
技术摘要:
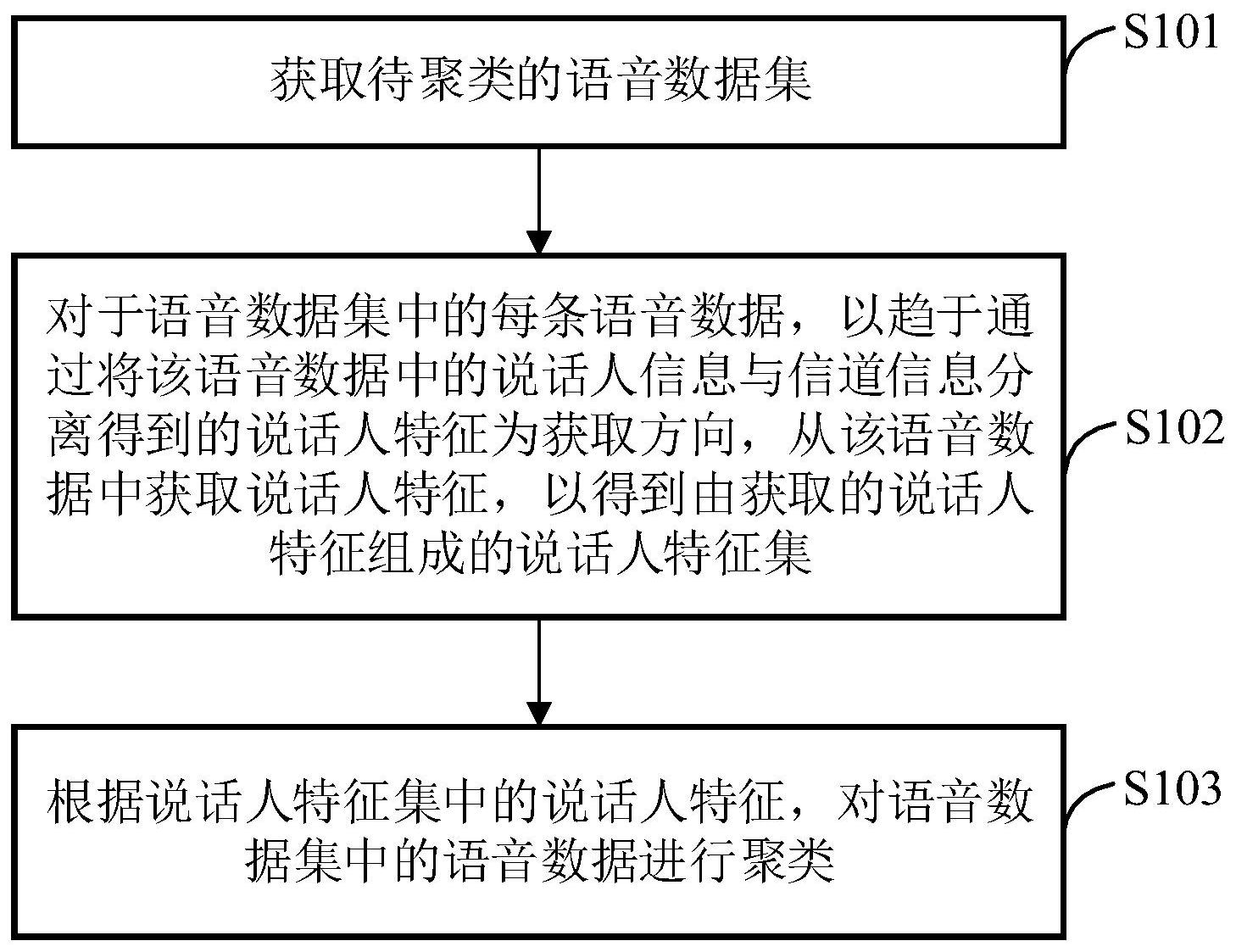
本申请提供了一种说话人聚类方法、装置、设备及存储介质,方法包括:获取语音数据集;对于语音数据集中的每条语音数据,以趋于通过该语音数据中的说话人信息与信道信息分离得到的说话人特征为获取方向,从该语音数据中获取说话人特征,得到由获取的说话人特征组成的说 全部
背景技术:
在某些应用场景中,需要将语音数据集中的语音数据按说话人区分开来,即,将同 一说话人的语音数据聚为一类。 比如,在应用语音识别的场景中,出现了多个说话人,多个说话人的语音内容共同 出现在了一整段语音中,这就需要将整段语音按说话人切分为多个语音段,进而将同一说 话人的语音段聚在一起。 然而,如何对语音数据集中的语音数据进行准确聚类是当前亟需解决的问题。
技术实现要素:
有鉴于此,本申请提供了一种说话人聚类方法、装置、设备及存储介质,用以准确 地将语音数据集中属于同一说话人的语音数据聚为一类,其技术方案如下: 一种说话人聚类方法,包括: 获取待聚类的语音数据集; 对于所述语音数据集中的每条语音数据,以趋于通过将该语音数据中的说话人信 息与信道信息分离得到的说话人特征为获取方向,从该语音数据中获取说话人特征,以得 到由获取的说话人特征组成的说话人特征集; 根据所述说话人特征集中的说话人特征,对所述语音数据集中的语音数据进行聚 类。 可选的,所述以趋于通过将该语音数据中的说话人信息与信道信息分离得到的说 话人特征为获取方向,从该语音数据中获取说话人特征,包括: 利用预先建立的说话人特征提取模型,从该语音数据中获取说话人特征; 其中,所述说话人特征提取模型采用标注有真实说话人标签的语音样本训练得 到,所述说话人特征提取模型的训练目标为,使根据所述语音样本获取的说话人特征确定 的说话人标签,趋于所述语音样本对应的真实说话人标签,以及,通过正交分解使所述语音 样本中的说话人信息与信道信息分离。 可选的,所述利用预先建立的说话人特征提取模型,从该语音数据获取说话人特 征,包括: 利用所述说话人特征提取模型,从该语音数据中获取帧级别说话人特征,并根据 所述帧级别说话人特征确定一阶统计量和二阶统计量; 利用所述说话人特征提取模型,从所述一阶统计量和所述二阶统计量中获取第一 向量和第二向量,并根据所述第一向量和所述第二向量确定说话人特征;其中,所述第一向 量由所述一阶统计量中的一部分和所述二阶统计量中的一部分拼接而成,所述第二向量由 5 CN 111599346 A 说 明 书 2/15 页 所述一阶统计量中的另一部分和所述二阶统计量中的另一部分拼接而成,所述第一向量与 所述第二向量正交。 可选的,所述根据所述第一向量和所述第二向量确定说话人特征,包括: 分别从所述第一向量和所述第二向量中提取说话人信息,以得到包含说话人信息 的第三向量和包含说话人信息的第四向量; 根据所述第一向量和所述第二向量确定所述第三向量和所述第四向量分别对应 的权重; 按所述第三向量和所述第四向量分别对应的权重,对所述第三向量和所述第四向 量加权求和,得到加权求和后的向量; 根据所述加权求和后的向量确定说话人特征。 可选的,建立所述说话人特征提取模型的过程包括: 对于所述语音样本集中的每个语音样本: 利用说话人特征提取模型,从该语音样本中获取帧级别说话人特征,并根据所述 帧级别说话人特征确定一阶统计量和二阶统计量; 利用说话人特征提取模型,从所述一阶统计量和所述二阶统计量中获取第一向量 和第二向量,并根据所述第一向量和所述第二向量确定说话人特征;其中,所述第一向量由 所述一阶统计量中的一部分和所述二阶统计量中的一部分拼接而成,所述第二向量由所述 一阶统计量中的另一部分和所述二阶统计量中的另一部分拼接而成; 根据确定的说话人特征确定说话人标签,作为该语音样本对应的预测说话人标 签; 根据所述语音样本集中每个语音样本对应的预测说话人标签和真实说话人标签, 以及每个语音样本对应的第一向量与第二向量的正交化程度,更新说话人特征提取模型的 参数。 可选的,所述根据所述语音样本集中每个语音样本对应的预测说话人标签和真实 说话人标签,以及每个语音样本对应的第一向量与第二向量的正交化程度,更新说话人特 征提取模型的参数,包括: 对于所述语音样本集中的每个语音样本,根据该语音样本对应的预测说话人标签 和真实说话人标签,确定该语音样本对应的说话人预测损失; 将所述语音样本集中各语音样本分别对应的说话人预测损失求和,求和得到的损 失作为说话人特征提取模型的说话人预测损失; 对于所述语音样本集中的每个语音样本,确定该语音样本对应的第一向量与第二 向量的余弦距离,作为该语音样本对应的正交损失; 将所述语音样本集中各语音样本分别对应的正交损失求和,求和得到的损失作为 说话人特征提取模型的正交损失; 根据所述说话人特征提取模型的说话人预测损失和所述说话人特征提取模型的 正交损失,更新说话人特征提取模型的参数。 可选的,所述根据所述说话人特征集中的说话人特征,对所述语音数据集中的语 音数据进行聚类,包括: 对所述说话人特征集中的说话人特征进行聚类,以将同一说话人的说话人特征聚 6 CN 111599346 A 说 明 书 3/15 页 为一类,得到所述说话人特征集中说话人特征的聚类结果; 根据所述说话人特征集中说话人特征的聚类结果,获得所述语音数据集中语音数 据的聚类结果。 可选的,所述对所述说话人特征集中的说话人特征进行聚类,包括: 采用预设的聚类算法对所述说话人特征集中的说话人特征进行粗聚类,获得粗聚 类结果,其中,所述聚类算法为不需要预先设定类别数的聚类算法; 在所述粗聚类结果的基础上,根据类内距离和类间距离对所述说话人特征集中的 说话人特征进行细聚类,得到细聚类结果,作为所述说话人特征集中说话人特征的聚类结 果,其中,所述类内距离为同一类内的说话人特征与该类的类中心的距离,所述类间距离为 两个不同类之间的距离。 可选的,所述在所述粗聚类结果的基础上,根据类内距离和类间距离对所述说话 人特征集中的说话人特征进行细聚类,包括: 对于所述粗聚类结果中的每个类中的每个说话人特征,根据该说话人特征与其所 在类的类中心的距离,确定该说话人特征是否属于其所在的类,若是,则将该说话人特征保 留至其所在的类,若否,则将该说话人特征从其所在的类中移出,并将该说话人特征划分至 一个新的类中; 对于获得的所有类,根据类间距离进行类合并。 可选的,所述聚类算法根据所述多个说话人特征中两两说话人特征之间的欧式距 离进行聚类,所述类内距离和所述类间距离为余弦距离。 一种说话人聚类装置,包括:语音数据获取模块、说话人特征获取模块和说话人聚 类模块; 所述语音数据获取模块,用于获取待聚类的语音数据集; 所述说话人特征获取模块,用于对于所述语音数据集中的每条语音数据,以趋于 通过将该语音数据中的说话人信息与信道信息分离得到的说话人特征为获取方向,从该语 音数据中获取说话人特征,以得到由获取的说话人特征组成的说话人特征集; 所述说话人聚类模块,用于根据所述说话人特征集中的说话人特征,对所述语音 数据集中的语音数据进行聚类。 可选的,所述说话人特征获取模块,具体用于利用预先建立的说话人特征提取模 型,从该语音数据中获取说话人特征; 其中,所述说话人特征提取模型采用标注有真实说话人标签的语音样本训练得 到,所述说话人特征提取模型的训练目标为,使根据所述语音样本获取的说话人特征确定 的说话人标签,趋于所述语音样本对应的真实说话人标签,以及,通过正交分解使所述语音 样本中的说话人信息与信道信息分离。 可选的,所述说话人聚类模块包括:说话人特征聚类模块和聚类结果获取模块; 所述说话人特征聚类模块,用于对所述说话人特征集中的说话人特征进行聚类, 以将同一说话人的说话人特征聚为一类,得到所述说话人特征集中说话人特征的聚类结 果; 所述聚类结果获取模块,用于根据所述说话人特征集中说话人特征的聚类结果, 获得所述语音数据集中语音数据的聚类结果。 7 CN 111599346 A 说 明 书 4/15 页 可选的,所述说话人特征聚类模块包括:粗聚类子模块和细聚类子模块; 所述粗聚类子模块,用于采用预设的聚类算法对所述说话人特征集中的说话人特 征进行粗聚类,获得粗聚类结果,其中,所述聚类算法为不需要预先设定类别数的聚类算 法; 所述细聚类子模块,用于在所述粗聚类结果的基础上,根据类内距离和类间距离 对所述说话人特征集中的说话人特征进行细聚类,得到细聚类结果,作为所述说话人特征 集中说话人特征的聚类结果,其中,所述类内距离为同一类内的说话人特征与该类的类中 心的距离,所述类间距离为两个不同类之间的距离。 一种说话人聚类设备,包括:存储器和处理器; 所述存储器,用于存储程序; 所述处理器,用于执行所述程序,实现上述任一项所述的说话人聚类方法的各个 步骤。 一种可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理 器执行时,实现上述任一项所述的说话人聚类方法的各个步骤。 经由上述方案可知,本申请提供的说话人聚类方法,在获得待聚类的语音数据集 后,对于语音数据集中的每条语音数据,以趋于通过将该语音数据中的说话人信息与信道 信息分离得到的说话人特征为获取方向,从该语音数据中获取说话人特征,以得到由获取 的说话人特征组成的说话人特征集,然后根据说话人特征集中的说话人特征,对语音数据 集中的语音数据进行聚类。可以理解是,将语音数据中的说话人信息与信道信息分离,可以 提取到包含高纯度说话人信息的说话人特征,而以该说话人特征为获取方向,获取到的说 话人特征同样包含较高纯度的说话人信息,也就是说,以趋于通过将语音数据中的说话人 信息与信道信息分离得到的说话人特征为获取方向,从语音数据中获取的说话人特征能够 较好地表征该语音数据对应的说话人(或者说能够较好地同其他说话人区分开来),根据这 样的说话人特征对语音数据聚类,很容易将不同说话人的语音数据区分开来,而不易把不 同说话人的语音数据聚在一起,因此,能够获得比较准确的聚类结果。 附图说明 为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现 有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本 发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据 提供的附图获得其他的附图。 图1为本申请实施例提供的说话人聚类方法的流程示意图; 图2为本申请实施例提供的建立说话人特征提取模型的流程示意图; 图3为本申请实施例提供的说话人特征提取模型的一拓扑结构示意图; 图4为本申请实施例提供的利用预先建立的说话人特征提取模型,从语音数据获 取说话人特征的流程示意图; 图5为本申请实施例提供的对说话人特征集中的说话人特征进行聚类的流程示 意; 图6为本申请实施例提供的说话人聚类装置的结构示意图; 8 CN 111599346 A 说 明 书 5/15 页 图7为本申请实施例提供的说话人聚类设备的结构示意图。











