
技术摘要:
本发明公开了一种基于高光谱图像的青梅糖酸度预测方法,包括以下步骤:采集青梅样品高光谱图像,对其进行反射率校准;获取每个青梅样品的平均光谱反射率;利用传统的理化检测方式采集青梅样品的SSC和pH结果,作为预测模型训练时的参考值;基于深度学习技术,设计多层网 全部
背景技术:
青梅又称梅果、梅子,是我国的特产水果之一,在国内已经有3000多年的种植历 史。青梅果实大,果核小,果肉以爽脆、酸鲜等特点收到人们的喜爱。除了口感独特,青梅同 时含有丰富的营养物质,果肉富含多种维生素、微量元素以及氨基酸等,这些营养物质保证 了人体的正常运行,医学界对青梅的研究也较多,认为青梅不仅具有丰富的营养物质,同时 对普遍存在的心血管、泌尿、消化系统疾病有明显的预防作用和疗效,对健康有较大益处, 因此青梅也会被加工为保健品进行销售,受到消费者的欢迎。青梅很少被直接食用,因为有 大量的酸和苦杏仁甙存在于果肉中,导致其直接食用时味道酸苦,进行加工后可以解决该 问题,因此青梅会被加工为其他产品,如梅酒、梅精等。 青梅虽然是我国的传统水果,但青梅产业并未受到重视,表现为落后的生产方式、 单一的加工品种,并多以原果进行销售,使得青梅的综合利用率较低,青梅的市场比较平 淡。近年来一些对于青梅需求较大的国家,如日本、泰国等,从我国大量进口青梅原果,导致 我国青梅的产量不断上升,逐渐出现供大于求的现象,使得青梅产品的价格收到限制。青梅 产业需要做出转型,改变目前粗放的生产方式,增加青梅深加工产品,将成分不同的青梅加 工为不同的产品,提升产品品质,提高青梅的附加价值,进而提升农民收入,增加企业利润。 青梅中糖度和酸度是青梅在进行深加工时考虑的重要成分指标,比如青梅酒在加 工时,需要糖度高、酸度低的青梅原果,而青梅精在加工时,需要糖度低、酸度高的青梅原 果。在不同的时节,青梅内部的成分含量不同,甚至在相同时间,不同果实之间的成分含量 也有较大的差异。人工采摘时,工人会根据青梅的颜色、采摘时间等因素,凭经验判断其成 分含量并进行分类,但受到品种、光照、地域以及工人经验等因素的影响,分类的效果较低。 由于传统的理化方式测定青梅的成分含量,需要对青梅进行破坏,且检测效率低,无法满足 实际生产的需求。因此研究新的青梅成分无损检测方法,可以为青梅产业提供技术支撑,提 高青梅生产的自动化、智能化水平以及青梅产品的质量,具有重要意义和实际应用价值。
技术实现要素:
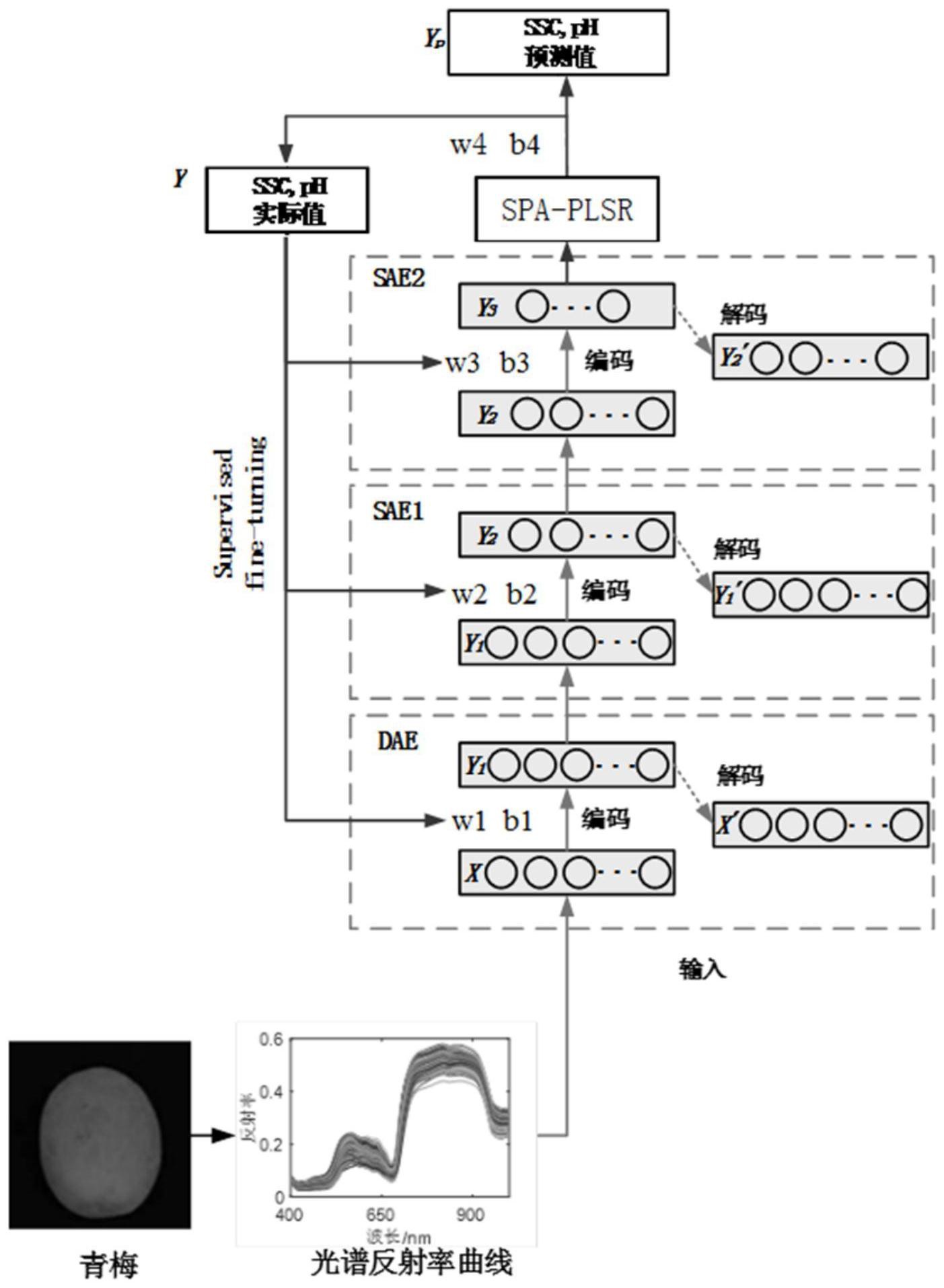
本发明所要解决的技术问题是针对上述现有技术的不足提供一种基于高光谱图 像的青梅糖酸度预测方法,本基于高光谱图像的青梅糖酸度预测方法基于深度学习技术, 提出一种深度学习模型,提高青梅糖度值和酸度值的预测精度,从而实现青梅成分的无损 检测,检测效率高。 为实现上述技术目的,本发明采取的技术方案为: 基于高光谱图像的青梅糖酸度预测方法,包括以下步骤: (1)利用高光谱采集系统采集青梅的光谱信息;同时采集当天系统的暗噪光谱图 4 CN 111595790 A 说 明 书 2/7 页 像和99%反射率的标准反射率标定板光谱图像,对青梅的光谱图像分别进行反射率校准; (2)选取校准后的光谱图像中的青梅部分,计算其平均光谱反射率,作为青梅样本 数据; (3)利用糖度计和ph计对青梅进行理化检测,得到青梅的糖度值和酸度值; (4)搭建多层网络结构的DSAE-SPA-PLSR预测模型,所述DSAE-SPA-PLSR预测模型 的网络结构包含降噪自编码器DAE、稀疏自编码器SAE1、稀疏自编码器SAE2以及连续投影算 法-偏最小二乘回归SPA-PLSR;所述DSAE-SPA-PLSR预测模型的网络结构的输入层是光谱图 像中的青梅部分的平均光谱反射率结果,隐含层一是降噪自编码器DAE的隐含层,隐含层二 是稀疏自编码器SAE1的隐含层,隐含层三是稀疏自编码器SAE2的隐含层,隐含层四是连续 投影算法-偏最小二乘回归SPA-PLSR,输出层是青梅糖度值和酸度值的预测结果; 首先用降噪自编码器DAE对青梅样本中青梅平均光谱反射率进行预训练,训练后 将降噪自编码器DAE的隐含层数据传递给稀疏自编码器SAE1,训练稀疏自编码器SAE1,训练 后将稀疏自编码器SAE1的隐含层数据传递给稀疏自编码器SAE2,训练稀疏自编码器SAE2; 预训练后可以得到降噪自编码器DAE、稀疏自编码器SAE1和稀疏自编码器SAE2的权重和偏 置,用其初始化DSAE-SPA-PLSR预测模型的参数; (5)利用青梅样本数据训练DSAE-SPA-PLSR预测模型,得到训练好的DSAE-SPA- PLSR预测模型,将青梅样本数据中的平均光谱反射率输入到训练好的DSAE-SPA-PLSR预测 模型,得到糖度值和酸度值的预测结果Yp; (6)将预测结果Yp与实际结果Y进行对比,得到预测误差,依据反向调节机制,调整 网络结构中隐含层一、隐含层二和隐含层三的权重和偏置,其中隐含层四的权重和偏置通 过自身更新;从而最终拟合出接近于真实情况的DSAE-SPA-PLSR预测模型; (7)将需要进行糖酸度预测的青梅的平均光谱反射率输入到最后得到的DSAE- SPA-PLSR预测模型中,预测出青梅的糖度值和酸度值; (8)对青梅糖度值预测结果和酸度值预测结果进行可视化表示。 作为本发明进一步改进的技术方案,所述的对青梅的光谱图像进行反射率校准的 公式为: 其中,A0为黑白校准后的青梅光谱反射率数据,A为青梅光谱原始数据,AD为暗场光 谱反射率数据,Aw为99%反射率板的光谱数据。 作为本发明进一步改进的技术方案,所述的步骤(2)具体包括: 对校准后的青梅高光谱图像进行数据提取,使用ENVI5.3软件ROI工具手动选取图 像中青梅部分,计算其平均光谱反射率,作为该图像的反射率结果,具体计算方式为: 其中,Xo为平均光谱反射率,Xi为第i个像素点的光谱反射率,n为像素点总数。 作为本发明进一步改进的技术方案,所述的步骤(6)中权重和偏置调整量公式分 别为: 5 CN 111595790 A 说 明 书 3/7 页 其中ΔWi为第i层权重的调整量,ΔBi为第i层偏置的调整量,E为输出结果与实际 结果的偏差,Wi为第i层向第i 1层传递的权重,Bi为第i层向第i 1层传递的偏置,Xi为第i层 的输入,η为梯度下降比例系数; 隐含层一的权重和偏置调整量公式中的δi 1为: δi 1=δi 2Wi 1f′(WiXi Bi); 隐含层二和隐含层三的权重和偏置调整量公式中的δi 1均为: 其中β为稀疏性惩罚因子的权重,ρ为稀疏性参数,为隐含层神经元的平均激活 度; 输出层的δ5计算公式为: δ5=-(Yp-Y)f′(W4X4 B4); 其中:f′(W4X4 B4)=1; 对于隐含层一、隐含层二和隐含层三,有: f′(WiXi Bi)=(WiXi Bi)(1-(WiXi Bi))。 本发明的有益效果为:本发明的方法打破了传统方法的限制,融合深度学习技术, 基于降噪自编码器(DAE)和稀疏自编码器(SAE)建立青梅糖酸度预测模型:DSAE-SPA-PLSR。 利用DSAE-SPA-PLSR模型预测青梅糖酸度,相比传统的预测模型,有更好的预测效果。实现 了青梅成分的无损检测,检测效率高。 附图说明 图1为青梅样本中部分青梅的高光谱图像。 图2为青梅样本的平均光谱反射率曲线图。 图3为青梅样本中某个青梅高光谱图像。 图4为青梅样本中某个青梅平均光谱反射率曲线图。 图5为青梅的糖度值预测结果可视化表示图。 图6为青梅的酸度值预测结果可视化表示图。 图7为DSAE-SPA-PLSR预测模型图。











