 技术摘要:
技术摘要: 本发明公开了一种基于GPU加速的电网拓扑分析高性能计算方法及装置,根据电网模型分层分区的特点,以及电网计算需求的抽象特性,对电网中各类元器件进行抽象建模,并将电网信息保存到系统内存中,在使CPU和GPU能够共享使用数据的同时,保持了CPU与GPU不同设备间数据格式 全部
背景技术:
目前,电网拓扑分析,是电力能量流动过程中,对用于转换、保护、控制这一过程的
元件状态的分析。进行拓扑分析的目的是将分析结果用于电网分析和计算,它介于底层信
息(如SCADA),和高层应用(如状态估计和安全调度)之间,底层信息是拓扑分析的基础,高
层应用是拓扑分析的目的。电网拓扑分析是电网管理系统的重要组成部分,是实现“数字
化”电网的关键一步。由于拓扑分析是公用的基础模块,其可靠性和快速性直接影响到其上
应用层的性能,因此对其研究具有重要价值。
电网拓扑分析主要是根据电网中电气元件在物理上的连接关系和开关/刀闸的闭
合情况,生成电网在线分析计算中使用的母线-支路计算模型,具体分为两个步骤:厂站拓
扑分析:根据开关/刀闸的闭合情况,由物理节点模型生成计算节点模型。其功能是分析某
一个厂站内的物理节点由闭合开关连接形成多少个计算节点,其结果是将厂站划分为若干
个计算节点。系统拓扑分析:根据支路的连接情况,分析电网的计算节点由闭合的支路连接
成多少个子系统。电网正常运行时一般同属于一个子系统。电网中具有不同参数的元件,在
拓扑结构中是彼此并列的,这天然地适合并行化处理。
传统电网拓扑分析采用串行方法,在大规模电网拓扑分析中表现很差。近年来,随
着CPU多线程技术的进步和普及,一些采用CPU多线程进行加速的电网拓扑分析方法被提出
来。但是,由于CPU多线程受到CPU硬件核心数的限制,往往仅能采用4线程或8线程,对比现
实电网的大体量,其并行度远远不足,当电网规模进一步扩大时,CPU多线程并行的运算表
现迅速降低。
技术实现要素:
目的:为了克服现有技术中存在的串行拓扑分析实时性较差的不足,本发明提供
一种基于GPU加速的电网拓扑分析高性能计算方法,CPU进行拓扑数据预处理,而将大规模
的拓扑搜索步骤置于GPU上完成,设计相关的并行算法,从而实现电网拓扑分析的并行计
算。对实际电网进行的测试结果表明,该方法具有优异的实时性和稳定能,能够满足电网实
时在线拓扑分析的需求。
技术方案:为解决上述技术问题,本发明采用的技术方案为:
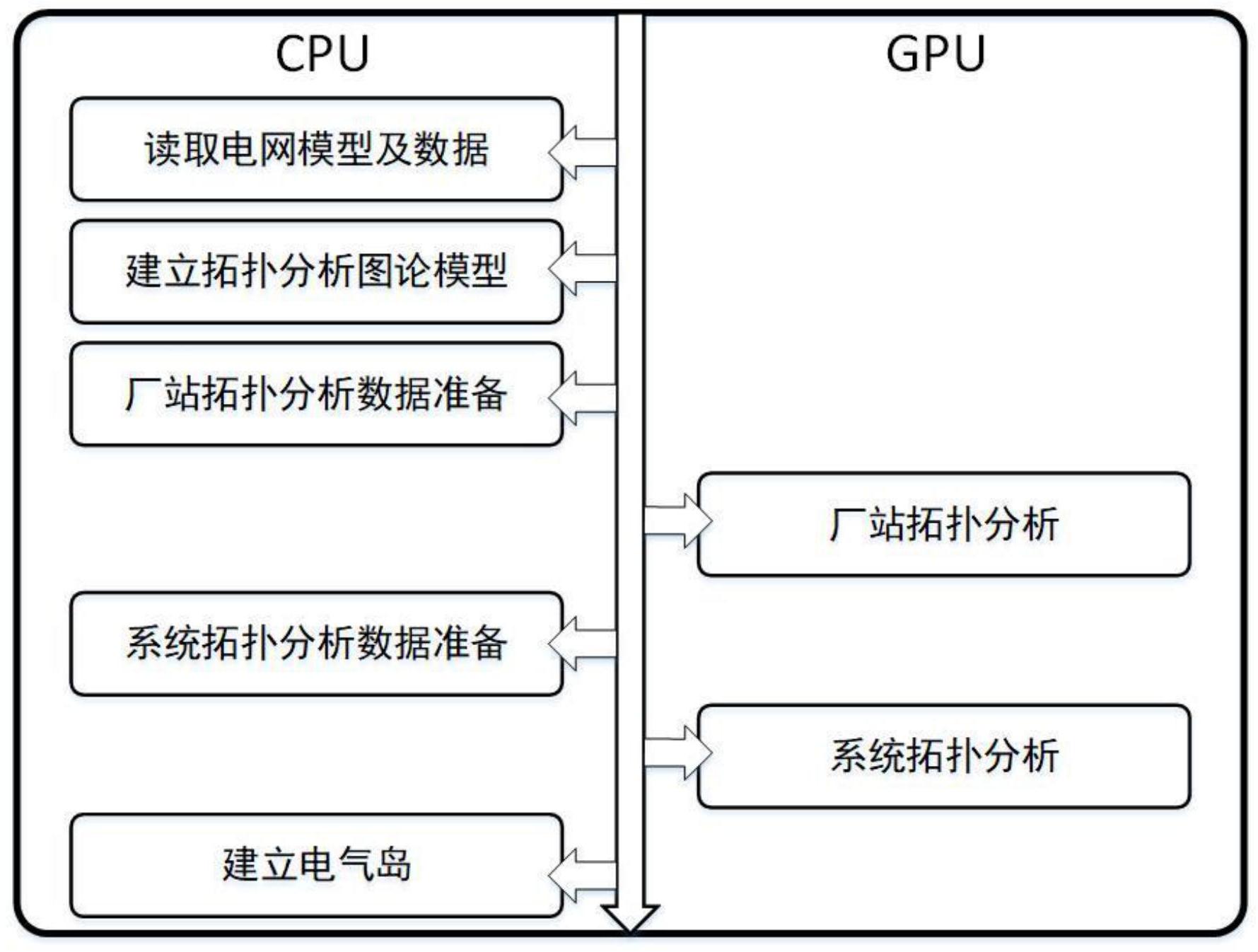
一种基于GPU加速的电网拓扑分析高性能计算方法,包括如下步骤:
CPU对电网调度控制系统电网模型进行图论抽象,得到CPU端的压缩邻接数组h_Adj1,
h_Adj2,h_Adj1代表全网物理节点的第一压缩邻接数组,h_Adj2代表全网物理节点的第二
压缩邻接数组;
GPU调用内核函数Topo_Kernel_1
,将CPU端全网物理节点的第
9
CN 111553040 A 说 明 书 2/11 页
一压缩邻接数组h_Adj1传到GPU端全网物理节点的第一压缩邻接数组d_Adj1,根据GPU端物
理节点的标志位前驱数组d_Frontier[d_Adj1[i]]=1,表示在下一次启动时,d_Adj1[i]号
物理节点需要启动,GPU端物理节点的标志位结果数组d_Visited[i]=m,表示第i个物理节
点属于m号计算节点,将各计算节点包含的物理节点序号,保存在CalculationNodeMap中,
再根据CPU端全网物理节点的第二压缩邻接数组h_Adj2,得到CPU端计算节点的压缩邻接数
组h_Adj_Island;BlockNum表示同时启动的线程块数,ThreadNum表示每一个线程块内,同
时启动的线程数;
GPU调用内核函数Topo_Kernel_2,将CPU端计算节点的压缩邻
接数组h_Adj_Island传到GPU端计算节点的压缩邻接数组d_Adj_Island,根据GPU端计算节
点的标志位前驱数组d_Frontier_Island[d_Adj_Island[i]]=1,表示在下一次启动时,d_
Adj_Island[i]号节点需要启动,GPU端计算节点的标志位结果数组d_Visited_Island[i]=
m,表示第i号计算节点属于第m号电气岛,将各电气岛包含的计算节点序号和物理节点序
号,保存在SystemMap中。
作为优选方案,对电网调度控制系统电网模型进行图论抽象,得到CPU端的物理节
点的压缩邻接数组h_Adj1,h_Adj1Index,h_Adj2,h_Adj2Index,具体步骤如下:
物理节点存储于PhysicalNodeMap中,共有VertexNum个物理节点,每个物理节点均包
含无阻抗邻接数组Adjlist1和有阻抗邻接数组Adjlist2,PhysicalNodeMap为物理节点与
序号关系的映射表;
物理节点的搜索方法为,遍历全体电气元件,检查其两端电气连接点唯一标识,若尚未
包含在PhysicalNodeMap中,则将该标识与该物理节点对应的序号建立映射,存入
PhysicalNodeMap中;
无阻抗支路的搜索方法为,遍历全体隔离开关和断路器,根据其两端电气连接点唯一
标识,根据PhysicalNodeMap中映射,将两端物理节点对应的序号,分别填入对方的无阻抗
邻接数组Adjlist1中;
有阻抗支路的搜索方法为,遍历全体变压器、输电线路和串联补偿器,根据其两端电气
连接点唯一标识,根据PhysicalNodeMap中映射,将两端物理节点对应的序号,分别填入对
方的有阻抗邻接数组Adjlist2中;
全网物理节点的第一压缩邻接数组h_Adj1,它是将每个物理节点的无阻抗邻接数组
Adjlist1,根据其序号递增的顺序首尾相连;h_Adj1的索引数组h_Adj1Index记录每个物理
节点的无阻抗邻接数组Adjlist1在h_Adj1中的起止位置;
全网物理节点的第二压缩邻接数组h_Adj2,它是将每个物理节点的有阻抗邻接数组
Adjlist2,根据其序号递增的顺序首尾相连;h_Adj2的索引数组h_Adj2Index记录每个物理
节点的Adjlist2在h_Adj2中的起止位置。
一种基于GPU加速的电网拓扑分析高性能计算装置,包括如下模块:
电网模型转换模块:CPU对电网调度控制系统电网模型进行图论抽象,得到CPU端的压
缩邻接数组h_Adj1,h_Adj2,h_Adj1代表全网物理节点的第一压缩邻接数组,h_Adj2代表全
网物理节点的第二压缩邻接数组;
第一内核函数调用模块:GPU调用内核函数Topo_Kernel_1,将
CPU端全网物理节点的第一压缩邻接数组h_Adj1传到GPU端全网物理节点的第一压缩邻接
10
CN 111553040 A 说 明 书 3/11 页
数组d_Adj1,根据GPU端物理节点的标志位前驱数组d_Frontier[d_Adj1[i]]=1,GPU端物理
节点的标志位结果数组d_Visited[i]=m,将各计算节点包含的物理节点序号,保存在
CalculationNodeMap中,再根据CPU端全网物理节点的第二压缩邻接数组h_Adj2,得到CPU
端计算节点的压缩邻接数组h_Adj_Island;d_Frontier[d_Adj1[i]]=1表示在下一次启动
时,d_Adj1[i]号物理节点需要启动,d_Visited[i]=m表示第i个物理节点属于m号计算节
点,BlockNum表示同时启动的线程块数,ThreadNum表示每一个线程块内,同时启动的线程
数;
第二内核函数调用模块:GPU调用内核函数Topo_Kernel_2,将
CPU端计算节点的压缩邻接数组h_Adj_Island传到GPU端计算节点的压缩邻接数组d_Adj_
Island,根据GPU端计算节点的标志位前驱数组d_Frontier_Island[d_Adj_Island[i]]=1,
GPU端计算节点的标志位结果数组d_Visited_Island[i]=m,将各电气岛包含的计算节点序
号和物理节点序号,保存在SystemMap中,d_Frontier_Island[d_Adj_Island[i]]=1表示在
下一次启动时,d_Adj_Island[i]号节点需要启动,d_Visited_Island[i]=m,表示第i号计
算节点属于第m号电气岛,SystemMap为电气岛与序号关系的映射表。
作为优选方案,Topo_Kernel_1的计算流程如下:
(2.1)CPU端设置物理节点的标志位d_Frontier前驱数组,d_Visited结果数组的初始
值分别为0,-1,其中,d_Frontier前驱数组的值为0代表本次执行该线程不启动,d_Visited
结果数组的值为-1 代表该物理节点还未被访问;
(2.2)CPU端,当第k个物理节点h_Visited[k]=-1时,表示第k个物理节点的未被访问,
令其h_Frontier[k]=1,表示第k个物理节点本次执行线程启动,并将h_Frontier和h_
Visited传往GPU,替换前驱数组d_Frontier和结果数组d_Visited;
(2.3)GPU运算平台CUDA自动为每个线程分配线程块索引blockID和线程块中的线程索
引threadID;
(2.4)GPU上,将blockID和threadID分别赋值给变量bid和tid,通过bid和tid来索引
GPU上bid号线程块中的tid号线程,GPU并行采用大量线程同时启动的方法,即bid取值范围
为0到BlockNum,tid取值范围为0到ThreadNum,下述过程在每根线程上同时发生;
(2.5) GPU第bid号线程块中的tid号线程用于更新系统中的第bid*ThreadNum tid个
物理节点的标志位d_Frontier前驱数组,d_Visited结果数组,以及遍历该物理节点的压缩
邻接数组;设j=bid*ThreadNum tid,全体线程中,仅有满足前驱数组d_Frontier[j]=1的线
程继续执行,其他线程均关闭,等待下一次启动;
(2.6)GPU端启动的线程中,第j个物理节点的第一压缩邻接数组起始位为d_Adj1Index
[j],终止位为d_Adj1Index[j 1],表示第j个物理节点的第一压缩邻接数组的值依次为d_
Adj1[d_Adj1Index[j]]、d_Adj1[d_Adj1Index[j] 1]、d_Adj1[d_Adj1Index[j] 2]……,d_
Adj1[d_Adj1Index[j 1]],第j个物理节点的前驱数组为d_Frontier[j],结果数组为d_
Visited[j];
(2.7)第bid号线程块的tid号线程中,变量i从d_Adj1Index[j]递增到d_Adj1Index[j
1],当且仅当d_Visited[i]=-1时,代表结果数组尚未被访问过,令d_Frontier[d_Adj1[i]]
=1,表示在下一次启动时,d_Adj1[i]号节点需要启动,d_Visited[i]=m,表示该物理节点属
于第m号计算节点;
11
CN 111553040 A 说 明 书 4/11 页
(2.8)在GPU端,调用设备端函数Is_F_Empty( ),变量k对d_Frontier前驱数组进行遍
历,是否存在d_Frontier[k]=1,如有,再次启动全部线程,回到步骤(2.4),如果不存在d_
Frontier[k]=1,表示第m号计算节点划分完成,令m自加1;
(2.9)将计算后的d_Visited结果数组从GPU端读回CPU端并存入保存全部物理节点归
属于具体计算节点信息的结果数组h_Visited中;
(2.10)在CPU端,变量k从0增加到VertexNum,是否有h_Visited[k]=-1,如存在,说明尚
有物理节点未被划分,回到步骤(2.2)继续进行循环,若不存在,说明全网物理节点均划分
到相应的计算节点,进入步骤(2.11);
(2.11)在CPU端,将每个计算节点包含的物理节点的序号存储到CalculationNodeMap,
得到CalculationNodeCounter个计算节点。
(2.12)在CPU端,变量i按顺序遍历CalculationNodeCounter,对于第i个计算节点
包含的第k号物理节点,其物理节点的第二压缩邻接数组的起始位为h_Adj2Index[k],终止
位为h_Adj2Index[k 1],对于第k号物理节点的第二压缩邻接数组的第j位的值h_Adj2[j],
令计算节点的压缩邻接数组h_Adj_Island[p]=h_Visited[h_Adj2[j]],表示第i个计算节
点与第h_Adj2[j]号物理节点所属的[h_Visited[h_Adj_2[j]]号计算节点相连,p为一个递
增的指针,指向h_Adj_Island的末尾;当第i个计算节点的压缩邻接数组生成完后,令计算
节点的压缩邻接数组的索引数组h_AdjIndex_Island[i 1]=p。
作为优选方案,所述ThreadNum设置为1024,线程块数量BlockNum =(VertexNum-
1)/ ThreadNum 1。
作为优选方案,Topo_Kernel_2的计算流程如下,
(3.1)CPU端设置计算节点的标志位d_Frontier_Island前驱数组,d_Visited_Island
结果数组的初始值分别为0,-1,其中,d_Frontier_Island前驱数组的值为0代表本次执行
该线程不启动,d_Visited_Island结果数组的值为-1 代表该计算节点还未被访问;
(3.2)CPU端,当第k个计算节点h_Visited_Island[k]=-1时,令其h_Frontier_Island
[k]=1,表示第k个计算节点本次执行线程启动,并将h_Frontier_Island和h_Visited_
Island传往GPU,替换前驱数组d_Frontier_Island和结果数组d_Visited_Island;
(3.3)GPU运算平台CUDA自动为每个线程分配线程块索引blockID和线程块中的线程索
引threadID;
(3.4)GPU上,将blockID和threadID分别赋值给变量bid和tid,通过bid和tid来索引
GPU上bid号线程块中的tid号线程,GPU并行采用大量线程同时启动的方法,即bid取值范围
为0到BlockNum,tid取值范围为0到ThreadNum,下述过程在每根线程上同时发生;
(3.5) GPU第bid号线程块中的tid号线程负责更新系统中的第bid*ThreadNum tid个
计算节点的标志位d_Frontier_Island前驱数组,d_Visited_Island结果数组,以及遍历该
计算节点的压缩邻接数组;设j=bid*ThreadNum tid,全体线程中,仅有满足前驱数组d_
Frontier_Island[j]=1的线程继续执行,其他线程均关闭,等待下一次启动;
(3.6)GPU端启动的线程中,第j个计算节点的压缩邻接数组起始位为d_AdjIndex_
Island [j],终止位为d_AdjIndex_Island [j 1],表示第j个计算节点的压缩邻接数组的
值依次为d_Adj_Island [d_AdjIndex_Island [j]],d_Adj_Island [d_AdjIndex_Island
[j] 1]……,d_Adj_Island [d_AdjIndex_Island [j 1]],第j个计算节点的前驱数组为d_
12
CN 111553040 A 说 明 书 5/11 页
Frontier_Island [j],结果数组为d_Visited_Island [j];
(3 .7)第bid号线程块的tid号线程中,变量i从d_AdjIndex_Island[j]递增到d_
AdjIndex_Island[j 1],当且仅当d_Visited_Island[i]=-1时,代表结果数组尚未被访问
过,令d_Frontier_Island[d_Adj_Island[i]]=1,表示在下一次启动时,d_Adj_Island[i]
号节点需要启动,d_Visited_Island[i]=m,表示该计算节点属于第m号电气岛;
(3.8)在GPU端,调用设备端函数Is_F_Empty( ),变量k对d_Frontier_Island前驱数组
进行遍历,是否存在d_Frontier_Island[k]=1,如有,再次启动全部线程,回到步骤(3.4),
如果不存在d_Frontier_Island[k]=1,说明第m号电气岛划分完成,令m自加1;
(3.9)将计算后的d_Visited_Island结果数组从GPU端读回CPU端并存入保存全部计算
节点归属于具体电气岛信息的结果数组h_Visited_Island中;
(3.10)在CPU端,变量k从0增加到CalculationNodeCounter,检查是否有h_Visited_
Island[k]=-1,如存在,说明尚有计算节点未被划分,回到步骤(3.2)继续进行循环,若不存
在,说明全网计算节点均划分完成,进入步骤(3.11);
(3.11)在CPU端,将每个电气岛包含的计算节点的序号存储到SystemMap中。
作 为 优 选 方 案 ,所 述 T h r e a d N u m 设 置 为 1 2 8 ,B l o c k N u m =
(CalculationNodeCounter-1)/ ThreadNum 1。
有益效果:本发明提供的一种基于GPU加速的电网拓扑分析高性能计算方法,根据
电网模型分层分区的特点,以及电网计算需求的抽象特性,对电网中各类元器件进行抽象
建模,并将电网信息保存到系统内存中,在使CPU和GPU能够共享使用数据的同时,保持了
CPU与GPU不同设备间数据格式的一致性,保证了并行网络拓扑分析的执行效率和稳定性。
将GPU通用并行计算技术应用到电网网络拓扑分析中,提高了电网网络拓扑分析
的执行效率,为大规模并联电网的在线分析计算提供了实时性的支持,以便在后续计算应
用时能更及时地得到电网结构的实时状态。
附图说明
图1是本发明实施例中采用的抽象模型的电网分层结构;
图2是本发明实施例中基于GPU加速的电网拓扑分析计算方法的流程图;
图3是本发明实施例中在GPU端实现对于一个10节点系统进行并行拓扑分析的原理展
示。












