
技术摘要:
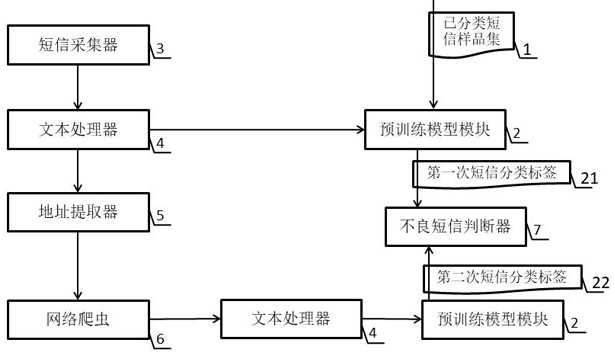
预训练模型加短信地址双重判定不良短信的方法和装置涉及信息技术领域。本发明由已分类短信样品集、预训练模型模块、短信采集器、文本处理器、地址提取器、网络爬虫和不良短信判断器组成;实现本发明解决传统机器学习在不良短信识别中对特征的依赖,与深度学习相比,不 全部
背景技术:
目前手机短信的信息安全问题已经得到了全社会的重视,不良短信识别方面的研 究,主要为基于文本分类的分析方式和基于短信中url的分析方式。 基于文本的不良信息分析中,主要是基于传统机器学习算法和基于深度学习的方 式。传统的机器学习,如发明专利号CN110147448A通过两重特征工程的构造,进行特征的选 择,不良短信的文本特征千变万化,传统的机器学习中文本特征提取办法并不能完全适用 于不良短信分类的实际情况;专利号CN110267272A采用将未知短信转化为向量,与存在黑 库中的短信进行相似度对比,相似度较高的则为不良短信,同样也依赖于特征选择来实现 文本的向量化,且对现有不良短信依赖较高,如果现有不良短信种类较少,很难判断出新的 不良短信。基于深度学习的方式,如CN108566627A和CN109982272A,需要大量的训练样本来 训练神经网络的参数,搜集海量样本的过程较长,且可能耗费大量人力物力资源。 基于短信中url的不良短信分析,如专利CN106941673A通过核对短信中url的ip信 息和收发短信方的ip是否一致,来判断是否为不良短信。这种方式缺乏数据支持,存在过于 片面的缺点。 现有技术说明 预训练模型XLNet 是一个类似 BERT 的模型,而不是完全不同的模型。总之,XLNet是 一种通用的自回归预训练方法。它是CMU和Google Brain团队在2019年6月份发布的模型, 最终,XLNet 在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效 果(state-of-the-art),包括机器问答、自然语言推断、情感分析和文档排序。作者表示, BERT 这样基于去噪自编码器的预训练模型可以很好地建模双向语境信息,性能优于基于 自回归语言模型的预训练方法。然而,由于需要 mask 一部分输入,BERT 忽略了被 mask 位置之间的依赖关系,因此出现预训练和微调效果的差异(pretrain-finetune discrepancy)。基于这些优缺点,该研究提出了一种泛化的自回归预训练模型 XLNet。 XLNet 可以: 通过最大化所有可能的因式分解顺序的对数似然,学习双向语境信息; 用自回归本身的特点克服 BERT 的缺点; 此外,XLNet 还融合了当前最优自回归模型 Transformer-XL 的思路。 XLNet与BERT比较 尽管看上去,XLNet在预训练机制引入的Permutation Language Model这种新的预训 练目标,和Bert采用Mask标记这种方式,有很大不同。其实深入思考一下,会发现,两者本质 是类似的。 区别主要在于: Bert是直接在输入端显示地通过引入Mask标记,在输入侧隐藏掉一部分单词,让这些 3 CN 111601314 A 说 明 书 2/4 页 单词在预测的时候不发挥作用,要求利用上下文中其它单词去预测某个被Mask掉的单词; 而XLNet则抛弃掉输入侧的Mask标记,通过Attention Mask机制,在Transformer内部 随机Mask掉一部分单词(这个被Mask掉的单词比例跟当前单词在句子中的位置有关系,位 置越靠前,被Mask掉的比例越高,位置越靠后,被Mask掉的比例越低),让这些被Mask掉的单 词在预测某个单词的时候不发生作用。 所以,本质上两者并没什么太大的不同,只是Mask的位置,Bert更表面化一些, XLNet则把这个过程隐藏在了Transformer内部而已。这样,就可以抛掉表面的[Mask]标记, 解决它所说的预训练里带有[Mask]标记导致的和Fine-tuning过程不一致的问题。至于说 XLNet说的,Bert里面被Mask掉单词的相互独立问题,也就是说,在预测某个被Mask单词的 时候,其它被Mask单词不起作用,这个问题,深入思考一下,其实是不重要的,因为XLNet在 内部Attention Mask的时候,也会Mask掉一定比例的上下文单词,只要有一部分被Mask掉 的单词,其实就面临这个问题。而如果训练数据足够大,其实不靠当前这个例子,靠其它例 子,也能弥补被Mask单词直接的相互关系问题,因为总有其它例子能够学会这些单词的相 互依赖关系。 当然,XLNet这种改造,维持了表面看上去的自回归语言模型的从左向右的模式, 这个Bert做不到,这个有明显的好处,就是对于生成类的任务,能够在维持表面从左向右的 生成过程前提下,模型里隐含了上下文的信息。所以看上去,XLNet貌似应该对于生成类型 的NLP任务,会比Bert有明显优势。另外,因为XLNet还引入了Transformer XL的机制,所以 对于长文档输入类型的NLP任务,也会比Bert有明显优势。
技术实现要素:
鉴于现有技术的不足,本发明提供的预训练模型加短信地址双重判定不良短信的 方法和装置由已分类短信样品集、预训练模型模块、短信采集器、文本处理器、地址提取器、 网络爬虫和不良短信判断器组成; 已分类短信样品集存储已分类的短信样品,已分类短信样品的数量大于150篇,且小于 1000篇; 预训练模型模块使用XLNet预训练模型对已分类短信样品集进行分类计算,对已分类 短信样品集进行分类计算后的预训练模型模块能够在输入文本的情况下对输入的文本给 出分类标签; 预训练模型模块对输入的文本给出分类标签的方法是程序加载XLNet预训练模型,先 格式化一个tf_record文件,然后对输入的文本进行特征提取,存入到tf_record文件中,作 为语义文件,使用softmax将文本的分类概率归一化,得到输入的文本所属的分类标签; 短信采集器负责采集待分类的短信内容; 文本处理器负责将待分类的短信内容进行去噪处理,生成提纯后的短信文本; 文本处理器去噪处理过程是通过正则表达式将语料中的用户名、停用词、转发符号和 标记信息去除,调用Python的re模块进行语料处理,本方法主要使用re.sub( )函数,此函 数的原型为:re.sub(pattern, repl, string , count=0, flags=0);此函数有五个参数, 分别是:匹配的正则表达式、用于替换的字符串、被替换的字符串、设置替换次数、标志位; 文本处理器将提纯后的短信文本发送给预训练模型模块,预训练模型模块对输入的提 4 CN 111601314 A 说 明 书 3/4 页 纯后的短信文本给出第一次短信分类标签; 文本处理器将提纯后的短信文本发送给地址提取器,地址提取器提取提纯后的短信内 容中的网络地址; 地址提取器的执行方式是用正则表达式扫描提纯后的短信内容,采用Python中的re模 块,提取文本中的短链接,使用长链接爬虫程序,将短链接输入进去,得出其对应的长链接, 短链接对应的长链接就是提纯后的短信内容中的网络地址; 地址提取器将提纯后的短信内容中的网络地址发送给网络爬虫,网络爬虫读取提纯后 的短信内容中的网络地址所对应页面的网页标题和网页内容生成网页文本;网页文本包括 网页标题和网页内容; 网络爬虫将网页文本发送给文本处理器,文本处理器负责将网页文本进行去噪处理, 生成提纯后的网页文本; 文本处理器将提纯后的网页文本发送给预训练模型模块,预训练模型模块对输入的提 纯后的网页文本给出第二次短信分类标签; 由不良短信判断器读取第一次短信分类标签和第二次短信分类标签;当一个未分类短 信只取得第一次短信分类标签,未取得第二次短信分类标签时,将第一次短信分类标签作 为判断依据;当一个未分类短信同时取得第一次短信分类标签和第二次短信分类标签时, 只有第一次短信分类标签和第二次短信分类标签同时为良性短信分类标签时,判断该未分 类短信为良性短信;当一个未分类短信同时取得第一次短信分类标签和第二次短信分类标 签时,第一次短信分类标签和第二次短信分类标签任意一个为不良短信分类标签时,判断 该未分类短信为不良短信。 有益效果 实现本发明解决传统机器学习在不良短信识别中对特征的依赖,与深度学习相比,不 仅不需要大量的训练集,而且可以通过短信中的url短链接进行判断,使得语义信息稀疏的 短信得到很好的识别;同时结合文本信息和短信地址来判断短信的性质比仅依据短信地址 的ip判断短信的性质拥有更好的解释性和更直观的分析效果。 附图说明 图1是本发明的系统结构图。











