
技术摘要:
本发明提供了一种检测血液BCR重链和轻链的免疫组库信息分析方法,具体包括参考序列构建、测序数据预处理、Paired Reads合并、Merge后的数据与参考序列进行比对、比对结果过滤及统计分析,同时,还提供了一种检测血液BCR的免疫组库方法,该方法中采用了上述信息分析方法 全部
背景技术:
人体内的免疫细胞主要包括T细胞和B细胞。T细胞抗原受体是特异性识别和结合 抗原肽-MHC分子的分子结构,大部分T细胞受体由α和β两种肽链组成,少数T细胞受体由γ 和δ两种肽链组成,其中α和β两条肽链的可变区(V区)在免疫细胞成熟过程中发生基因重 排,从而形成了多种重组序列片段,导致T细胞呈现出多样性。B细胞抗原受体是B细胞表面 识别抗原的一种免疫球蛋白,具有抗原结合特异性,B细胞受体由两条重链和两条轻链组 成,其中可变区(V区)由VH和VL两个结构域构成,它们排列顺序和氨基酸组成都呈现出高度 多样性。 在任何特定时间内,某个个体的循环系统中所有功能多样性B细胞或者T细胞的多 态性总和,被称为免疫组库(immune repertoire,IR)。它既是个体免疫状态的“快照”,又是 个体免疫接触史的“全纪录”。T细胞、B细胞分别负责细胞免疫和体液免疫。人体的免疫能力 很大程度上依赖于T细胞和B细胞的多样性。T细胞受体(T cell receptor,TCR)和B细胞受 体(B cell receptor,BCR)由多条肽链组成,具有抗原结合特异性,每条肽链的互补决定区 (complementarity-determining region,CDR,又称超变区)氨基酸组成和排列顺序呈现高 度多样性,构成容量巨大的TCR和BCR库。TCR或BCR的基因多样性,一方面通过组合多样性、 连接多样性等胚系基因重排而获得(即由多个不连续功能性的V、D、J、C基因片断重排),另 一方面通过核苷酸的随机插入、剪接、二次重排等获得,形成多样性的抗原互补决定区 (CDR1、CDR2、CDR3)。其中CDR3最能直接反应TCR或BCR的多样性。T细胞和B细胞对众多抗原 的识别依赖于CDR3区的多样性,故对TCR CDR3区、BCR CDR3区序列的分析,可作为判别细胞 抗原识别特性的重要指标。研究免疫组库有助于了解个体的免疫状态,分析疾病的发生、发 展和预后。 至今免疫组库研究技术主要经历了3个阶段。从最初的流式细胞术分析T细胞各亚 家族的分布与缺失,到免疫扫描谱系分析技术研究各亚家族CDR3基因长度的多态性,再到 如今高通量测序技术能够完整的检测所有T细胞、B细胞的CDR3序列,并能实现T细胞α、β双 链测序,B细胞轻重链(HL链)同时测序。前两种技术都只能从一定程度上反映T、B细胞的克 隆性分布,而高通量测序技术能够同时分析所有T、B细胞CDR3序列,真实地反映所有TCR、 BCR的遗传信息,较全面地揭示TCR、BCR免疫组库的复杂性和多样性,是免疫组库研究最具 划时代意义的重要技术。高通量测序技术的发展将免疫组库研究推向新的阶段。免疫组库 测序技术(immune repertoire sequencing,IR-SEQ)主要通过5’RACE或者多重PCR技术将 免疫球蛋白重链(IGH)或者T细胞受体β区多态性最高的互补决定区(CDR3)捕获下来,然后 进行高通量深度测序,在此基础上研究B细胞或者T细胞的多态性,是当今一大研究亮点。 4 CN 111599411 A 说 明 书 2/19 页 目前,免疫组库测序技术尽管还不能作为疾病诊断或治疗的依据,然而显示出在 某些疾病的微小残留检测、疗效评估、预后监测、疫苗的研发和评估、生物标志物的发现中 具有参考价值和积极意义。然而,免疫组库测序技术本身仍然具有一些缺陷,例如:(1)常规 的T细胞和B细胞的免疫组库测序技术有5’RACE和多重PCR。5’RACE技术只能基于细胞RNA, 先通过TCR/BCR的C区(恒定区)的通用引物序列向V(D)J区域(可变区)扩增,然后引入的接 头序列进行第二次无偏好的PCR扩增。该方法操作复杂,对TCR/BCR的C区通用引物的特异性 要求高,检测结果常包含非特异性序列造成有效数据量降低,影响有效数据的分析。多重 PCR技术可以基于细胞DNA或RNA,在TCR/BCR的V区设置上游引物,J区或C区设置下游引物, 通过PCR扩增获得目的区域的基因片段信息。该方法可以保证扩增产物区域的特异性,但如 果扩增引物数量过多会造成扩增产物不均一的情况。(2)一般设计的引物组合是一种V区亚 型对应一组引物对,如果包含多种V区亚型会使引物组合的复杂程度增加,在多重PCR扩增 时容易造成不同引物对扩增的效率存在差异,进而影响后续对CDR3区域序列变化分析的准 确性。
技术实现要素:
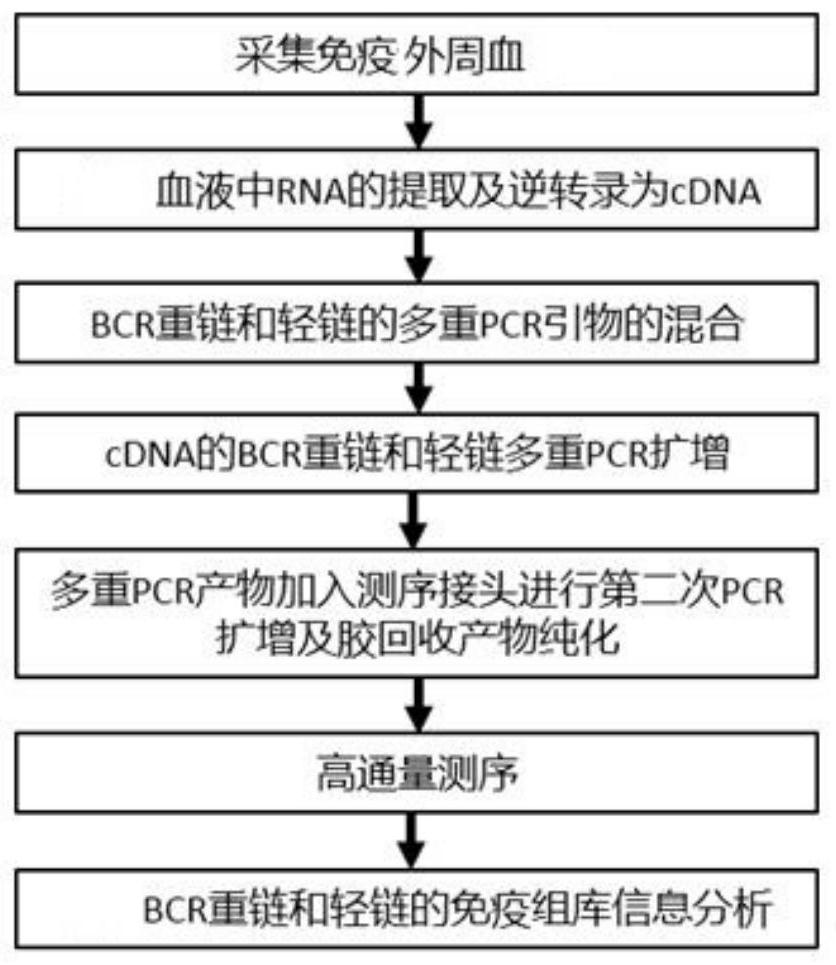
本发明旨在建立一种血液BCR免疫组库检测的方法,通过设计血液BCR重链和轻链 的引物组合实现对CDR3区域序列的测序分析,同时可以得到V(D)J亚型的组合信息,推进对 抗体生成与CDR3序列变化关系的技术发展,本发明具体提供了一种检测血液BCR重链和轻 链的免疫组库信息分析方法,包括以下步骤: (1)参考序列构建 从国际免疫遗传信息系统IMGT数据库中下载V、D、J基因的所有序列构成模板序 列,再将特异性的引物与V、D、J所有序列进行比对,引物与模板序列小于等于3个错配的位 置都保留下来,从引物的起始位置开始至能形成PCR产物的部分作为参考序列,若引物与模 板序列存在错配,则生成2条参考序列;对于构建成的参考序列库,进行合并,去除重复的参 考序列,保留一条;参考序列构建完成后,序列id上已经明确了CDR3起始、终止位置信息; (2)测序数据预处理 获得测序数据后,对其进行预处理,数据预处理包括去除接头adapter污染序列、 低质量序列、N比率过高序列; (3)双端序列Paired Reads合并: 利用拼接原理,把测序得到的双端末尾序列Paired-end reads进行拼接合并,即 重叠区Contigs; (4)双端末尾序列Paired-end reads合并后的数据与参考序列进行比对: 拼接好的序列重叠区contigs与构建好的参考序列进行序列对位的比对,序列与 V、D、J分开比对;重新比对,找出最佳比对及精确比对位置,方法为:根据序列对位blast的 比对结果,V向3’端延伸,D向两端延伸,J向5’端延伸,进行重新比对、计算得分和identity; 对V、D、J分别选出得分最高的比对结果作为最佳比对;为了精确V、D、J的比对位置,在特定 区域设定有限的错配mismatch数目;对V、J,属于CDR3的部分设定一定的错配mismatch,对 D,在整个比对区域设定一定的错配mismatch;具体设定的错配mismatch数目因不同的链而 有区别; 5 CN 111599411 A 说 明 书 3/19 页 (5)比对结果过滤: 过滤过程包括但不限于以下任意一种:低频率序列、缺少V基因或者J基因的序列、 V基因与J基因比对正负链不一致的序列、比对到假基因上的序列、翻译成氨基酸序列,如果 含有终止子、开发阅读框内的碱基长度不为3的倍数; (6)统计分析:根据CDR3的位置,把DNA序列翻译成氨基酸序列,并统计多肽的频率 信息;经过过滤,得到可靠的比对结果,统计V、D、J基因的使用频率、插入缺失、长度、碱基组 成,免疫多样性情况信息,绘制V、J基因表达的2D、3D图,呈现免疫组库多样性。 作为本发明的











