
技术摘要:
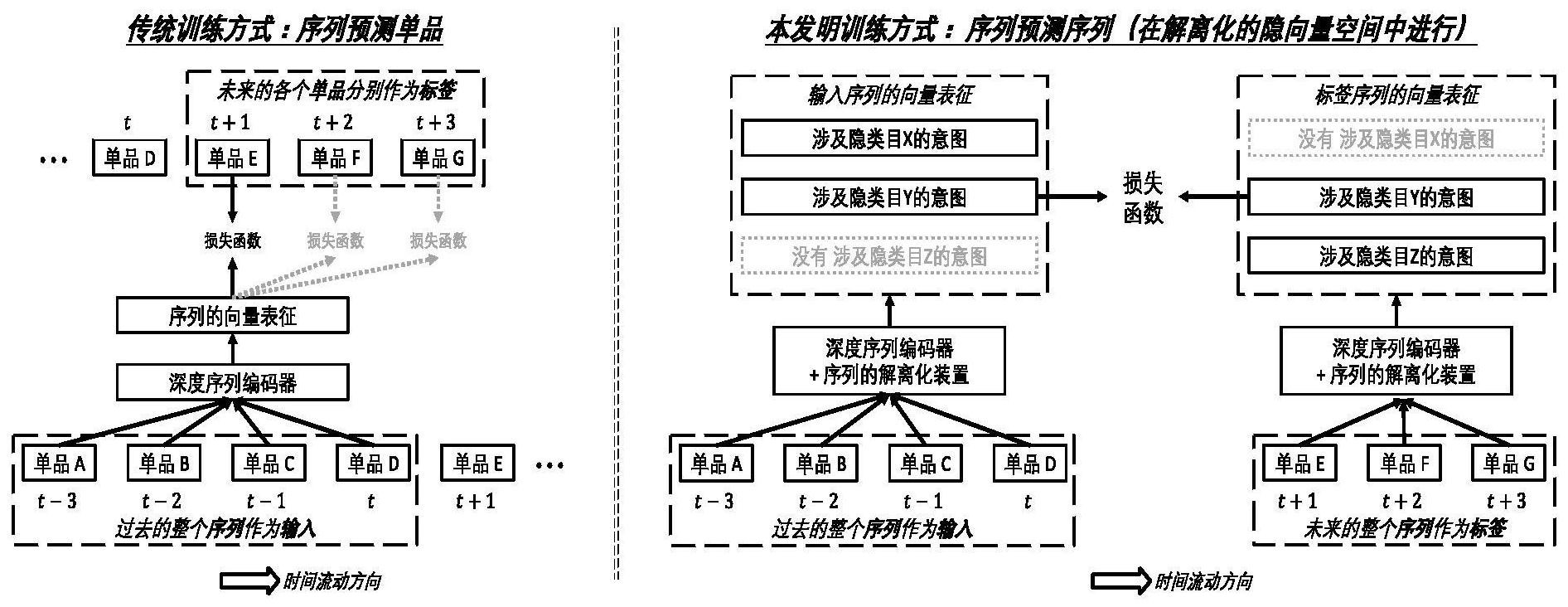
本发明公开了一种序列推荐模型的解离化自监督学习方法及装置,其中,该方法包括以下步骤:将每个用户点击过的多个单品按照时间顺序构成序列;构建具备意图解离化技术的序列编码器;将序列输入序列编码器中,将序列分解成输入序列和标签序列,利用输入序列预测标签序列 全部
背景技术:
以Recurrent Neural Networks、Transformer等为代表的深度序列模型已经成为 当前工业级推荐系统最核心的技术之一。当前主流的训练深度序列模型的方法采用的是序 列至单品的形式,每个训练样本的输入是一个用户某时间点之前点击过的单品构成的序 列,训练样本的标签是这个用户在该时间点后点击的下一个单品。但在推荐系统中,用户经 常会漫无目的地点击一个单品,导致该训练方式容易受噪声数据的影响。
技术实现要素:
本发明旨在至少在一定程度上解决相关技术中的技术问题之一。 为此,本发明的一个目的在于提出一种序列推荐模型的解离化自监督学习方法, 该方法克服使用未来的单品作为标签时的易被噪声样本误导的问题,避免无关信息的干 扰,且提升了收敛速度。 本发明的另一个目的在于提出一种序列推荐模型的解离化自监督学习装置。 为达到上述目的,本发明一方面实施例提出了序列推荐模型的解离化自监督学习 方法,包括以下步骤:步骤S1,将每个用户点击过的多个单品按照时间顺序构成序列;步骤 S2,构建具备意图解离化技术的序列编码器;步骤S3,将所述序列输入所述序列编码器中, 将所述序列分解成输入序列和标签序列,利用所述输入序列预测所述标签序列,获得多个 向量表征;步骤S4,利用所述多个向量表征训练序列推荐模型,训练后的序列推荐模型为每 个用户作出感兴趣的推荐。 本发明实施例的序列推荐模型的解离化自监督学习方法,利用未来的全部单品构 成的整个序列作为训练标签,而不是传统的以未来的单个单品作为训练标签,丰富了训练 数据的来源;利用解离化技术,把历史序列和未来序列中的多个意图拆分开,以便在训练过 程中只关注历史序列中与未来序列涉及共同意图的部分,避免无关意图的干扰,从而提升 训练数据的信噪比;采用预测“整个未来序列的向量表征”,而不是逐个预测“未来序列中的 单品”的做法,从而减少了冗余的预测、大大提升了收敛速度。 另外,根据本发明上述实施例的序列推荐模型的解离化自监督学习方法还可以具 有以下附加的技术特征: 进一步地,在本发明的一个实施例中,在深度序列模型的基础上引入一个意图解 离化装置,进而构建出所述具备意图解离化技术的序列编码器。 进一步地,在本发明的一个实施例中,所述序列编码器随机选择一个时间点前的 全部单品构成的整个序列作为所述输入序列,所述一个时间点后的全部单品构成的整个序 列作为所述标签序列。 4 CN 111582492 A 说 明 书 2/6 页 进一步地,在本发明的一个实施例中,所述步骤S3包括:将所述序列输入所述序列 编码器中,将所述序列分解成输入序列和标签序列;将所述输入序列中的多个消费意图拆 分,获得多个历史向量表征;利用所述多个历史向量表征预测所述标签序列的多个未来预 测向量表征;将所述标签序列中的多个消费意图拆分,获得多个未来实际向量表征;比较所 述多个未来预测向量表征与所述多个未来实际向量表征,获得预测误差;判断所述预测误 差是否高于预设阈值,则利用所述预测误差处理所述多个历史向量表征,得到所述多个向 量表征,否则,无视该次预测。 为达到上述目的,本发明另一方面实施例提出了序列推荐模型的解离化自监督学 习装置,包括:构造模块,用于将每个用户点击过的多个单品按照时间顺序构成序列;构建 模块,用于构建具备意图解离化技术的序列编码器;预测模块,用于将所述序列输入所述序 列编码器中,将所述序列分解成输入序列和标签序列,利用所述输入序列预测所述标签序 列,获得多个向量表征;训练模块,用于利用所述多个向量表征训练序列推荐模型,训练后 的序列推荐模型为每个用户作出感兴趣的推荐。 本发明实施例的序列推荐模型的解离化自监督学习装置,利用未来的全部单品构 成的整个序列作为训练标签,而不是传统的以未来的单个单品作为训练标签,丰富了训练 数据的来源;利用解离化技术,把历史序列和未来序列中的多个意图拆分开,以便在训练过 程中只关注历史序列中与未来序列涉及共同意图的部分,避免无关意图的干扰,从而提升 训练数据的信噪比;采用预测“整个未来序列的向量表征”,而不是逐个预测“未来序列中的 单品”的做法,从而减少了冗余的预测、大大提升了收敛速度。 另外,根据本发明上述实施例的序列推荐模型的解离化自监督学习装置还可以具 有以下附加的技术特征: 进一步地,在本发明的一个实施例中,在深度序列模型的基础上引入一个意图解 离化装置,进而构建出所述具备意图解离化技术的序列编码器。 进一步地,在本发明的一个实施例中,所述序列编码器随机选择一个时间点前的 全部单品构成的整个序列作为所述输入序列,所述一个时间点后的全部单品构成的整个序 列作为所述标签序列。 进一步地,在本发明的一个实施例中,所述预测模块包括:分解单元,用于将所述 序列输入所述序列编码器中,将所述序列分解成输入序列和标签序列;第一拆分单元,用于 将所述输入序列中的多个消费意图拆分,获得多个历史向量表征;预测单元,用于利用所述 多个历史向量表征预测所述标签序列的多个未来预测向量表征;第二拆分单元,用于将所 述标签序列中的多个消费意图拆分,获得多个未来实际向量表征;比较单元,用于比较所述 多个未来预测向量表征与所述多个未来实际向量表征,获得预测误差;判断单元判断所述 预测误差是否高于预设阈值,则利用所述预测误差处理所述多个历史向量表征,得到所述 多个向量表征,否则,无视该次预测。 本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变 得明显,或通过本发明的实践了解到。 附图说明 本发明上述的和/或附加的方面和优点从下面结合附图对实施例的描述中将变得 5 CN 111582492 A 说 明 书 3/6 页 明显和容易理解,其中: 图1为根据本发明一个实施例的序列推荐模型的解离化自监督学习方法的流程 图; 图2为根据本发明一个实施例的步骤S3中预测过程示意图; 图3为根据本发明一个实施例的序列推荐模型的解离化自监督学习装置的结构示 意图。











