
技术摘要:
本申请涉及人工智能领域内的一种数据聚类的处理方法、装置、计算机设备和存储介质。所述方法包括:获取数据样本;所述数据样本是聚类业务中聚类对象的样本;通过聚类模型,映射所述数据样本为样本特征;所述样本特征包括样本类别特征和样本类内风格特征;确定所述数据 全部
背景技术:
人工智能(Artificial Intelligence,AI)是一门综合学科,涉及领域广泛,既有 硬件层面的技术也有软件层面的技术。人工智能软件技术的其中一个重要方向是机器学 习。聚类分析是机器学习的一种常用技术。图像、文本、语音等数据类型,均可以作为聚类的 对象。通过聚类,可以将相似的对象归为同一类别,将不相似的对象归为不同类别。 在传统的方式中,通过学习数据样本的标签特征,将标签特征作为聚类结果。但是 对于互联网中海量的数据,如果进行人工标注将会消耗大量的人力资源。因此,如何在没有 人工标注的情况下准确完成数据聚类成为目前需要解决的一个技术问题。
技术实现要素:
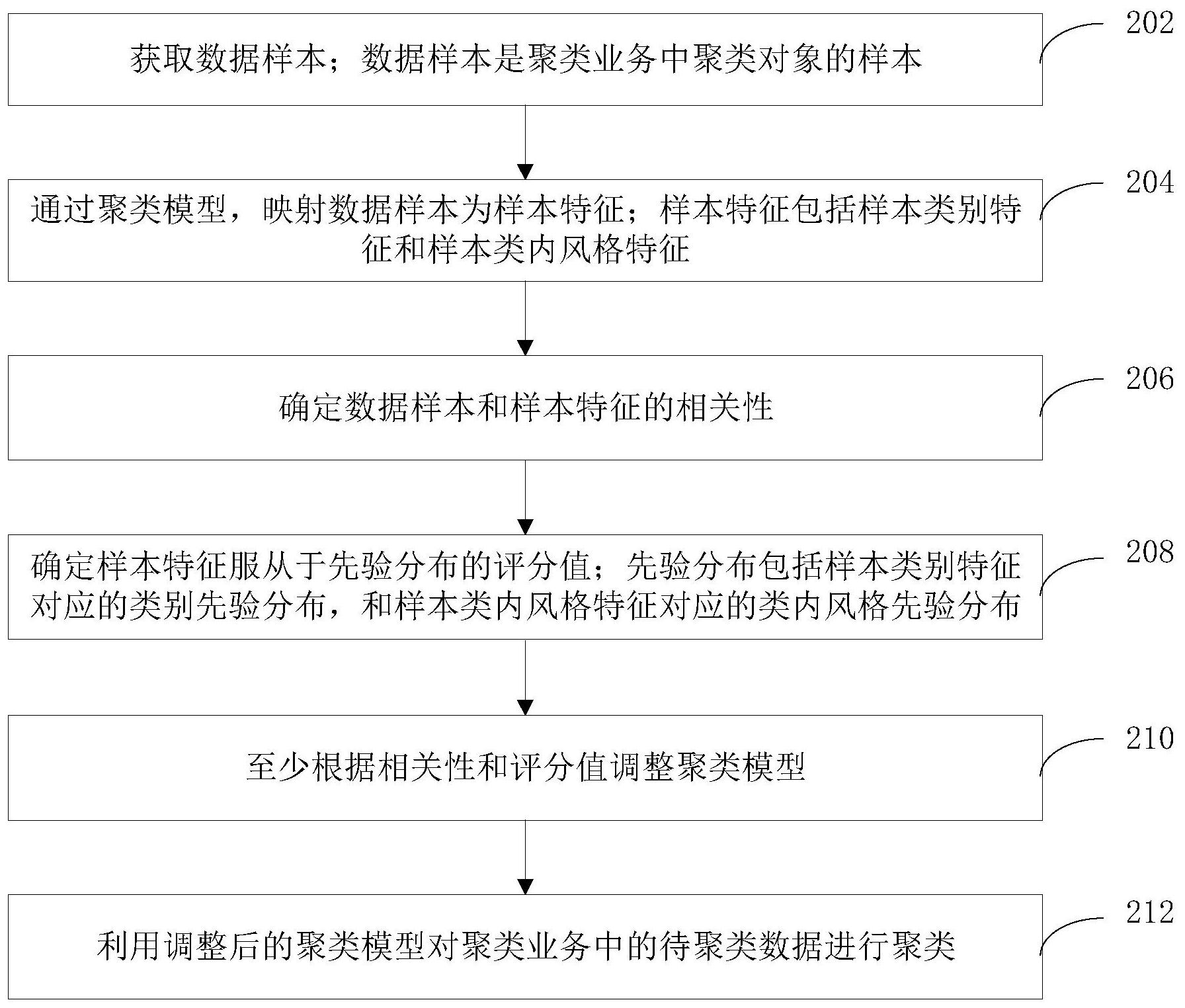
基于此,有必要针对上述技术问题,提供一种能够在没有人工标注的情况下准确 完成数据聚类的数据聚类的处理方法、装置、计算机设备和存储介质。 一种数据聚类的处理方法,所述方法包括: 获取数据样本;所述数据样本是聚类业务中聚类对象的样本; 通过聚类模型,映射所述数据样本为样本特征;所述样本特征包括样本类别特征 和样本类内风格特征; 确定所述数据样本和所述样本特征的相关性; 确定所述样本特征服从于先验分布的评分值;所述先验分布包括所述样本类别特 征对应的类别先验分布,和所述样本类内风格特征对应的类内风格先验分布; 至少根据所述相关性和所述评分值调整所述聚类模型; 利用调整后的聚类模型对聚类业务中的待聚类数据进行聚类。 一种数据聚类的处理装置,所述装置包括: 第一获取模块,用于获取数据样本;所述数据样本是聚类业务中聚类对象的样本; 特征映射模块,用于通过聚类模型,映射所述数据样本为样本特征;所述样本特征 包括样本类别特征和样本类内风格特征; 相关性识别模块,用于确定所述数据样本和所述样本特征的相关性; 先验分布评分模块,用于确定所述样本特征服从于先验分布的评分值;所述先验 分布包括所述样本类别特征对应的类别先验分布,和所述样本类内风格特征对应的类内风 格先验分布; 聚类训练模块,用于至少根据所述相关性和所述评分值调整所述聚类模型;利用 调整后的聚类模型对聚类业务中的待聚类数据进行聚类。 一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在 5 CN 111598153 A 说 明 书 2/16 页 于,所述处理器执行所述计算机程序时实现以下步骤: 获取数据样本;所述数据样本是聚类业务中聚类对象的样本; 通过聚类模型,映射所述数据样本为样本特征;所述样本特征包括样本类别特征 和样本类内风格特征; 确定所述数据样本和所述样本特征的相关性; 确定所述样本特征服从于先验分布的评分值;所述先验分布包括所述样本类别特 征对应的类别先验分布,和所述样本类内风格特征对应的类内风格先验分布; 至少根据所述相关性和所述评分值调整所述聚类模型; 利用调整后的聚类模型对聚类业务中的待聚类数据进行聚类。 一种计算机可读存储介质,存储有计算机程序,其特征在于,所述计算机程序被处 理器执行时实现以下步骤: 获取数据样本;所述数据样本是聚类业务中聚类对象的样本; 通过聚类模型,映射所述数据样本为样本特征;所述样本特征包括样本类别特征 和样本类内风格特征; 确定所述数据样本和所述样本特征的相关性; 确定所述样本特征服从于先验分布的评分值;所述先验分布包括所述样本类别特 征对应的类别先验分布,和所述样本类内风格特征对应的类内风格先验分布; 至少根据所述相关性和所述评分值调整所述聚类模型; 利用调整后的聚类模型对聚类业务中的待聚类数据进行聚类。 上述数据聚类的处理方法、装置、计算机设备和存储介质,对于聚类业务中聚类对 象的数据样本,不需要执行额外的聚类算法,也无需生成真实图像与原图图像进行比对,通 过确定数据样本与样本特征之间的相关性,以及对样本类别特征引入类别先验分布,对样 类内风格特征引入类内风格先验分布,以确定样本特征服从于先验分布的评分值,由此利 用相关性和评分对聚类模型进行训练,可以有效改善聚类模型对样本特征的学习。由于聚 类模型学习到的特征分布靠近先验分布,并且对样本类别特征与样本类内风格特征进行有 效解耦,由此使得调整后的聚类模型能够根据待聚类数据的类别特征即可快速准确得到对 应的聚类类别。从而实现了在无需人工标注的情况下有效提高数据聚类的精度。 一种数据聚类的处理,所述方法包括: 获取聚类业务中的待聚类数据; 通过编码器,将所述待聚类数据编码为数据特征;所述编码器,是至少根据相关性 和评分值训练得到的;所述相关性,是数据编码器将所述数据样本编码所得的样本特征,通 过判别器对所述数据样本与所述样本特征间进行相关判别的结果;所述评分值是通过评价 器对所述样本特征服从先验分布的评分结果;所述样本特征包括样本类别特征和样本类内 风格特征;所述先验分布包括所述样本类别特征对应的类别先验分布和所述样本类内风格 特征对应的类内风格先验分布; 根据所述数据特征中的类别特征,对相应的待聚类数据进行聚类。 一种数据聚类的处理装置,所述装置包括: 第二获取模块,用于获取聚类业务中的待聚类数据; 特征编码模块,用于通过编码器,将所述待聚类数据编码为数据特征;所述编码 6 CN 111598153 A 说 明 书 3/16 页 器,是至少根据相关性和评分值训练得到的;所述相关性,是数据编码器将所述数据样本编 码所得的样本特征,通过判别器对所述数据样本与所述样本特征间进行相关判别的结果; 所述评分值是通过评价器对所述样本特征服从先验分布的评分结果;所述样本特征包括样 本类别特征和样本类内风格特征;所述先验分布包括所述样本类别特征对应的类别先验分 布和所述样本类内风格特征对应的类内风格先验分布; 聚类模块,用于根据所述数据特征中的类别特征,对相应的待聚类数据进行聚类。 一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在 于,所述处理器执行所述计算机程序时实现以下步骤: 获取聚类业务中的待聚类数据; 通过编码器,将所述待聚类数据编码为数据特征;所述编码器,是至少根据相关性 和评分值训练得到的;所述相关性,是数据编码器将所述数据样本编码所得的样本特征,通 过判别器对所述数据样本与所述样本特征间进行相关判别的结果;所述评分值是通过评价 器对所述样本特征服从先验分布的评分结果;所述样本特征包括样本类别特征和样本类内 风格特征;所述先验分布包括所述样本类别特征对应的类别先验分布和所述样本类内风格 特征对应的类内风格先验分布; 根据所述数据特征中的类别特征,对相应的待聚类数据进行聚类。 一种计算机可读存储介质,存储有计算机程序,其特征在于,所述计算机程序被处 理器执行时实现以下步骤: 获取聚类业务中的待聚类数据; 通过编码器,将所述待聚类数据编码为数据特征;所述编码器,是至少根据相关性 和评分值训练得到的;所述相关性,是数据编码器将所述数据样本编码所得的样本特征,通 过判别器对所述数据样本与所述样本特征间进行相关判别的结果;所述评分值是通过评价 器对所述样本特征服从先验分布的评分结果;所述样本特征包括样本类别特征和样本类内 风格特征;所述先验分布包括所述样本类别特征对应的类别先验分布和所述样本类内风格 特征对应的类内风格先验分布; 根据所述数据特征中的类别特征,对相应的待聚类数据进行聚类。 上述数据聚类的处理方法、装置、计算机设备和存储介质,通过确定数据样本与样 本特征之间的相关性,以及对样本类别特征引入类别先验分布,对样类内风格特征引入类 内风格先验分布,以确定样本特征服从于先验分布的评分值,由此利用相关性和评分对编 码器进行训练,可以有效改善编码器对样本特征的学习。由于编码器学习到的特征分布靠 近先验分布,并且对样本类别特征与样本类内风格特征进行有效解耦,由此根据数据特征 中的类别特征,即可得到待聚类数据对应的聚类类别。从而实现了在无需人工标注的情况 下有效提高数据聚类的精度。 附图说明 图1为一个实施例中数据聚类的处理方法的应用环境图; 图2为一个实施例中数据聚类的处理方法的流程示意图; 图3为一个实施例中聚类模型进行训练的整体网络结构示意图; 图4为一个实施例中自编码的网络结构示意图; 7 CN 111598153 A 说 明 书 4/16 页 图5为一个实施例中对抗网络的网络结构示意图; 图6-1为一个实施例中t-SNE图中的聚类簇无重叠的示意图; 图6-2为一个实施例中t-SNE图中的聚类簇出现重叠的示意图; 图7为另一个实施例中数据聚类的处理方法的流程示意图; 图8为一个实施例中数据聚类的处理装置的结构框图; 图9为另一个实施例中数据聚类的处理装置的结构框图; 图10为又一个实施例中数据聚类的处理装置的结构框图; 图11为一个实施例中计算机设备的内部结构图。











