
技术摘要:
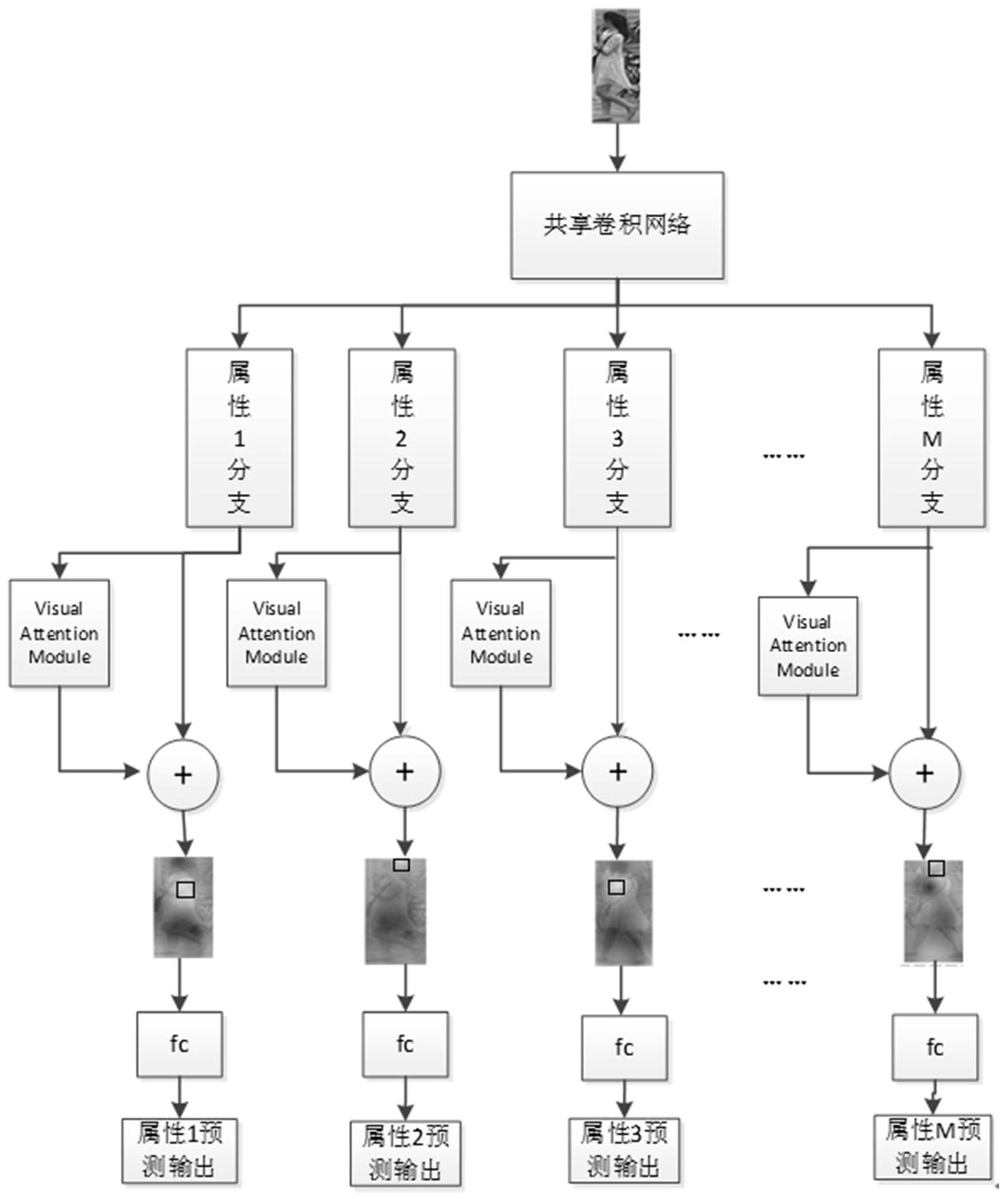
本发明公开了一种基于注意力机制与多任务学习的人体属性识别方法,包括获取行人图像进行处理得到人体框;构建共享卷积网络,对人体框进行共享特征提取;针对人体各属性构建独立的分支卷积网络,以共享特征作为各分支卷积网络的输入,得到各分支卷积网络的输出作为对应 全部
背景技术:
随着人工智能的发展和高清视频监控设备的大范围部署,行人属性识别在视频监 控、智能零售业、行人重识别等领域有着良好的应用前景,受到了越来越多的研究者的关 注,并且已成为视频监控系统领域的新型研究主题。视频监控分布在城市的各个角落,如果 从海量的监控视频信息中提取有效信息,必然会耗费大量的人力物力,效率低下。行人属性 识别是对检测到的行人结构化属性进行提取,一般包括性别、年龄段、上衣类型、上衣颜色 等,这种有效的结构化信息,会给监控视频的检索工作带来极大的便利。 最早的行人属性识别通过人工提取特征,并针对每个不同的属性分别训练分类 器。随着CNN的发展,人们开始把所有属性置于同一个网络进行多任务训练,并发现多任务 训练能够带来更好的效果。目前行人属性识别的基本方法是将整个图片扔进同一个CNN网 络,并输出多个代表属性的标签进行分类。行人属性识别属于多标签分类问题,但因为其各 个属性粗细粒度不同、收敛速度不同,以及容易受到遮挡、光照等因素的影响,当前监控环 境下对行人属性的识别效果一直不甚理想,目前最前沿的算法也只能在mAP(平均准确率) 上达到80%左右。 目前,行人属性识别主要存在以下几个问题: 1)针对细粒度属性,如眼镜、首饰,经过多层的卷积层和池化层处理,该特征减弱 或消失,传统的直接提取整张图像的特征无法很好的识别这些属性;另外,行人属性各不相 同,有的属性需要浅层特征,而有的属性需要高层特征,有的属性需要局部特征,有的属性 需要全局特征才能识别,如何提取一个能够包含所有以上针对不同属性的特征就成了至关 重要的问题。 2)每个属性的收敛速度不同,会导致不同属性在训练过程中影响到其他属性的识 别效果。 3)同一个属性在不同的样本中的相对位置可能不同,如人们背包的位置可能在后 背,也可能在腰间附近。 4)模型训练样本均为人工标注,行人均在框中心位置,而实际应用中,属性识别的 输入为检测输出,行人有可能不在行人框的中心或者人体框不全,从而影响到属性识别的 效果。 因此解决上述问题,提取准确的人体属性信息,对视频监控领域的检索工作具有 重要意义。
技术实现要素:
本申请的目的在于提供一种基于注意力机制与多任务学习的人体属性识别方法, 3 CN 111597870 A 说 明 书 2/5 页 可学习各属性之间的内在联系,并且得到各属性的关键信息区域,提供属性识别的准确率。 为实现上述目的,本申请所采取的技术方案为: 一种基于注意力机制与多任务学习的人体属性识别方法,所述基于注意力机制与 多任务学习的人体属性识别方法,包括: 获取行人图像,采用行人检测算法对行人图像进行处理,得到人体框; 构建共享卷积网络,对所述人体框进行共享特征提取; 针对人体各属性构建独立的分支卷积网络,以所述共享特征作为各分支卷积网络 的输入,得到各分支卷积网络的输出作为对应属性的个性特征; 将得到的各属性的个性特征分别输入至各属性分支对应的注意力机制网络,生成 各属性的注意力图,将注意力图叠加至对应的个性特征上,得到定位有对应属性的所属区 域的特征图; 将定位有对应属性的所属区域的特征图分别输入至各属性分支对应的全连接层, 输出人体各属性的预测识别结果。 作为优选,所述共享卷积网络为BN_inception网络。 作为优选,所述人体属性包括是否有背包、背包颜色、上衣类型、下衣类型和鞋子 颜色。 作为优选,所述针对人体各属性构建独立的分支卷积网络,包括: 所述上衣类型和下衣类型具有粗粒度,均采用三层卷积网络; 所述是否有背包和背包颜色具有中粒度,均采用特征金字塔网络; 所述鞋子颜色具有细粒度,采用加入了Bottom-up path augmentation结构的 PANet网络。 作为优选,所述注意力机制网络从输入侧至输出侧包括依次连接的global average pooling层、1x1的conv层、激活函数ReLU、1x1的conv层、Sigmoid层和Mul层。 本申请提供的基于注意力机制与多任务学习的人体属性识别方法,通过结合基于 注意力机制的属性粗定位和多任务学习,一方面可以得益于多任务训练,各个属性之间共 享底层特征,使各个属性训练任务之间相互获益;另一方面,通过注意力机制定位属性所属 区域,进一步提高属性识别准确率。 附图说明 图1为本申请基于注意力机制与多任务学习的人体属性识别方法的流程图; 图2为本申请注意力机制网络的结构示意图。











