
技术摘要:
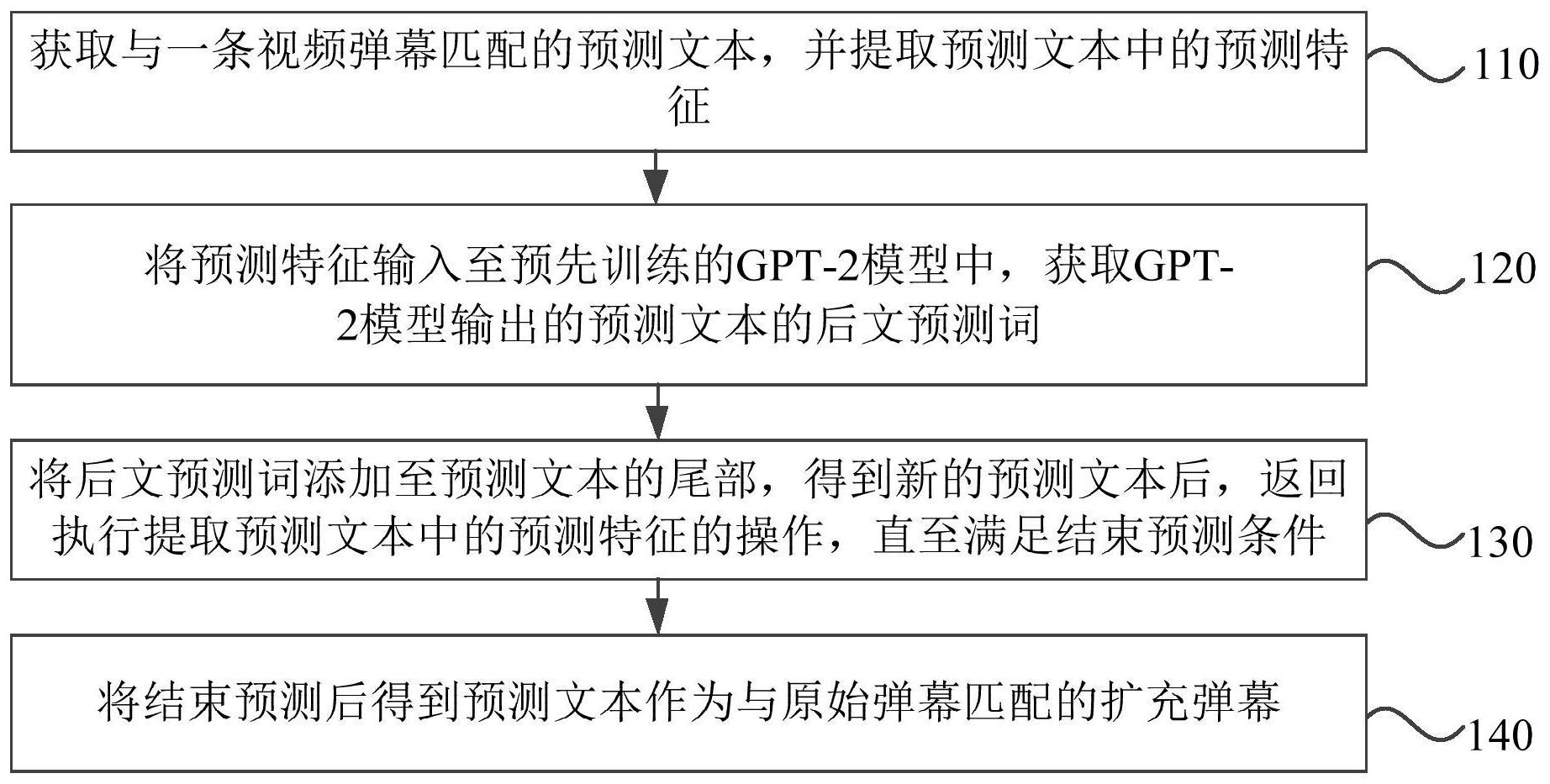
本发明实施例公开了一种视频弹幕的生成方法、装置、计算机设备及存储介质。其中,方法包括:获取与一条视频弹幕匹配的预测文本,并提取预测文本中的预测特征;将预测特征输入至预先训练的GPT‑2模型中,获取GPT‑2模型输出的预测文本的后文预测词,GPT‑2模型使用视频 全部
背景技术:
“弹幕”是用户在观看在线视频时发送的一种短文本,它们自上而下分布且以一定 速度从右到左飘过视频播放窗口。用户可以通过弹幕共享信息、表达评论、讨论话题或者社 交通讯等。这种体验提升了用户观看视频的兴致、乐趣、群体观看感以及交互感等。目前,大 部分视频站点均可以向用户提供弹幕功能。 一般来说,各个用户针对某一视频输入的历史弹幕可以存储在弹幕数据库中,当 该视频被再次播放后,可以从弹幕数据库中获取该历史弹幕进行播放。当某一个视频的历 史弹幕较少时,可以通过一定的弹幕扩充技术增加弹幕。 现阶段,可以通过视频评论信息对应的字符图像自动渲染生成弹幕,也可以基于 情绪信息和Seq2Seq(Sequence to Sequence,序列到序列)模型自动生成情绪反馈弹幕,以 增加弹幕。但是,现有技术的方法生成的弹幕一般与当前视频播放场景的匹配度较低,生成 弹幕的内容单一。
技术实现要素:
本发明实施例提供一种视频弹幕的生成方法、装置、计算机设备及存储介质,以实 现对视频中的原有弹幕进行扩充,且扩充的弹幕与当前视频播放场景的匹配度较高的弹 幕。 第一方面,本发明实施例提供了一种视频弹幕的生成方法,该方法包括: 获取与一条视频弹幕匹配的预测文本,并提取预测文本中的预测特征; 将预测特征输入至预先训练的GPT-2模型中,获取GPT-2模型输出的预测文本的后 文预测词,GPT-2模型使用视频关联文本,和/或视频弹幕训练得到; 将后文预测词追加至预测文本的尾部,得到新的预测文本后,返回执行提取预测 文本中的预测特征的操作,直至满足结束预测条件; 将结束预测后得到预测文本作为与原始弹幕匹配的扩充弹幕。 第二方面,本发明实施例还提供了一种视频弹幕的生成装置,该装置包括: 预测文本获取模块,用于获取与一条视频弹幕匹配的预测文本,并提取预测文本 中的预测特征; 后文预测词确定模块,用于将预测特征输入至预先训练的GPT-2模型中,获取GPT- 2模型输出的预测文本的后文预测词,GPT-2模型使用视频关联文本,和/或视频弹幕训练得 到; 新的预测文本确定模块,用于将后文预测词追加至预测文本的尾部,得到新的预 测文本后,返回执行提取预测文本中的预测特征的操作,直至满足结束预测条件; 4 CN 111556375 A 说 明 书 2/13 页 扩充弹幕确定模块,用于将结束预测后得到预测文本作为与原始弹幕匹配的扩充 弹幕。 第三方面,本发明实施例还提供了一种计算机设备,包括存储器、处理器及存储在 存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如本发明实 施例中任一实施例所述的视频弹幕的生成方法。 第四方面,本发明实施例还提供了一种包含计算机可执行指令的存储介质,所述 计算机可执行指令在由计算机处理器执行时用于执行如本发明实施例中任一实施例所述 的视频弹幕的生成方法。 本发明实施例通过获取与一条视频弹幕匹配的预测文本,并提取预测文本中的预 测特征,将预测特征输入至预先训练的GPT-2模型中,获取GPT-2模型输出的预测文本的后 文预测词,GPT-2模型使用视频关联文本,和/或视频弹幕训练得到;将后文预测词追加至预 测文本的尾部,得到新的预测文本后,返回执行提取预测文本中的预测特征的操作,直至满 足结束预测条件;将结束预测后得到预测文本作为与原始弹幕匹配的扩充弹幕,可以生成 任意内容的弹幕,实现了对视频中的弹幕进行扩充,同时,生成的弹幕能较好的融合与匹配 到视频播放场景中已有的弹幕。 附图说明 图1是本发明实施例一中的一种视频弹幕的生成方法的流程图; 图2是本发明实施例二中的一种视频弹幕的生产方法的流程图; 图3是本发明实施例二中的一种预训练数据集和微调数据集的获取流程图; 图4是本发明实施例二中的一种生成GPT-2预训练模型的流程图; 图5是本发明实施例二中的一种生成GPT-2模型的流程图; 图6是本发明实施例二中的一种生成GPT-2模型的流程图; 图7是本发明实施例二中的一种生成中文弹幕的流程图; 图8是本发明实施例二中的一种预训练过程中的loss变化曲线图; 图9是本发明实施例二中的一种微调训练过程中的loss变化曲线图; 图10是本发明实施例二中的生成的弹幕的示例图; 图11是本发明实施例三中的一种视频弹幕的生成装置的结构示意图; 图12是本发明实施例四中的一种计算机设备的结构示意图。











