
技术摘要:
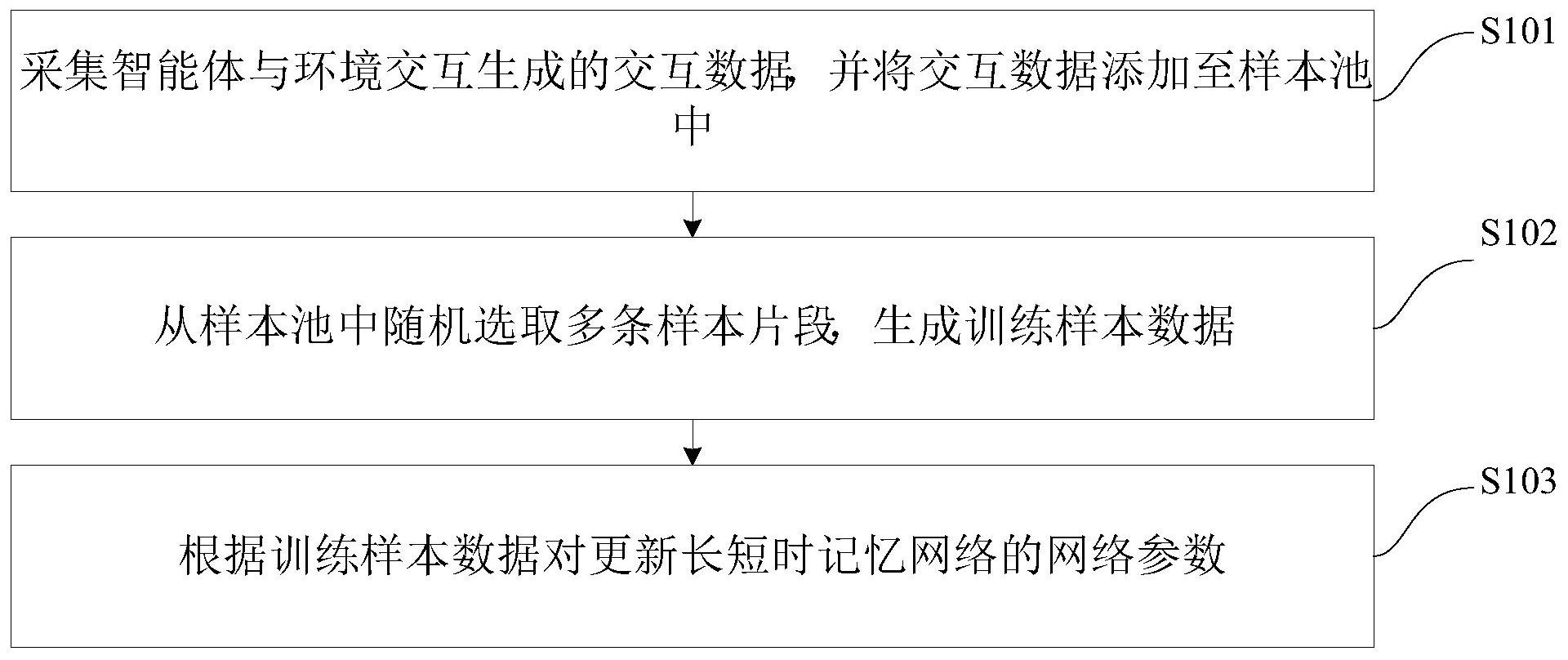
本发明公开了一种状态部分可观测强化学习算法的高效采样更新方法及装置,其中,方法包括:采集智能体与环境交互生成的交互数据,并将交互数据添加至样本池中;从样本池中随机选取多条样本片段,生成训练样本数据;根据训练样本数据对更新长短时记忆网络的网络参数。根 全部
背景技术:
在强化学习中,智能体与环境进行交互的过程可概括为一个马氏决策过程,在每 一个离散时刻,智能体观测到环境的状态,并根据学得的策略以及此观测值选择其做出的 动作。然而,现实世界中的任务常常由于传感器的限制,无法获取完全信息而导致只能观测 到部分状态信息,即智能体无法直接感知到环境的完整状态信息,只能得到部分状态的观 测值。 相关技术中,将深度强化学习算法与长短时记忆网络(Long Short-Term Memory, LSTM)相结合,即将智能体与环境交互的历史信息进行整合,作为当前的记忆,智能体根据 此记忆选择动作。由于记忆信息与状态信息相比具有强烈的时序相关性,传统基于状态信 息的采样更新方式在状态部分可观强化学习算法中不再适用,不但更新效率低,且无法保 证更新的准确性,体验较差。
技术实现要素:
本发明旨在至少在一定程度上解决相关技术中的技术问题之一。 为此,本发明的一个目的在于提出一种状态部分可观测强化学习算法的高效采样 更新方法,该方法可以提高更新效率,且有效保证更新的准确性,提升算法的使用体验。 本发明的另一个目的在于提出一种状态部分可观测强化学习算法的高效采样更 新装置。 为达到上述目的,本发明一方面实施例提出了一种状态部分可观测强化学习算法 的高效采样更新方法,包括以下步骤:采集智能体与环境交互生成的交互数据,并将所述交 互数据添加至样本池中;从所述样本池中随机选取多条样本片段,生成训练样本数据;根据 所述训练样本数据对更新长短时记忆网络的网络参数。 本发明实施例的状态部分可观测强化学习算法的高效采样更新方法,解决目前存 在的采样更新方式存在效率低下,使得算法学习速率大幅降低的问题,可以极大缩短算法 训练时间、提高算法表现,不但提高更新效率,而且有效保证更新的准确性,提升算法的使 用体验。 另外,根据本发明上述实施例的状态部分可观测强化学习算法的高效采样更新方 法还可以具有以下附加的技术特征: 进一步地,在本发明的一个实施例中,所述采集智能体与环境交互生成的交互数 据,并将所述交互数据添加至样本池中,包括:根据所述智能体接收的环境当前时刻的观测 值、上一时刻记忆值、上一时刻动作,长短时记忆网络计算当前时刻记忆值;通过智能体全 连接网络根据所述当前时刻记忆值计算当前时刻选择的动作;通过所述智能体与所述环境 4 CN 111582439 A 说 明 书 2/8 页 交互做出所述动作,且所述环境根据所述智能体动作转移至下一状态并返回给所述智能体 奖励信号、下一时刻的观测值、交互过程是否终止的判断值;将本时步交互过程中产生的所 述交互数据添加至所述样本池中。 进一步地,在本发明的一个实施例中,所述从所述样本池中随机选取多条样本片 段,生成训练样本数据,包括:获取所述样本池中样本的数量,并随机选取n个片段首时步的 索引;根据每条片段首时步的索引,在所述样本池中取出对应样本片段,添加至训练样本 中。 进一步地,在本发明的一个实施例中,所述根据所述训练样本数据对更新长短时 记忆网络的网络参数,包括:更新每条片段数据的记忆值,并进行神经网络的前向传播,得 到前向传播结果;根据所述前向传播结果计算损失函数,并进行梯度的反向传播;根据梯度 以及学习率的大小对所述网络参数进行更新。 进一步地,在本发明的一个实施例中,所述更新每条片段数据的记忆值,并进行神 经网络的前向传播,得到前向传播结果,包括:将所述每片段首时步的上一时刻记忆值初始 化为样本池中存储值;根据上一时刻动作、上一时刻记忆值、当前时刻观测值,由最新长短 时记忆网络计算当前时刻记忆,并将更新的记忆值传输给后续神经网络;判断交互过程是 否终止,其中,若终止,则将记忆值置为0,否则所述记忆值保持不变,并将所述记忆值传输 给下一时刻。 为达到上述目的,本发明另一方面实施例提出了一种状态部分可观测强化学习算 法的高效采样更新装置,包括:添加模块,用于采集智能体与环境交互生成的交互数据,并 将所述交互数据添加至样本池中;获取模块,用于从所述样本池中随机选取多条样本片段, 生成训练样本数据;更新模块,用于根据所述训练样本数据对更新长短时记忆网络的网络 参数。 本发明实施例的状态部分可观测强化学习算法的高效采样更新装置,解决目前存 在的采样更新方式存在效率低下,使得算法学习速率大幅降低的问题,可以极大缩短算法 训练时间、提高算法表现,不但提高更新效率,而且有效保证更新的准确性,提升算法的使 用体验。 另外,根据本发明上述实施例的状态部分可观测强化学习算法的高效采样更新装 置还可以具有以下附加的技术特征: 进一步地,在本发明的一个实施例中,所述添加模块包括:第一计算单元,用于根 据所述智能体接收的环境当前时刻的观测值、上一时刻记忆值、上一时刻动作,长短时记忆 网络计算当前时刻记忆值;第二计算单元,用于通过智能体全连接网络根据所述当前时刻 记忆值计算当前时刻选择的动作;判断单元,用于通过所述智能体与所述环境交互做出所 述动作,且所述环境根据所述智能体动作转移至下一状态并返回给所述智能体奖励信号、 下一时刻的观测值、交互过程是否终止的判断值;第一添加单元,用于将本时步交互过程中 产生的所述交互数据添加至所述样本池中。 进一步地,在本发明的一个实施例中,所述获取模块包括:获取单元,用于获取所 述样本池中样本的数量,并随机选取n个片段首时步的索引;第二添加单元,用于根据每条 片段首时步的索引,在所述样本池中取出对应样本片段,添加至训练样本中。 进一步地,在本发明的一个实施例中,所述更新模块包括:第一更新单元,用于更 5 CN 111582439 A 说 明 书 3/8 页 新每条片段数据的记忆值,并进行神经网络的前向传播,得到前向传播结果;第三计算单 元,用于根据所述前向传播结果计算损失函数,并进行梯度的反向传播;第二更新单元,用 于根据梯度以及学习率的大小对所述网络参数进行更新。 进一步地,在本发明的一个实施例中,所述第一更新单元具体用于将所述每片段 首时步的上一时刻记忆值初始化为样本池中存储值,并且根据上一时刻动作、上一时刻记 忆值、当前时刻观测值,由最新长短时记忆网络计算当前时刻记忆,并将更新的记忆值传输 给后续神经网络,以及判断交互过程是否终止,其中,若终止,则将记忆值置为0,否则所述 记忆值保持不变,并将所述记忆值传输给下一时刻。 本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变 得明显,或通过本发明的实践了解到。 附图说明 本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得 明显和容易理解,其中: 图1为根据本发明实施例的状态部分可观测强化学习算法的高效采样更新方法的 流程图; 图2为根据本发明一个实施例的智能体与环境交互和智能体内部神经网络结构的 示意图; 图3为根据本发明一个实施例的长短时记忆网络按时间步展开示意图; 图4为根据本发明一个实施例的样本存储方式的示意图; 图5为根据本发明一个具体实施例的状态部分可观测强化学习算法的高效采样更 新方法的流程图; 图6为根据本发明实施例的状态部分可观测强化学习算法的高效采样更新装置的 方框示意图。











