
技术摘要:
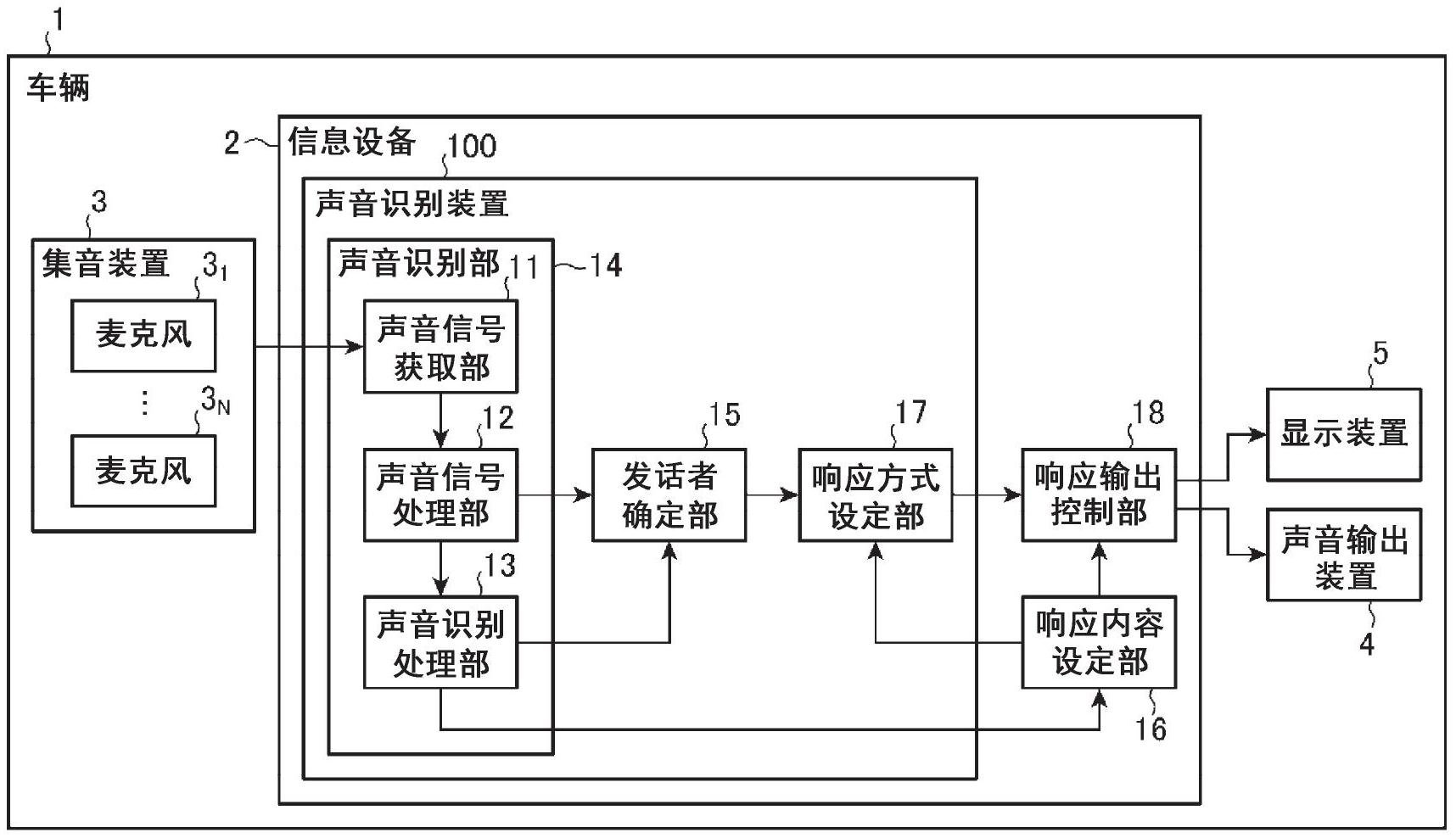
本发明的声音识别装置(100)包括:声音识别部(14),该声音识别部(14)针对就座于车辆(1)的声音识别对象座位的多位乘客中的发话者的操作输入用的发话声音执行声音识别;发话者确定部(15),该发话者确定部(15)执行对发话者个人进行确定的个人确定处理或对发话者就座的座位 全部
背景技术:
以往,开发了针对车辆内的信息设备的操作输入用的声音识别装置。下面,将成为 车辆的声音识别对象的座位称为“声音识别对象座位”。另外,将就座于声音识别对象座位 的乘客中的发出操作输入用的声音的乘客称为“发话者”。另外,将由发话者发出的操作输 入用的声音称为“发话声音”。 专利文献1中,公开了对声音识别对象座位即驾驶座及副驾驶座中的发话者就座 的座位进行确定的技术。由此,实现了在多位乘客就座于声音识别对象座位的情况下的适 当的操作输入。 现有技术文献 专利文献 专利文献1: 日本专利特开平11-65587号公报
技术实现要素:
发明所要解决的技术问题 近年来,开发了与所谓的“对话型”UI(User Interface:用户界面)对应的声音识 别装置。即,开发了一种UI,该UI除了通过执行针对发话声音的声音识别来接受操作输入以 外,还使扬声器输出针对该发话声音的响应用的声音(下面称为“响应用声音”),或使显示 器显示针对该发话声音的响应用的图像(下面称为“响应用图像”)。下面,有时将对话型UI 中的响应用声音及响应用图像等简单统称为“响应”。 与对话型UI对应的声音识别装置中,在多位乘客就座于声音识别对象座位的情况 下,输出针对该多位乘客中的发话者的响应。此时,存在该多位乘客各自难以识别响应是否 是针对自己本身的响应的问题。尤其是,存在当大致同时输出了针对多位发话者的响应的 情况下识别更加困难的问题。 本发明是为了解决上述那样的问题而完成的,其目的在于对就座于声音识别对象 座位的多位乘客分别通知对话型UI中的响应是否是针对自己本身的响应。 解决技术问题所采用的技术方案 本发明的声音识别装置的特征在于,包括:声音识别部,该声音识别部针对就座于 车辆的声音识别对象座位的多位乘客中的发话者的操作输入用的发话声音执行声音识别; 发话者确定部,该发话者确定部执行对发话者个人进行确定的个人确定处理或对发话者就 座的座位进行确定的座位确定处理中的至少一个;以及响应方式设定部,该响应方式设定 部执行根据发话者确定部的确定结果来设定针对发话者的响应方式的响应方式设定处理, 响应方式设定处理为将响应方式设定成多位乘客各自可识别响应是否是针对自己本身的 4 CN 111556826 A 说 明 书 2/15 页 响应的方式的处理。 发明效果 根据本发明,由于采用如上所述的构成,因此,能对就座于声音识别对象座位的多 位乘客分别通知对话型UI中的响应是否是针对自己本身的响应。 附图说明 图1是示出本发明实施方式1所涉及的声音识别装置设置于车辆内的信息设备的 状态的框图。 图2是示出显示装置显示了响应用图像的状态的说明图。 图3是示出显示装置显示了其他响应用图像的状态的说明图。 图4A是示出设置了本发明实施方式1所涉及的声音识别装置的信息设备的硬件结构的 框图。图4B是示出设置了本发明实施方式1所涉及的声音识别装置的信息设备的其他硬件 结构的框图。 图5是示出设置了本发明实施方式1所涉及的声音识别装置的信息设备的动作的流程 图。 图6是示出本发明实施方式1所涉及的声音识别装置中的声音识别部的详细动作的流 程图。 图7是示出本发明实施方式1所涉及的声音识别系统的主要部分的框图。 图8是示出本发明实施方式2所涉及的声音识别装置设置于车辆内的信息设备的状态 的框图。 图9是示出本发明实施方式2所涉及的声音识别装置中的乘客确定部的动作的流程图。 图10是示出本发明实施方式2所涉及的声音识别装置中的乘客确定部的详细动作的流 程图。 图11是示出设置了本发明实施方式2所涉及的声音识别装置的信息设备中除乘客确定 部以外的部分的动作的流程图。 图12是示出本发明实施方式2所涉及的声音识别装置中的声音识别部的详细动作的流 程图。 图13是示出本发明实施方式2所涉及的其它声音识别装置设置于车辆内的信息设备的 状态的框图。 图14是示出本发明实施方式2所涉及的其它声音识别装置设置于车辆内的信息设备的 状态的框图。 图15是示出本发明实施方式2所涉及的声音识别系统的主要部分的框图。











