
技术摘要:
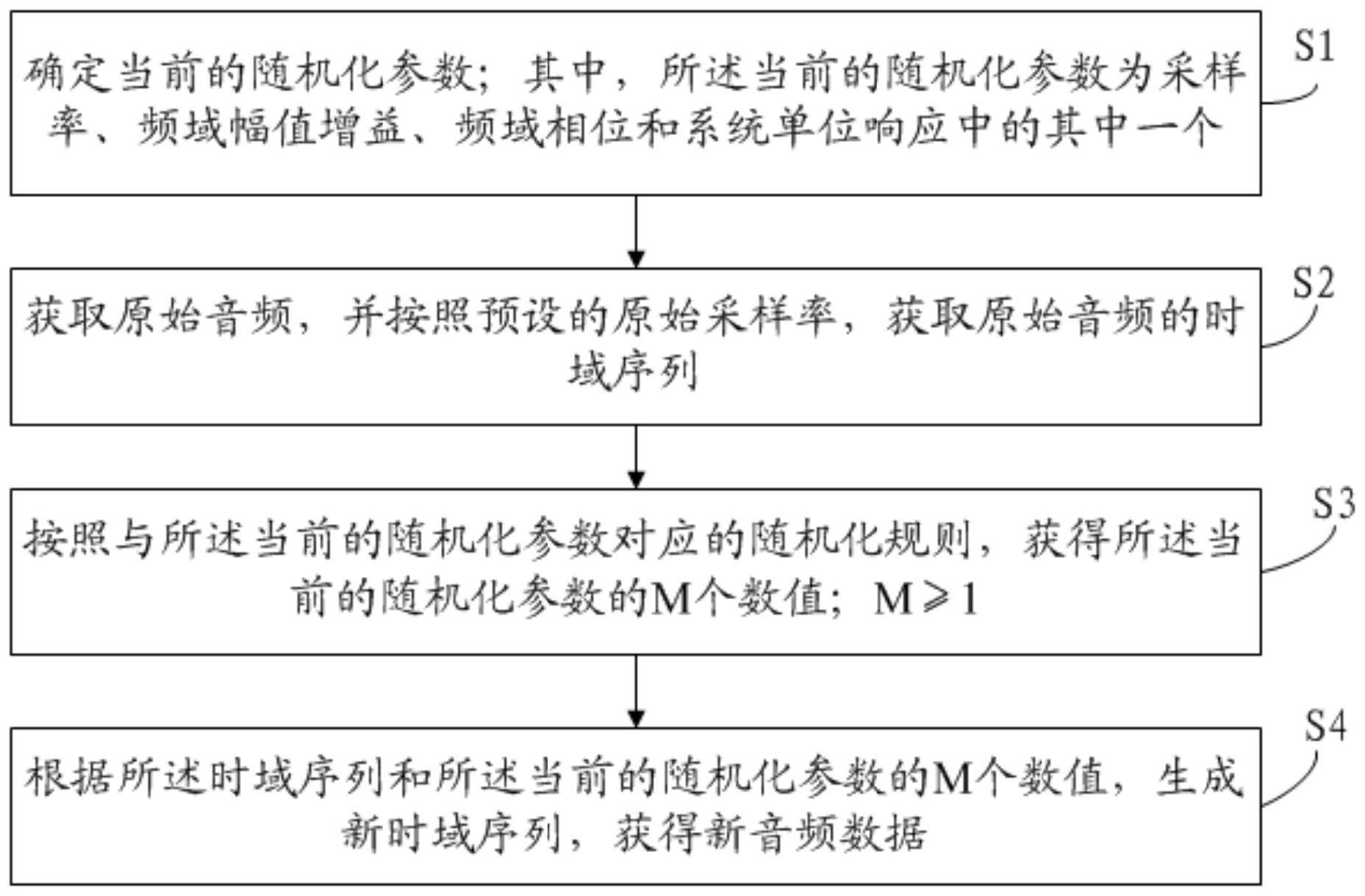
本发明公开了一种音频数据生成方法和装置,所述方法包括:确定当前的随机化参数;其中,所述当前的随机化参数为采样率、频域幅值增益、频域相位和系统单位响应中的其中一个;获取原始音频,并按照预设的原始采样率,获取原始音频的时域序列;按照与所述当前的随机化参 全部
背景技术:
在音频分类或语音识别等技术领域中,数据集的数量决定着分类任务、语音识别 任务的准确率。如果数据集的数量足够充足,模型得到训练拟合,将更有利于上层算法取得 良好的分类效果或识别效果。 目前,音频数据相对较少,而为了扩充音频数据,现有技术通常采用生成对抗网络 来生成符合要求的音频数据,以对相应的音频数据进行扩充。 然而,获得效果好的生成对抗网络,本身也需要大量的音频数据进行网络训练,因 此,对于音频数据不足的任务,现有技术的方案并不适用,现有技术无法在音频数据不足的 情况下扩充音频数据。
技术实现要素:
本发明实施例所要解决的技术问题在于,提供一种音频数据生成方法和装置,能 够在音频数据不足的情况下,对音频数据进行扩充。 第一方面,本发明实施例提供了一种音频数据生成方法,所述方法包括: 确定当前的随机化参数;其中,所述当前的随机化参数为采样率、频域幅值增益、 频域相位和系统单位响应中的其中一个; 获取原始音频,并按照预设的原始采样率,获取原始音频的时域序列; 按照与所述当前的随机化参数对应的随机化规则,获得所述当前的随机化参数的 M个数值;M≥1; 根据所述时域序列和所述当前的随机化参数的M个数值,生成新时域序列,获得新 音频数据。 进一步的,当所述当前的随机化参数为采样率时,M=1;则,所述按照与所述当前 的随机化参数对应的随机化规则,获得所述当前的随机化参数的M个数值,具体包括: 当所述当前的随机化参数为采样率时,在预设的采样率比值范围内随机生成一个 采样率比值; 根据所述采样率比值和所述原始采样率,计算目标采样率,获得所述当前的随机 化参数的一个数值。 进一步的,所述时域序列包括N个时域点;则,所述根据所述时域序列和所述当前 的随机化参数的M个数值,生成新时域序列,获得新音频数据,具体包括: 根据所述时域序列的N个所述时域点和预设的拟合算法,获得拟合时域函数; 按照所述目标采样率,从所述拟合时域函数中采集若干个新时域点; 根据所有的所述新时域点,生成所述新时域序列,获得所述新音频数据。 进一步的,所述按照与所述当前的随机化参数对应的随机化规则,获得所述当前 4 CN 111599369 A 说 明 书 2/9 页 的随机化参数的M个数值,具体包括: 当所述当前的随机化参数为频域幅值增益时,在预设的频域幅值增益范围内随机 生成M个增益值,以获得所述当前的随机化参数的M个数值。 进一步的,所述根据所述时域序列和所述当前的随机化参数的M个数值,生成新时 域序列,获得新音频数据,具体包括: 根据傅里叶变换算法和所述时域序列,获得所述原始音频的频域序列; 将所述频域序列划分成M个频域序列区间,并将M个所述频域序列区间分别与M个 所述增益值一一对应; 将所述频域序列中的每一个所述频域序列区间内的每一个频域点的幅值乘以所 对应的所述增益值,获得增益后的频域序列; 根据所述增益后的频域序列和傅里叶逆变换,生成所述新时域序列,获得所述新 音频数据。 进一步的,所述时域序列包括N个时域点;则,所述按照与所述当前的随机化参数 对应的随机化规则,获得所述当前的随机化参数的M个数值,具体包括: 当所述当前的随机化参数为频域相位时,在[-2π,2π]内随机生成M个随机相位值, 以获得所述当前的随机化参数的M个数值,M=N/2 1。 进一步的,所述根据所述时域序列和所述当前的随机化参数的M个数值,生成新时 域序列,获得新音频数据,具体包括: 根据傅里叶变换算法和所述时域序列,获得所述原始音频的频域序列;所述频域 序列包括M个频域点; 将所述频域序列中的M个频域点的相位值分别与M个所述随机相位值对应相加,获 得M个频域点对应的新相位值; 根据M个频域点对应的新相位值和所述频域序列,获得新频域序列; 根据所述新频域序列和傅里叶逆变换,生成所述新时域序列,获得所述新音频数 据。 进一步的,所述按照与所述当前的随机化参数对应的随机化规则,获得所述当前 的随机化参数的M个数值,具体包括: 当所述当前的随机化参数为系统单位响应时,获取通过预设的音频采集装置采集 的单位冲击信号; 截取所述单位冲击信号的前M个时域点,并根据所述M个时域点的幅值,获得包括M 个元素的系统单位响应数组; 保持所述系统单位响应数组中的前半部分的元素不变,并对所述系统单位响应数 组中的后半部分的每一个元素分别加上一个随机值,获得包括M个元素的新系统单位响应 数组,以获得所述当前的随机化参数的M个数值;其中,所述随机值的绝对值不超过预设的 阈值。 进一步的,所述根据所述时域序列和所述当前的随机化参数的M个数值,生成新时 域序列,获得新音频数据,具体包括: 对所述时域序列的N个时域点的幅值与所述新系统单位响应数组的M个元素进行 卷积计算,生成所述新时域序列,获得所述新音频数据。 5 CN 111599369 A 说 明 书 3/9 页 第二方面,本发明还提供了一种音频数据生成装置,所述装置包括: 确定模块,用于确定当前的随机化参数;其中,所述当前的随机化参数为采样率、 频域幅值增益、频域相位和系统单位响应中的其中一个; 时域序列获取模块,用于获取原始音频,并按照预设的原始采样率,获取原始音频 的时域序列; 随机化模块,用于按照与所述当前的随机化参数对应的随机化规则,获得所述当 前的随机化参数的M个数值;M≥1; 新音频数据获得模块,用于根据所述时域序列和所述当前的随机化参数的M个数 值,生成新时域序列,获得新音频数据。 上述提供的一种音频数据生成方法和装置,按照一定的随机化规则获得采样率、 频域幅值增益、频域相位或系统单位响应的M个随机化的数值,结合到有限的原始音频,生 成新音频数据,实现了在音频数据不足的情况下,对音频数据进行扩充。 附图说明 图1是本发明提供的一种音频数据生成方法的一个优选实施例的流程图; 图2是本发明提供的一种音频数据生成装置的一个优选实施例的结构示意图。











