
技术摘要:
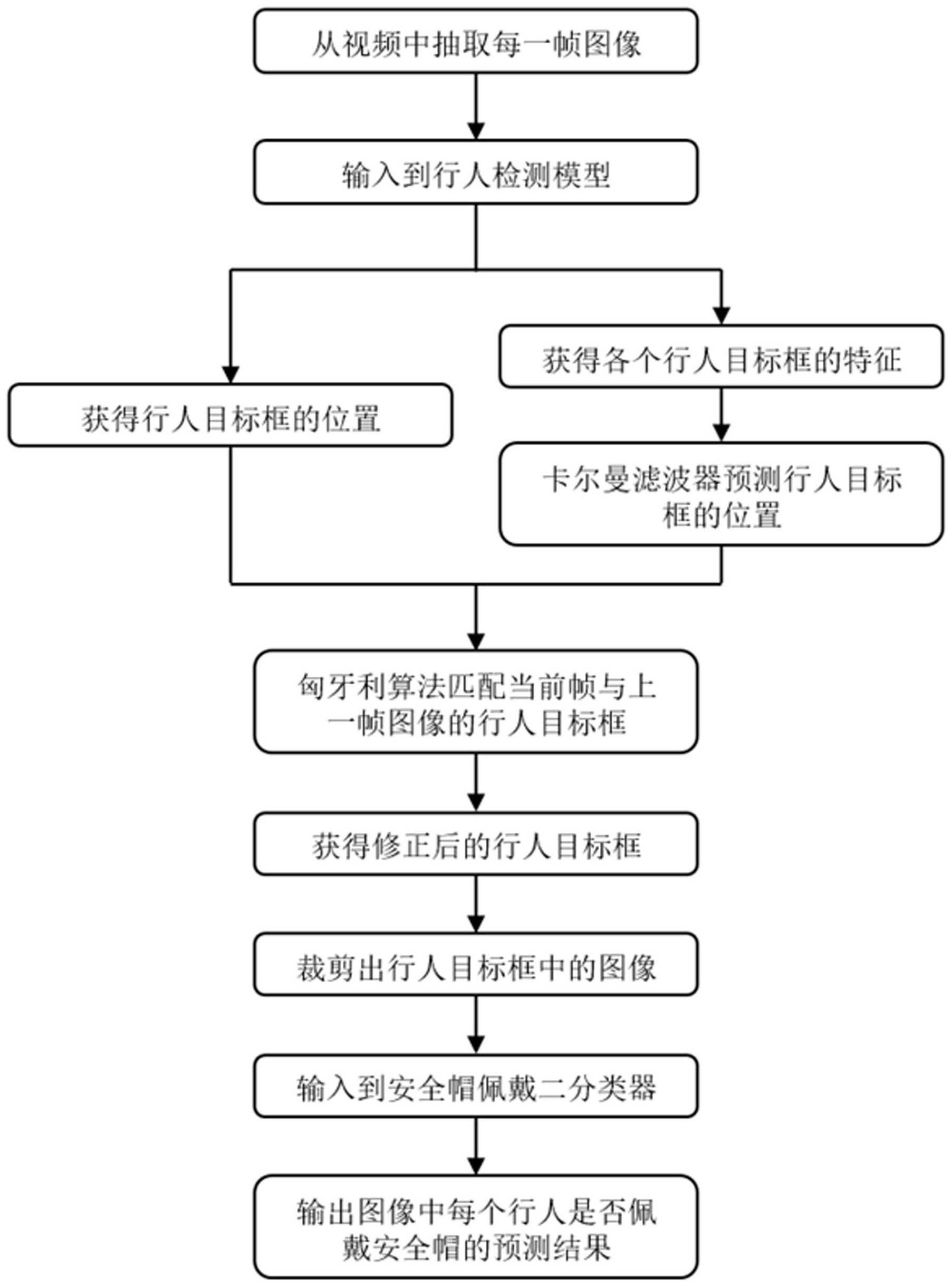
本发明公开了一种基于级联预测的安全帽佩戴识别方法,该方法将安全帽佩戴识别分为行人检测、目标跟踪和安全帽佩戴分类三个步骤。在行人检测时,通过基于深度卷积神经网络的检测算法来获取视频每一帧图像中行人目标框的位置;基于行人检测的结果,采用卡尔曼滤波和匈牙 全部
背景技术:
在高温、供电线路、厂区和工地等作业场所中,佩戴安全帽是一项基本的安全防范 要求。但采用人工监管的方式耗时费力且难度较大,这导致由于施工人员不佩戴安全帽而 引发的安全事故时有发生。针对这个问题,采用智能化的手段来识别施工人员是否佩戴安 全帽具有极大的必要性。传统的安全帽检测方法一般面向的是道路上拍摄的摩托车图像, 旨在确定骑手是否在骑行过程中戴上安全帽。尽管同样是判断安全帽是否佩戴,但道路场 景与实际的施工环境差别极大,这导致实际效果不佳。 近些年来,基于深度卷积神经网络的目标检测方法同样被应用于解决安全帽佩戴 识别的问题。这类方法一般将安全帽佩戴与否作为两种独立的目标,继而采用流行的检测 方法来直接检测图像中佩戴和未佩戴安全帽的两类人员,并以此作为每个检测出的人是否 佩戴安全帽的识别结果。但在实际施工环境下,存在着场景复杂多变、目标移动、互相遮挡、 尺度及光照变化等极具挑战性的问题,这使得现有的检测方法在识别施工人员是否佩戴安 全帽时难以取得较高的准确率。
技术实现要素:
本发明的目的在于针对现有技术的不足,提供一种基于级联预测的安全帽佩戴识 别方法,具体技术方案如下: 一种基于级联预测的安全帽佩戴识别方法,该方法具体包括如下步骤: S1:从监控摄像头拍摄的视频中抽取每一帧图像,按照时间顺序逐帧输入到基于深度 卷积神经网络的行人检测模型中,输出每张图像中检测到的所有行人目标框的位置以及对 应于每个行人目标框的特征; S2:基于当前帧之前的若干帧图像检测到的行人目标框以及各个行人目标框的特征, 采用多目标跟踪算法对视频中的行人进行跟踪,通过卡尔曼滤波器预测出当前帧的行人目 标框位置,接着通过匈牙利算法对当前帧与前一帧图像的行人目标框进行匹配,使用确信 度较高的匹配结果来修正预测的行人目标框,得到所有帧图像优化后的行人目标框; S3:对S2输出的所有帧图像的优化后的行人目标框进行裁剪,裁剪出该行人目标框中 的行人图像,并将其输入基于深度卷积神经网络的二分类器中,最终输出图像中每一个行 人是否佩戴安全帽的预测结果。 进一步地,所述的S1中,选择YOLOv3深度卷积神经网络作为行人检测模型,并在使 用该模型前,先将其在CrowdHuman行人检测数据集上进行预训练,接着在手工标注的复杂 作业场景数据上进行再训练以得到最终的行人检测模型。 进一步地,所述的S2通过如下的子步骤来实现: 4 CN 111598066 A 说 明 书 2/5 页 S2.1:输入视频的第一帧图像,采用检测到的行人目标框来初始化并创建新的行人目 标跟踪器,标注图像中的行人目标框的编号id; S2.2:基于当前帧之前的若干帧图像检测到的行人目标框以及各个行人目标框的特 征,通过卡尔曼滤波器预测出当前帧的行人目标框位置,然后计算行人检测模型输出的当 前帧的行人目标框与卡尔曼滤波器预测的当前帧的行人目标框的交并比IOU: 其中, Box1与Box2分别是两个行人目标框,Box1∩Box2表示两个行人目标框的交集中 所含的像素数目,Box1∪Box2表示两个行人目标框的并集中所含的像素数目; S2.3:通过匈牙利算法对当前帧和其上一帧图像的所有行人目标框进行关联匹配,得 到当前帧图像中的每个行人目标框的交并比的最大的唯一匹配,然后去掉匹配值小于设定 阈值的匹配对;在关联过程中,存在以下三种情况: (a)如果在上一帧图像中的行人目标中找到了本次检测到的目标,说明正常跟踪到了, 无需额外操作; (b)如果在上一帧图像中的行人目标中没有找到本次检测到的目标,说明这个目标是 当前帧中新出现的,则把它记录下来用于之后的跟踪关联; (c)如果在上一帧中存在某个目标,但在当前帧中并没有与之关联的目标,那么说明该 目标从视野中消失了,则将其移除; S2.4:用S2.3得到的当前帧的目标检测框更新S2.1的行人目标跟踪器,并基于S2.2得 到的交并比,计算卡尔曼增益、状态更新和协方差更新,并将状态更新值输出,作为当前帧 的行人目标框; S2.5:重复执行S2.2~S2.4,直到处理完所有帧图像,得到所有帧图像的优化后的行人 目标框。 进一步地,所述的S3分为训练阶段和预测阶段,所述的训练阶段通过如下的子步 骤来实现: S3.1:选择ResNet50深度卷积神经网络作为安全帽佩戴识别的二分类器,首先导入在 ImageNet上预训练的ResNet50网络模型,然后选择在手工标注的复杂作业场景中的行人图 像,裁剪出对应人体上半身的正方形区域图像(x,y,w,w),其中,x,y分别是该目标框的左上 角在X,Y轴上的坐标,w是该正方形区域的边长,将该裁剪出的图像缩放到固定尺寸,再进行 归一化操作后,输入ResNet50; S3.2:每一张输入图像经过网络前向计算以及最后的全连接层之后,将输出一个二维 的向量s,s={s[1],s[2]},其中,s[1]、s[2] 分别代表佩戴和未佩戴安全帽的概率值; S3.3:计算该预测结果s与真值class之间的交叉熵损失: 其中,真值class表示该图像属于佩戴或未佩戴安全帽的类别标签,exp为以自然常数e 为底的指数函数,log为以e为底的对数函数; S3.4:基于S3计算得到的交叉熵损失,对网络进行反向传播操作,通过梯度下降算法不 5 CN 111598066 A 说 明 书 3/5 页 断更新网络参数,从而最终让网络的预测值逼近真实值,达到设定的迭代次数后结束,得到 优化后的ResNet50; 所述的预测阶段具体为:将S2输出的所有帧图像的优化后的行人目标框,裁剪出对应 人体上半身的正方形区域图像(x,y,w,w),将该裁剪出的图像也缩放到固定尺寸,并进行归 一化操作,然后输入S3.4优化后的ResNet50中,输出是否佩戴安全帽的预测结果。 本发明的有益效果如下: (1)本发明的方法将安全帽佩戴识别分解为三个级联的步骤,使各步骤可以针对性地 达成各自的目标,实现方法简单,且各步骤中模块的选择更加灵活; (2)本发明的方法将行人检测与安全帽佩戴分类独立出来,二者互不干扰,相比于直接 检测佩戴和不佩戴安全帽的两类行人目标的方式,能够显著提高安全帽佩戴识别的准确 性; (3)本发明所采用的级联预测方法,能够更好地适应复杂多变的作业场所。 附图说明 图1是基于级联预测的安全帽佩戴识别方法流程图。 图2是对标注的行人目标框进行裁剪的示意图。 图3是工厂复杂环境下的安全帽佩戴识别结果示例。











