
技术摘要:
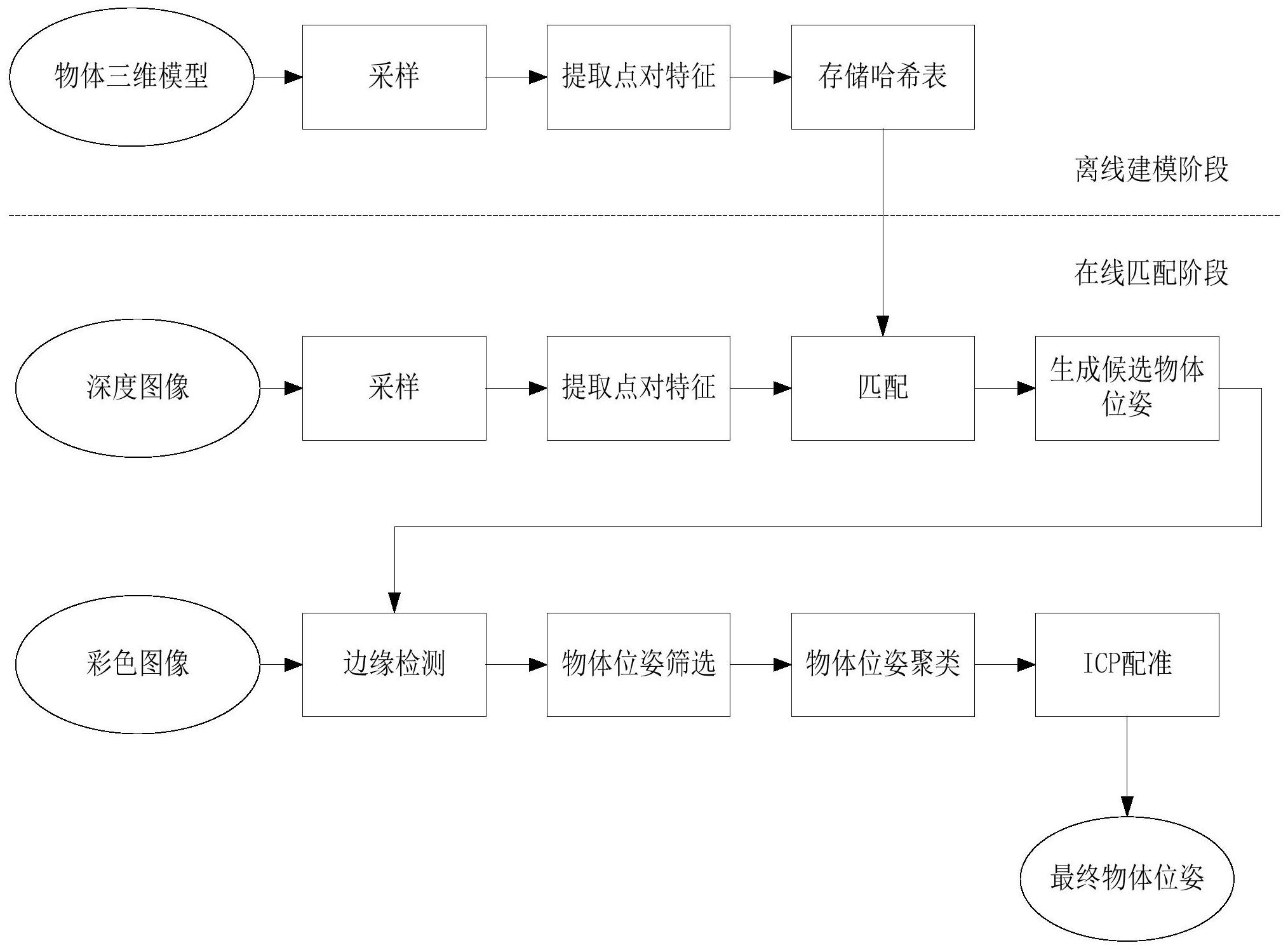
本发明公开了一种物体位姿测量方法、装置及存储介质,所述方法包括离线建模阶段和在线匹配阶段,离线建模阶段是对物体三维模型进行特征建模,并存储起来以供后续场景物体位姿的测量使用;而在线匹配阶段是对给定的场景RGB‑D图像进行物体位姿测量;本发明提供了一种高 全部
背景技术:
近年来随着产业升级的发展,制造业自动化成为经济发展的重要驱动,而制造业 中的机器人自动分拣物体又是制造业自动化的重要表现。物体在三维空间中的位姿是机器 人识别、定位、抓取、操纵物体的重要参考。获取物体位姿的过程称为物体6维姿态测量,这 是三维计算机视觉领域中的重要问题。一个物体从某个参考坐标系下的A处经过旋转平移 变换到B处,这个旋转平移过程记为TAB,TAB由x、y、z共3个平移量和φ、χ、ψ共3个关于坐标轴 的旋转角构成,总共有6个自由度,因此TAB称为该物体的6维姿态,即物体位姿。 一种基于点对特征(Point Pair Feature ,PPF)的方法(Drost et al .Model Globally ,Match Locally:Efficient and Robust 3D Object Recognition .In: Conference on Computer Vision and Pattern Recognition(2010))被广泛应用于物体 姿态测量。该方法构建了整个三维模型的全局特征,然后提取场景中的特征进行匹配。建模 阶段使用了模型的所有点云,有利于表征整个三维模型表面信息。该方法使用了一种4维特 征来表征位于模型表面的两个点之间的信息,该特征由两点间距离、两点法向量的夹角、两 点法向量与两点间距离向量的夹角构成,简称为点对特征(Point Pair Feature,PPF)。PPF 需要量化后存储于哈希表中,方便后续快速查找。模型和场景数据都构造出这些特征来进 行配对,投票获取到一些候选的6维姿态。接下来对这些候选姿态进行聚类,将相似姿态聚 合在一起并求平均,来获得更准确的姿态。接下来使用迭代最近点算法(Iterative Closet Point,ICP)对姿态进行精细化ICP配准,提高姿态的精度。 现有的基于PPF的方法存在着(1)采样方法过度简化的缺点;按照一定大小的栅格 对模型采样时,同一栅格内的点云被简单的求平均,当该栅格内的点云的法向量间的夹角 存在较大变换时,采样方式就会丢失较多表面变化的关键信息,降低了模型表面差异信息 的表达能力。(2)计算量大的缺点;模型点云经过采样后需要对所有点对进行特征计算,但 实际场景中物体在任意视角下的部分往往比模型直径小(模型直径指的是包围模型的边框 的对角线长度),存在着计算冗余。(3)对点云噪声缺少鲁棒性的缺点;相机拍摄到的点云本 身就存在噪声,噪声会使得点云的位置和法向量出现一定偏差,计算出来场景特征会出现 一定的偏差,该方法无法对噪声偏差进行补偿。(4)无法综合利用彩色-深度(RGB-D)图像的 缺点;该方法只在深度图像上运行,只使用了场景的三维空间信息,无法从彩色图像获取某 些信息辅助姿态测量。
技术实现要素:
针对上述至少一个技术问题,本发明的目的在于提供一种物体位姿测量方法、装 置及存储介质。 4 CN 111598946 A 说 明 书 2/10 页 本发明所采取的技术方案是:一方面,本发明实施例包括一种物体位姿测量方法, 包括离线建模阶段和在线匹配阶段; 所述离线建模阶段包括: 输入物体的三维模型,所述三维模型包含模型点云坐标和模型点云法向量; 对所述模型点云坐标和模型点云法向量进行采样; 在采样得到的模型点云坐标和模型点云法向量中构建特征集,计算模型点对特 征; 将提取到的所述模型点对特征存储到哈希表中; 所述在线匹配阶段包括: 输入深度图像,根据相机内参计算出所述深度图像每个像素点对应的场景点云坐 标,并根据所述点云坐标计算出场景点云法向量; 对所述场景点云坐标和场景点云法向量进行采样; 在采样得到的场景点云坐标和场景点云法向量中构建特征集,计算场景点对特 征; 对提取到的所述场景点对特征进行量化并与存储在哈希表中的所述模型点对特 征匹配,获取多个候选物体位姿; 输入彩色图像提取场景边缘点云; 根据所述场景边缘点云对所述候选物体位姿进行筛选; 将筛选得到的候选物体位姿进行聚类,得到多个初步物体位姿; 使用迭代最近点算法对所述初步物体位姿进行配准,得到最终物体位姿。 进一步地,所述对所述模型点云坐标和模型点云法向量进行采样这一步骤,具体 包括: 根据模型点云坐标,计算出包围模型点云的边界框,得到模型点云空间; 对所述模型点云空间进行栅格化,得到多个大小相等的栅格,每个所述栅格包含 多个点云,每个点云包含对应的模型点云坐标和模型点云法向量; 对每个所述栅格中包含的点云根据模型点云法向量之间的夹角的大小进行聚类; 对每个聚类中的模型点云坐标和模型点云法向量求平均值,得到每个栅格采样后 的模型点云坐标和模型点云法向量。 进一步地,所述在采样得到的模型点云坐标和模型点云法向量中构建特征集,计 算模型点对特征这一步骤,具体包括: 对采样得到的模型点云坐标构造K-D树; 选取参考点,所述参考点为采样得到的模型点云坐标中的任意一点; 在所述K-D树中查找目标点,所述目标点为与所述参考点距离小于第一阈值的点; 依次计算所述参考点与目标点构成的模型点对特征。 进一步地,所述将提取到的所述模型点对特征存储到哈希表中这一步骤,具体包 括: 对提取到的所述模型点对特征进行量化处理; 将量化结果通过哈希函数求出一个键值,作为所述点对特征在哈希表中的索引; 将具有相同索引的点对特征存储在哈希表的同一个桶中,不同索引的点对特征存 5 CN 111598946 A 说 明 书 3/10 页 储在哈希表的不同桶中。 进一步地,所述对提取到的所述场景点对特征进行量化并与存储在哈希表中的所 述模型点对特征匹配,获取多个候选物体位姿这一步骤,具体包括: 将提取到的所述场景点对特征进行量化处理; 对量化结果进行扩充,以补偿噪声引起的特征偏移; 将扩充后的多个结果值作为键值,在哈希表中寻找具有相同键值的模型点对特 征; 根据所述模型点对特征,获取多个候选物体位姿。 进一步地,所述输入彩色图像提取场景边缘点云这一步骤,具体包括: 将所述彩色图像进行灰度化; 使用边缘检测器对灰度化后的图像进行边缘检测; 将位于图像边缘处的像素与深度图像一一对应,并根据相机内参计算出像素点的 空间坐标; 提取所述空间坐标作为场景边缘点云。 进一步地,所述根据所述场景边缘点云对所述候选物体位姿进行筛选这一步骤, 具体包括: 根据相机内参,将所述候选物体位姿对应的物体三维模型投射到成像平面,获取 所述三维模型的边缘点云; 在所述三维模型的边缘点云中选取任意一点作为参考点,在所述场景边缘点云中 找出对应的匹配点,所述匹配点为距离所述参考点最近的点; 计算第一距离,所述第一距离为匹配点到参考点的距离,若所述第一距离小于第 二阈值,则保留所述匹配点,否则舍去所述匹配点; 计算被保留的匹配点的点数占所述三维模型的边缘点云中的总点数的比例,若所 述比例大于第三阈值,则保留所述三维模型对应的候选物体位姿,否则舍弃。 进一步地,所述将筛选得到的候选物体位姿进行聚类,得到多个初步物体位姿这 一步骤,具体包括: 选取筛选得到的候选物体位姿中的任意一个为第一候选物体位姿; 分别计算所述第一候选物体位姿与筛选得到的其他候选无物体位姿之间的距离; 将所述筛选得到的候选物体位姿各自初始化为相应个数的聚类; 按照层次化聚类的方法将筛选得到的候选物体位姿进行聚类; 在每个聚类中提取投票分数最高的候选物体位姿,得到多个初步物体姿态。 另一方面,本发明实施例还包括一种物体位姿测量的装置,包括存储器和处理器, 所述存储器用于存储至少一个程序,所述处理器用于加载所述至少一个程序以执行所述的 一种物体位姿测量方法。 另一方面,本发明实施例还包括一种存储介质,其中存储有处理器可执行的指令, 所述处理器可执行的指令在由处理器执行时用于执行所述的一种物体位姿测量方法。 本发明的有益效果是:(1)本发明提供了一种更加高效的模型采样策略,减少了点 云数量,从而能够减少后续运算量;又能够保留足够的物体表面变化信息;(2)限定了计算 点对特征时的距离范围,减少了模型和场景数据的点对特征计算量,也降低了过多背景点 6 CN 111598946 A 说 明 书 4/10 页 云的匹配干扰;(3)提出了量化扩充方法,减少了噪声对点对特征计算产生偏移的影响;(4) 引入了彩色图像信息,增加了输入信息,并从彩色图像提取边缘信息,筛选候选物体位姿并 进行ICP配准,提升了测量精度,从而对于遮挡、聚集、堆叠等情况下的场景识别率更加准 确。 附图说明 图1为实施例所述一种物体位姿测量方法的流程示意图; 图2为实施例所述离线建模阶段的步骤流程图; 图3为实施例所述在线匹配阶段的步骤流程图。











