
技术摘要:
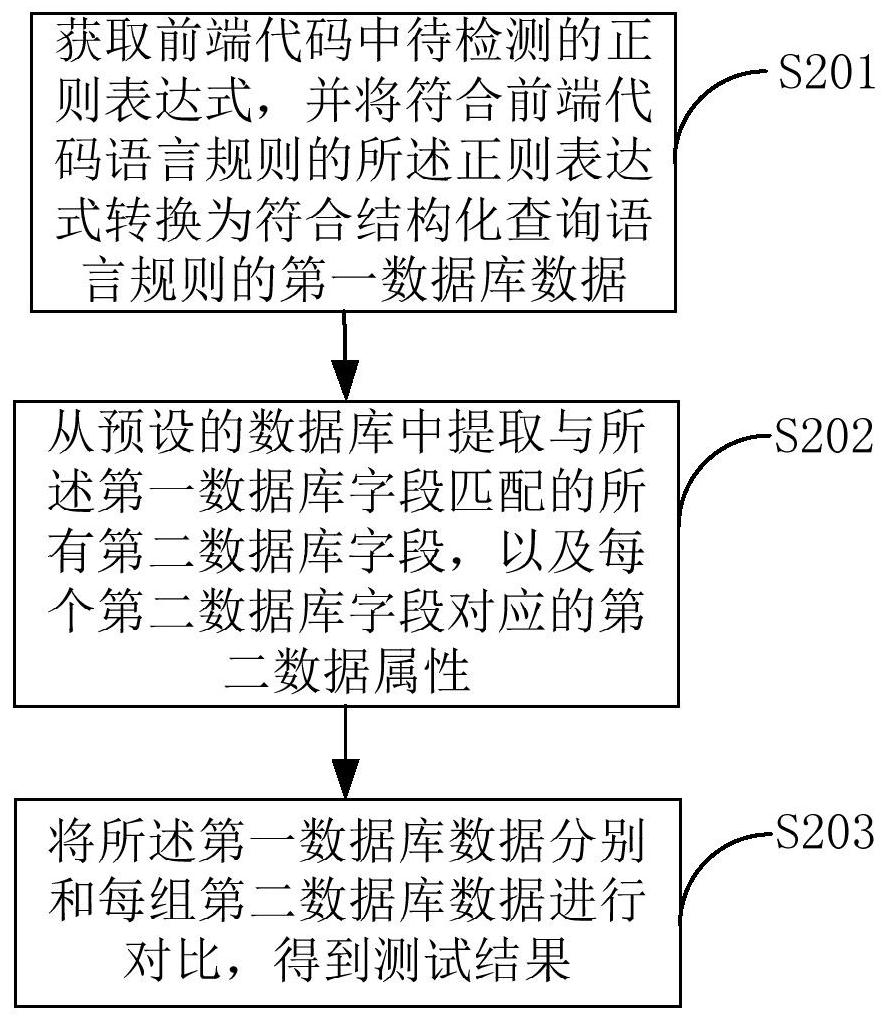
本申请适用于计算机领域,提供了一种数据库结构测试方法、数据库结构测试装置及终端设备,所述方法包括:获取前端代码中待检测的正则表达式,并将符合前端代码语言规则的所述正则表达式转换为符合结构化查询语言规则的第一数据库数据;从预设的数据库中提取与所述第一 全部
背景技术:
在软件开发过程中,通常是在数据库中对数据的属性进行定义。例如:定义某个对 话框中的数据属性为数值。由于前端开发人员对数据属性的关注度不够,经常会出现前端 获取的数据属性与数据库定义的数据属性不同的情况。这就需要进行数据库结构测试。 现有的数据库结构测试方法,通常是由测试人员进行穷举测试。例如:对某个对话 框中的数据属性进行测试时,需要逐一输入不同属性的数据,以确认该对话框中的数据属 性是否正确。这样的测试方法效率较低,并且由于测试人员的惯性思维,测试结果的准确率 也较低。
技术实现要素:
本申请实施例提供了一种数据库结构测试方法、数据库结构测试装置及终端设 备,可以解决现有的数据库结构测试方法的测试效率较低、测试结果准确率较低的问题。 第一方面,本申请实施例提供了一种数据库结构测试方法,所述方法包括: 获取前端代码中待检测的正则表达式,并将符合前端代码语言规则的所述正则表 达式转换为符合结构化查询语言规则的第一数据库数据,其中,所述第一数据库数据包括 第一数据库字段以及所述第一数据库字段对应的第一数据属性; 从预设的数据库中提取与所述第一数据库字段匹配的所有第二数据库字段,以及 每个第二数据库字段对应的第二数据属性; 将所述第一数据库数据分别和每组第二数据库数据进行对比,得到测试结果,其 中,每组第二数据库数据中包括一个第二数据库字段以及与所述第二数据库字段对应的第 二数据属性。 在第一方面的一种可能的实现方式中,所述将符合前端代码语言规则的所述正则 化表达式转换为符合结构化查询语言规则的第一数据库数据,包括: 获取所述前端代码语言规则与后端代码语言规则之间的预设映射关系,根据所述 预设映射关系将所述正则表达式转换为符合所述后端代码语言规则的后端数据,所述后端 数据包括至少一个后端代码字段和各个后端代码字段对应的第三数据属性; 对于每个后端代码字段,将所述后端代码字段转换成符合结构化查询语言规则的 第一数据库字段,并将所述第一数据库字段对应的第一数据属性设置为所述后端代码字段 对应的第三数据属性。 在第一方面的一种可能的实现方式中,所述根据所述预设映射关系将所述正则表 达式转换为符合所述后端代码语言规则的后端数据,包括: 根据所述预设映射关系识别出所述正则表达式对应的后端代码函数; 4 CN 111597164 A 说 明 书 2/11 页 根据所述后端代码函数的定义规则,从所述后端代码函数中提取出所述后端代码 字段和所述后端代码字段对应的第三数据属性,得到所述后端数据。 在第一方面的一种可能的实现方式中,所述将所述第一数据库数据分别和每组第 二数据库数据进行对比,得到测试结果,包括: 对于每个第一数据库字段,在各组第二数据库数据中查找与所述第一数据库字段 相同的第二数据库字段; 若在各组第二数据库数据中未查找到与所述第一数据库字段相同的第二数据库 字段,则生成第一异常结果,所述第一异常结果用于表示所述第二数据库数据中不存在与 所述第一数据库字段相同的第二数据库字段; 若在各组第二数据库数据中查找到与所述第一数据库字段相同的第二数据库字 段,则根据第一集合以及第二集合生成测试结果,其中,所述第一集合为所述第一数据库字 段对应的第一数据属性的集合,所述第二集合为与所述第一数据库字段相同的第二数据库 字段对应的第二数据属性的集合。 在第一方面的一种可能的实现方式中,所述根据第一集合以及第二集合生成测试 结果,包括: 若所述第一集合与所述第二集合相同,则生成正常结果; 若所述第一集合与所述第二集合无交集,则生成第二异常结果,所述第二异常结 果用于提示用户重新进行测试; 若所述第一集合真包含所述第二集合,则生成第三异常结果,所述第三异常结果 用于提示用户删除所述第一集合中不属于所述第二集合的第一数据属性; 若所述第二集合真包含所述第一集合,则生成第四异常结果,所述第四异常结果 用于提示用户将所述第二集合中不属于所述第一集合的第二数据属性添加到所述第一集 合中。 在第一方面的一种可能的实现方式中,所述方法还包括: 获取多组训练样本,其中,每组训练样本包括一个正则表达式和所述正则表达式 对应的后端代码函数; 利用所述多组训练样本对预设的神经网络进行训练,得到训练后的神经网络,并 将所述训练后的神经网络作为所述预设映射关系。 在第一方面的一种可能的实现方式中,所述利用所述多组训练样本对预设的神经 网络进行训练,包括: 对于每组训练样本,将所述训练样本中的正则表达式根据语法结构划分为至少一 个语元,并将所述语元作为所述神经网络的输入。 第二方面,本申请实施例提供了一种数据库结构测试装置,包括: 获取单元,用于获取前端代码中待检测的正则表达式,并将符合前端代码语言规 则的所述正则表达式转换为符合结构化查询语言规则的第一数据库数据,其中,所述第一 数据库数据包括第一数据库字段以及所述第一数据库字段对应的第一数据属性; 提取单元,用于从预设的数据库中提取与所述第一数据库字段匹配的所有第二数 据库字段,以及每个第二数据库字段对应的第二数据属性; 测试单元,用于将所述第一数据库数据分别和每组第二数据库数据进行对比,得 5 CN 111597164 A 说 明 书 3/11 页 到测试结果,其中,每组第二数据库数据中包括一个第二数据库字段以及与所述第二数据 库字段对应的第二数据属性。 第三方面,本申请实施例提供了一种终端设备,包括存储器、处理器以及存储在所 述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计 算机程序时实现如上述第一方面中任一项所述的数据库结构测试方法。 第四方面,本申请实施例提供了一种计算机可读存储介质,所述计算机可读存储 介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如上述第一方 面中任一项所述的数据库结构测试方法。 第五方面,本申请实施例提供了一种计算机程序产品,当计算机程序产品在终端 设备上运行时,使得终端设备执行上述第一方面中任一项所述的数据库结构测试方法。 可以理解的是,上述第二方面至第五方面的有益效果可以参见上述第一方面中的 相关描述,在此不再赘述。 本申请实施例与现有技术相比存在的有益效果是: 本申请实施例通过获取前端代码中待检测的正则表达式,并将符合前端代码语言 规则的所述正则表达式转换为符合结构化查询语言规则的第一数据库数据,其中,所述第 一数据库数据包括第一数据库字段以及所述第一数据库字段对应的第一数据属性;结构化 查询语言是能够被数据库识别的语言,转换的实质是将前端代码转换为数据库语言;然后 从预设的数据库中提取与所述第一数据库字段匹配的所有第二数据库字段,以及每个第二 数据库字段对应的第二数据属性;将所述第一数据库数据分别和每组第二数据库数据进行 对比,得到测试结果,其中,每组第二数据库数据中包括一个第二数据库字段以及与所述第 二数据库字段对应的第二数据属性。利用上述方法,将前端代码中和数据库中相匹配的字 段对应的数据属性进行对比,通过客观的数据对比,避免了人工测试由于经验导致的错误 结果,提高了测试结果的准确度。通过上述方法,能够对数据库结构进行自动测试,避免了 采用穷举法测试的繁琐,提高了测试效率,同时提高了测试结果的准确率。 附图说明 为了更清楚地说明本申请实施例中的技术方案,下面将对实施例或现有技术描述 中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请的一些 实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些 附图获得其他的附图。 图1是本申请一实施例提供的数据库系统的示意图; 图2是本申请一实施例提供的数据库结构测试方法的流程示意图; 图3是本申请一实施例提供的预设字典建立方法的流程示意图; 图4是本申请一实施例提供的数据库结构测试装置的结构示意图; 图5是本申请一实施例提供的终端设备的结构示意图。











