
技术摘要:
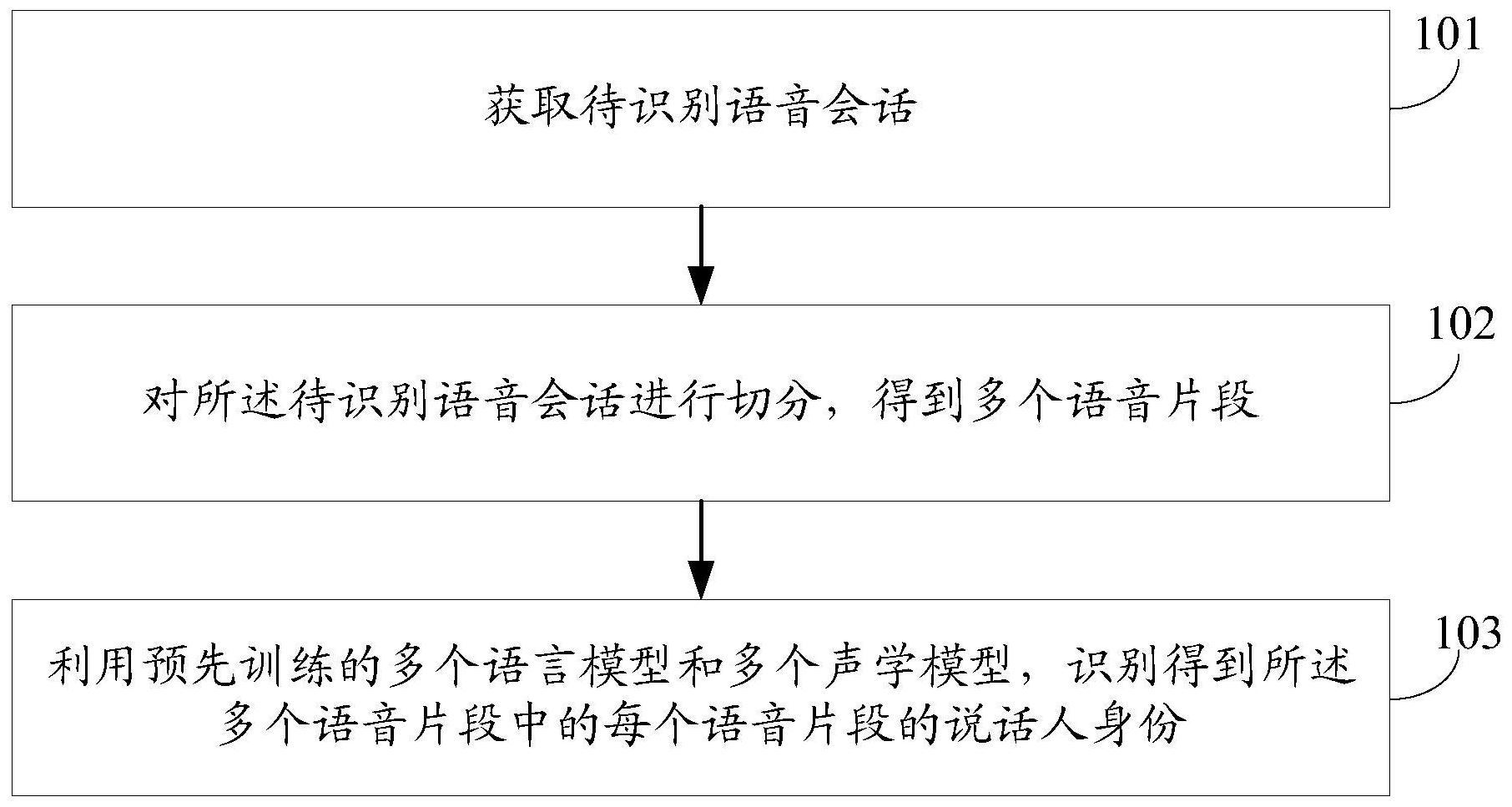
本发明提供一种语音会话的角色识别方法、装置及终端,该角色识别方法包括:获取待识别语音会话;对所述待识别语音会话进行切分,得到多个语音片段;利用预先训练的多个语言模型和多个声学模型,识别得到所述多个语音片段中的每个语音片段的说话人身份;其中,所述多个 全部
背景技术:
目前,在对记录的语音会话进行角色识别时,主要涉及两个模块:切分模块和聚类 模块。其中,切分模块主要负责检测语音会话中说话人身份的改变点,并利用这些改变点将 语音会话分割成多个语音片段;聚类模块通常采用k-means等聚类方法,将属于同一说话人 身份的语音片段聚类在一起,并根据聚类结果,得到该语音会话中说话人个数以及各说话 人的语音。 然而,由于聚类模块采用的聚类方法通常为无监督的,仅基于语音片段的特征进 行聚类,而不同说话人的语音片段之间的特征差异可能非常小,几乎没有,因此得到的聚类 结果的效果往往较差,造成无法对相应语音片段的说话人身份进行有效识别。
技术实现要素:
本发明实施例提供一种语音会话的角色识别方法、装置及终端,以解决现有的语 音会话的角色识别方法中,无法对语音片段的说话人身份进行有效识别的问题。 第一方面,本发明实施例提供了一种语音会话的角色识别方法,包括: 获取待识别语音会话; 对所述待识别语音会话进行切分,得到多个语音片段; 利用预先训练的多个语言模型和多个声学模型,识别得到所述多个语音片段中的 每个语音片段的说话人身份; 其中,所述多个语言模型是区分角色的,每个语言模型对应于一个角色;所述多个 声学模型是区分角色的,每个声学模型对应于一个角色。 第二方面,本发明实施例提供了一种语音会话的角色识别装置,包括: 第一获取模块,用于获取待识别语音会话; 第一切分模块,用于对所述待识别语音会话进行切分,得到多个语音片段; 识别模块,用于利用预先训练的多个语言模型和多个声学模型,识别得到所述多 个语音片段中的每个语音片段的说话人身份; 其中,所述多个语言模型是区分角色的,每个语言模型对应于一个角色;所述多个 声学模型是区分角色的,每个声学模型对应于一个角色。 第三方面,本发明实施例提供了一种终端,包括存储器、处理器及存储在所述存储 器上并可在所述处理器上运行的计算机程序,其中,所述计算机程序被所述处理器执行时 实现上述语音会话的角色识别方法的步骤。 第四方面,本发明实施例提供了一种计算机可读存储介质,其上存储有计算机程 序,其中,所述计算机程序被处理器执行时实现上述语音会话的角色识别方法的步骤。 5 CN 111583906 A 说 明 书 2/8 页 本发明实施例中,利用预先训练的区分角色的语言模型和声学模型,识别得到待 识别语音会话中的每个语音片段的说话人身份,可以利用已知说话人身份的语音信息,充 分考虑声学特征以及文本特征,实现对语音会话的识别,从而相比于无监督的聚类方法,可 控性更高,实现对相应语音片段的说话人身份的有效识别。 附图说明 为了更清楚地说明本发明实施例的技术方案,下面将对本发明实施例中所需要使 用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于 本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其 他的附图。 图1为本发明实施例的语音会话的角色识别方法的流程图; 图2A为本发明实施例中确定语音片段的说话人身份的过程示意图之一; 图2B为本发明实施例中确定语音片段的说话人身份的过程示意图之二; 图3为本发明实施例中利用声学模型确定语音片段的得分的过程示意图; 图4为本发明实施例的语音会话的角色识别装置的结构示意图; 图5为本发明实施例的终端的结构示意图。











