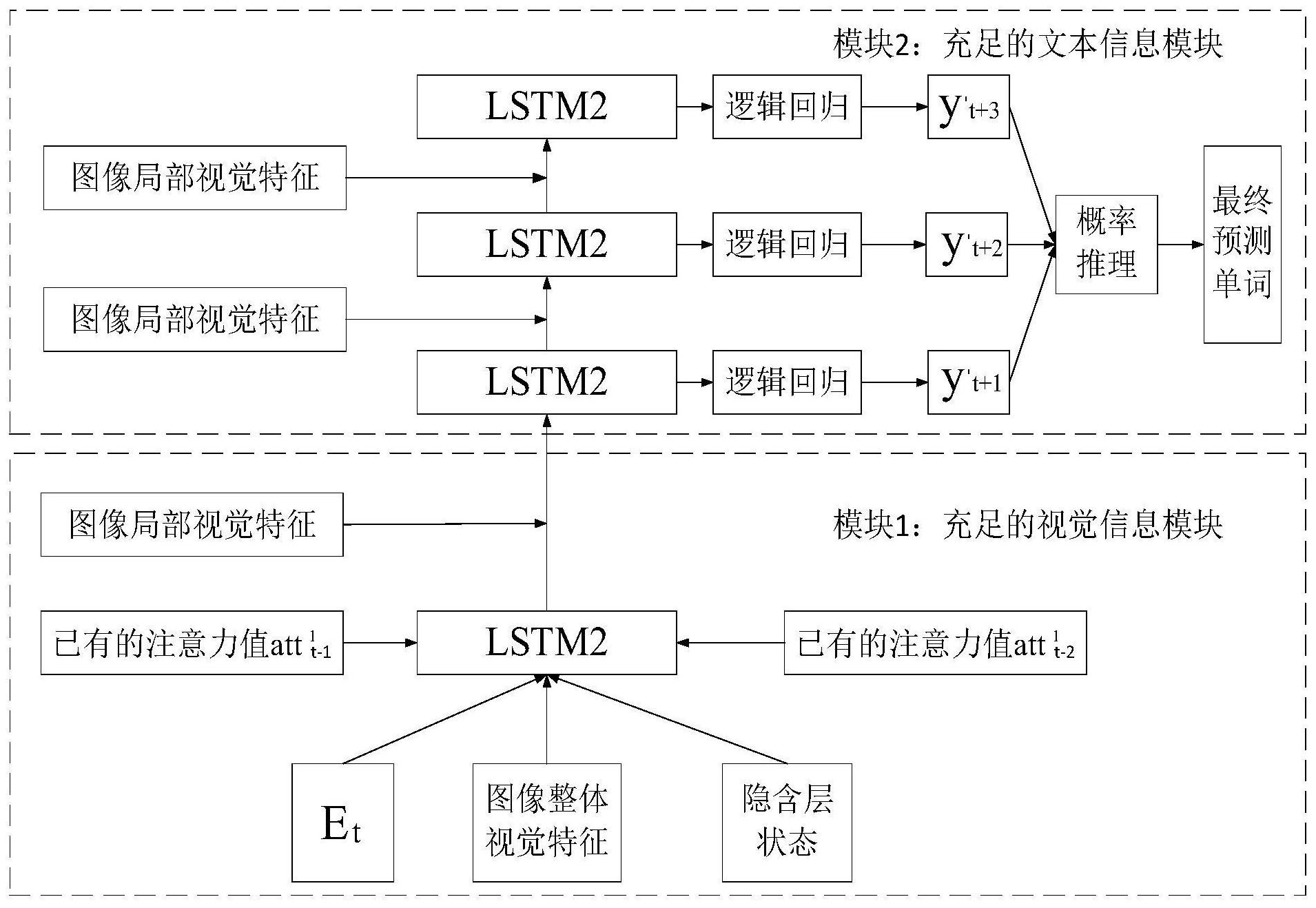
早期的图像描述方法可以分为基于模板的图像描述方法和基于检索的图像描述 方法,受深度学习在计算机视觉和机器翻译任务上的成功应用,基于深度学习的图像描述 方法也得到广泛提出。基于模板的图像描述方法是先利用图像标注技术为物体、物体场景 以及组成部分进行标注,然后选择与图像内容描述场景相关的句子作为表达模板,将提取 的图像特征填入模板,继而得到图像的描述语句。基于模板的图像描述方法虽然能够描述 图像的内容,但是在一定程度上限制了描述语句的多样性,生成的图像描述不够灵活、新 颖;基于检索的图像描述方法将文本和图像映射到一个共同语义空间,结合相似度的计算 方法,对图像内容和文本意义的关系程度进行排名,检测出与测试图像关系最为接近的文 本作为测试图像的最终文本描述。基于检索的图像描述方法虽然可以快速的生成语法准确 的描述文本,但是也增加了模型的复杂度和处理过程,同时该方法的描述是从相似度图像 的描述迁移而来,因此生成的描述有可能偏离图像的真是内容;基于深度学习图像描述模 型采用端到端的训练方法,首先利用深度卷积神经网络对图像中的特征进行建模,然后利 用循环神经网络对图像的文本信息进行建模,最后将图像信息和文本信息映射到同一个循 环神经网络中,利用图像信息指导文本句子的生成。该方法没有任何模板、规则的约束,能 自动推断出测试图像和其相应的文本,自动的从大量的训练集中去学习图像和文本信息, 生成更灵活、更新颖的文本描述,同时基于深度学习的图像文本描述方法还可以描述从未 描述过的图像内容。综上所述,基于深度学习的图像描述算法已经成为图像描述的主流方 法。 在过去的几年中,研究人员已经提出了许多基于深度学习的“编码-解码”模型来 解决这个问题,其中基于卷积神经网络的编码器负责从图像中提取视觉特征信息,基于循 环神经网络的解码器负责利用已有的视觉特征信息生成对应的文本描述语句。事实证明, 注意力机制在图像描述方面有巨大的进步,同时已应用于几乎所有最新的图像描述算法 中。注意模块着眼于在当前的图像特征信息和对应的单词之间建立联系,在每个时间步,注 意力模块根据给定单词的相关性权重来生成对应的单词。软注意力方法将所有特征向量的 加权平均值作为注意力结果,而硬注意力方法则对相关权重进行采样作为注意力结果。尽 管解码器中的注意力模块可以为文本生成提供精确有效的视觉信息,但是现有的注意力方 法只是将当前单词的隐含状态h_t作为输入,并仅针对输出结果h_(t 1)计算对应的注意力 结果,这种注意机制忽略了相邻单词之间的视觉相关性。基于注意力机制的图像描述算法 通常需要使用额外数据集上预训练的CNN模型来提取图像的视觉特征。预训练CNN模型的通 道级特征在对象识别和场景识别中表现出强大的能力。随着新数据集Visual Genome的出 现,基于检测的编码器可以更加高效的的提取图像的视觉特征,例如Peter等人在Visual 4 CN 111582287 A 说 明 书 2/7 页 Genome数据集上对Fast R-CNN进行了预训练,并以高置信度检测到的区域向量作为最终特 征,这比CNN的预训练特征具有更加明显的优势。虽然已有的相关算法已经显著的提高了图 像描述算法的性能,但是所有这些努力都集中在将更多信息嵌入到编码的特征上,并没有 解决模型中视觉注意力的相关性问题。因此我们提出了充足的视觉信息模块,它充分的考 虑了先前注意力向量对当前注意力向量的影响,充分的建立了视觉注意力之间的相关,解 决了视觉信息利用不充分的问题。
技术实现要素:
本发明的目的在于克服上述不足,提供一种基于充足视觉信息与文本信息的图像 描述方法,通过利用充足的视觉信息模块来提高模型中所包含的视觉信息,利用充足的文 本信息模块来提高模型中所包含的文本信息,最终显著的提高了图像描述模型的整体性 能。 为了达到上述目的,本发明包括以下步骤: 步骤一,输入图像和对应的文本描述语句; 步骤二,提取图像中包含的视觉特征信息,利用注意力机制生成对应的注意力结 果,并且将前两层的注意力值与当前的隐含层状态结合在一起作为当前输入;; 步骤三,对图像特征进行多次预测生成多个预测单词和对应的预测概率; 步骤四,对预测单词和预测概率进行推理,得到准确的预测单词; 步骤五,将所有准确的预测单词结合在一起,生成的图像最终的描述语句。 步骤二中,生成对应的注意力结果的具体方法如下: 将当前区域的隐藏状态ht与内置图像的注意力attt-1和attt-2相串联,作为注意力 函数fatt的输入,则得到新的注意力结果attt表示为: attt=fatt(V,ht*attt-1*attt-2) 其中*表示串联,ht*attt-1*attt-2可以表示成Ht,Ht为文本信息中不同特征向量vi 的重要性。 步骤三的具体方法如下: 将文本信息中的隐含状态 和视觉特征V,结合注意力函数fatt进行如下运算: 其中*表示串联, 是输出的隐藏状态; 将隐藏状态 进行逻辑回归,得到预测结果y′t 1的概率 步骤四的具体方法如下: 损失loss平等的对所有预测的概率进行处理,并将所有预测概率结合在一起,预 测下一个单词; 损失loss的函数为: 5 CN 111582287 A 说 明 书 3/7 页 loss=loss1 loss2 loss2 通过下式将所有预测概率结合在一起: 其中 由 计算而得, 由 计算得到, 由 计算得到,λ1和λ2是权衡 系数用来平衡 和 与现有技术相比,本发明通过充将前两层的注意力作为输入,可以提高模型中所 包含的视觉信息,充足的文本信息充分的利用隐含状态同时还一次性预测接下来的三个单 词,可以提高模型中所包含的文本信息。将视觉信息和文本信息结合在一起,只需在一个时 间步中为下一个时间步保留三个注意力结果。通过引入充足的视觉信息和文本信息,就能 够根据充足的视觉信息与文本信息更加准确的预测下一个单词,从而显著的提高模型的图 像描述效果。 附图说明 图1为本发明的架构图; 图2为本发明中充足的视觉信息模块图; 图3为本发明中充足的文本信息模块图; 图4为本发明中充足的视觉信息与文本信息模型图。











