
技术摘要:
本发明公开了一种基于上下文信息的音符向量的自动作曲系统及方法,该方法步骤如下:首先通过MIDI音乐预处理模块对MIDI音乐文件进行预处理,提取包含音高和音长两个音素的主旋律音符序列;然后将主旋律音符序列送入音符向量编码模块,该模块用于训练生成带有上下文信息 全部
背景技术:
随着经济社会的发展,人们对精神生活提出了更高要求。当今社会,人们的娱乐生 活更加丰富与多样,而音乐是一种特殊的社会意识形态,不仅能陶冶情操、调节情绪,还能 开发思维、焕发情感,具有极强的感染力,在娱乐、学习、医疗、教育等方面起到不可或缺的 作用。 作曲家们不断尝试新的手法和技巧来满足人们的新需求。随着移动互联网的发 展,多媒体短视频用户量持续增加。众多的短视频、游戏、动画等都需要大量的原创作曲来 支持,而专业的音乐制作成本较高,无法满足用户对背景乐的个性化需要。随着机器学习的 发展,计算机自动作曲将大大提高音乐创作力,同时辅助作曲家开拓新的创作思路。 目前,已经出现的很多种自动作曲的方案中,使用的音乐数据格式通常是MIDI,作 曲网络通常使用循环神经网络(RNN,Recurrent Neural Network)以及它的变种长短时记 忆(LSTM,Long Short-Term Memory)网络和门控循环单元(GRU,Gated Recurrent Unit)网 络。通过直接提取MIDI中的音符特征,直接利用这些从MIDI中提起的原始的音符特征进行 训练和生成音乐。这样,原始的音符特征都是独立的,离散的,它们之间没有必要的联系,而 将整个作曲规则的学习完全寄托在作曲网络上。 当然,这在大数据集上去训练和生成音乐是没有问题的,但是实际生活中,不同风 格的音乐数据集的分布是及其不均匀的,例如:流行风格的音乐颇多而古典风格的音乐颇 少,更少的是一些小众音乐。对于小众音乐的自动作曲,由于无法收集到足够的数据集,这 样即使作曲网络搭建的很完美,没有足够的数据量的支持,作曲网络无法很好的学习到音 乐中音符的上下文关系,从而使自动作曲的效果大打折扣。 为了解决这个问题,发明人在本发明的提出过程中至少发现如下启示:借鉴自然 语言处理领域的技术---词向量模型(word2vec),在音乐的数据表征中做出优化,使得输入 到作曲网络中的数据不再是从MIDI音乐中提取的原始数据,而是经过处理后而带有上下文 信息的音符向量表示的音符序列。词向量模型是将自然语言中的词转化为稠密的向量,语 义相似的词会有相似的向量表示,因此词向量是带有上下文信息的。 词向量模型是能很好的借鉴运用到自动作曲领域的,因为音乐本身就是由一个音 符组成,那么音符就可以看成词向量模型中的词,通过预训练使得在数据的表征中就带有 整个音乐的上下文信息,这样做能带来两点好处:一是能提高音符预测的准确性,二是由于 音符本身带有上下文信息,因此作曲网络能更快地预测出自己周围的音符,从而缩短作曲 网络的训练时间。这样,通过带有上下文信息的数据表征和作曲网络两大模块,能更好地保 证自动作曲的效率和质量。 4 CN 111583891 A 说 明 书 2/6 页
技术实现要素:
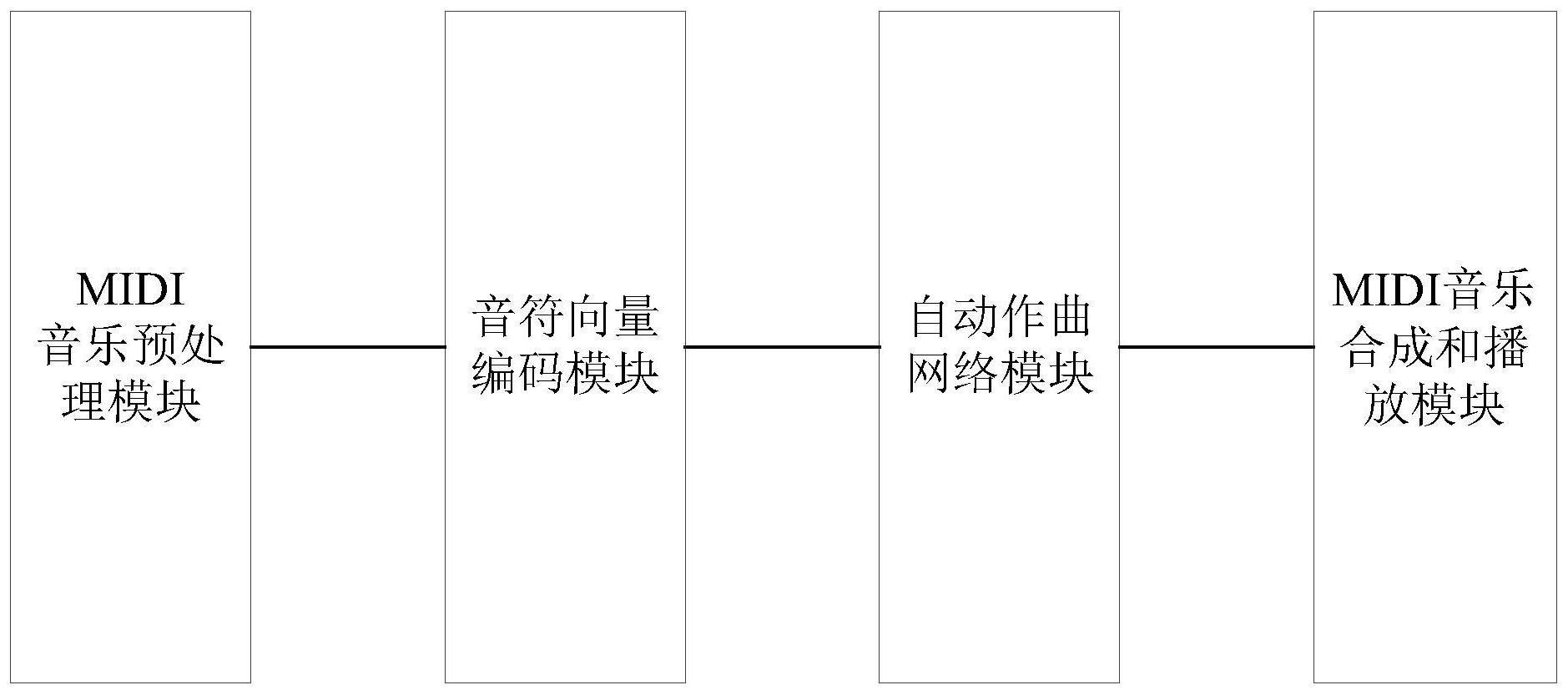
本发明的目的是为了解决现有技术中的上述缺陷,提供一种基于上下文信息的音 符向量的自动作曲系统及方法,对音符首先训练和生成带有上下文信息的音符向量,然后 使用训练生成的音符向量表征音符序列送入作曲网络进行训练生成音乐,可以提高音符生 成的准确性和缩短作曲网络的训练时间。 本发明的第一个目的可以通过采取如下技术方案达到: 一种基于上下文信息的音符向量的自动作曲系统,所述的自动作曲系统包括依次 顺序连接的MIDI音乐预处理模块、音符向量编码模块、自动作曲网络模块、MIDI音乐合成和 播放模块, 其中,所述的MIDI音乐预处理模块对MIDI音乐文件预处理确定主旋律音轨并提取 音符序列,该音符序列包括音高和音长两个音素; 所述的音符向量编码模块对预处理获得的音符序列形成[输入音符,目标音符]的 二元数据组,接着经过训练生成带有上下文信息的音符向量,并且形成用音符向量表示的 音符序列; 所述的自动作曲网络模块将基于音符向量表示的音符序列作为作曲网络的训练 数据,进行音符的训练和生成,形成待作曲的音符序列; 所述的MIDI音乐合成和播放模块将自动作曲模块生成的待作曲的音符序列还原 成MIDI音频文件进行播放。 进一步地,所述的MIDI音乐预处理模块的工作过程如下: 首先去除打击乐器音轨,选取平均音高最高的三个为候选主旋律音轨,再通过音 轨时长占比音乐时长比例因子大小,最终根据时长比例因子从候选主旋律音轨中确定唯一 的主旋律音轨; 接着在主旋律音轨上利用轮廓线算法去除同时出现多个音符的现象即多音提取 出主旋律音高序列和音长序列; 最后对音高和音长采用组合编码的方式,形成包含音高和音长两个音素的主旋律 音符序列。 进一步地,所述的对音高和音长采用组合编码的方式的规则如下: MIDI中有128个音高,将音高编号为0-127,音长包括十六分音符、八分音符、四分 音符、二分音符和全音符,对音高和音长组合编码后共640种可能,其音符编号为0-639。 进一步地,所述的音符向量编码模块采用跳字算法训练生成带有音符上下文的音 符向量,并使用生成的音符向量取代音高和音长组合编码的音符编号形成用音符向量表示 的音符序列,工作过程如下: 首先按照跳字算法的要求处理数据,选择合适的上下文窗口,并根据设置的上下 文窗口大小对音符序列处理形成形式为[输入音符,目标音符]的二元数据组; 将二元数据组作为音符向量训练和生成网络的输入音符,其中,所述的音符向量 训练和生成网络采用前馈神经网络结构,包括输出层、隐藏层和输出层。数据从输入层输 入,顺序经过隐藏层到输出层输出。各层之间采用全连接的方式,隐藏层的神经元之间没有 连接均是独立的。将音符向量训练和生成网络的输出和二元数据组的目标音符作对比计算 误差,当音符向量训练和生成网络收敛时,隐藏层的参数就是训练生成的带有上下文信息 5 CN 111583891 A 说 明 书 3/6 页 的音符向量; 使用生成的音符向量取代音高和音长组合编码的音符编号形成用音符向量表示 的音符序列。 进一步地,所述的自动作曲网络模块通过神经网络模型预测训练和生成待作曲的 音符序列,该神经网络模型选择门控循环单元(GRU,Gated Recurrent Unit)网络的结构, 包括输入层、隐藏层和输出层。整体上音符序列从输入层输入顺序经过隐藏层到达输出层 输出,在隐藏层内部神经元之间通过连接形式可以充分利用输入音符序列的时序依赖信 息,有利于音乐的生成。选择交叉熵函数作该神经网络模型的损失函数。 进一步地,所述的神经网络模型的训练过程为: 通过前n个音符输入,预测第n 1的音符,将神经网络模型输出的第n 1个音符和第 n 1个目标音符作对比,然后将输入的音符序列依次向后滑动一个音符距离,再预测第n 2 个音符,将神经网络模型输出的第n 2个音符和第n 2个目标音符作对比,进行迭代训练,直 到神经网络模型收敛保存得到收敛模型。 进一步地,所述的神经网络模型的预测生成过程为:随机的选择n个音符,输入保 存的收敛模型中,预测出第n 1个音符,将输出的音符替换输入的最后一个音符同时去除开 头的第一个音符再次作为输入,再生成下一个音符;依次迭代,直到生成预先设置的S个音 符结束。 进一步地,所述的MIDI音乐合成和播放模块将自动作曲网络模块生成的待作曲的 音符序列还原成MIDI文件,并通过播放软件或者硬件进行播放和评价,从而完成整个作曲 工作。 本发明的另一个目的可以通过采取如下技术方案达到: 一种基于上下文信息的音符向量的自动作曲方法,所述的自动作曲方法包括以下 步骤: 对MIDI音乐文件预处理确定主旋律音轨并提取音符序列,该音符序列包括音高和 音长两个音素; 将预处理获得的音符序列形成[输入音符,目标音符]的二元数据组,接着经过训 练生成带有上下文信息的音符向量,并且形成用音符向量表示的音符序列; 将基于音符向量表示的音符序列作为作曲网络的训练数据,进行音符的训练和生 成,形成待作曲的音符序列; 将待作曲的音符序列还原成MIDI音频文件进行播放。 本发明相对于现有技术具有如下的优点及效果: 1)在数据的表征上,使得音符的表示带有上下文信息,让作曲网络更容易做出音 符的预测,提高了音符预测的准确性; 2)相较于直接采用MIDI中提取出的原始数据作曲,该方案更能缩短作曲网络的训 练时间,即作曲模型的收敛时间; 3)采用音高和音长组合编码的方式,保存原始音乐的音高和音长关系,训练和生 成的音符也包含着音高和音长两个元素; 4)音符向量训练的过程中有对音符数据的压缩过程,可以有效的缓解作曲网络的 训练压力。 6 CN 111583891 A 说 明 书 4/6 页 附图说明 图1是本发明实施例中公开的基于带有上下文信息的音符向量的自动作曲系统的 组成结构图。 图2是本发明实施例中利用轮廓线(skyline)算法的MIDI文件预处理提取音符的 音高和音长序列以及组合编码的具体流程图; 图3是本发明实施例中获取二元数据组的具体流程图; 图4是本发明实施例中音符向量训练模型结构示意图。











