
技术摘要:
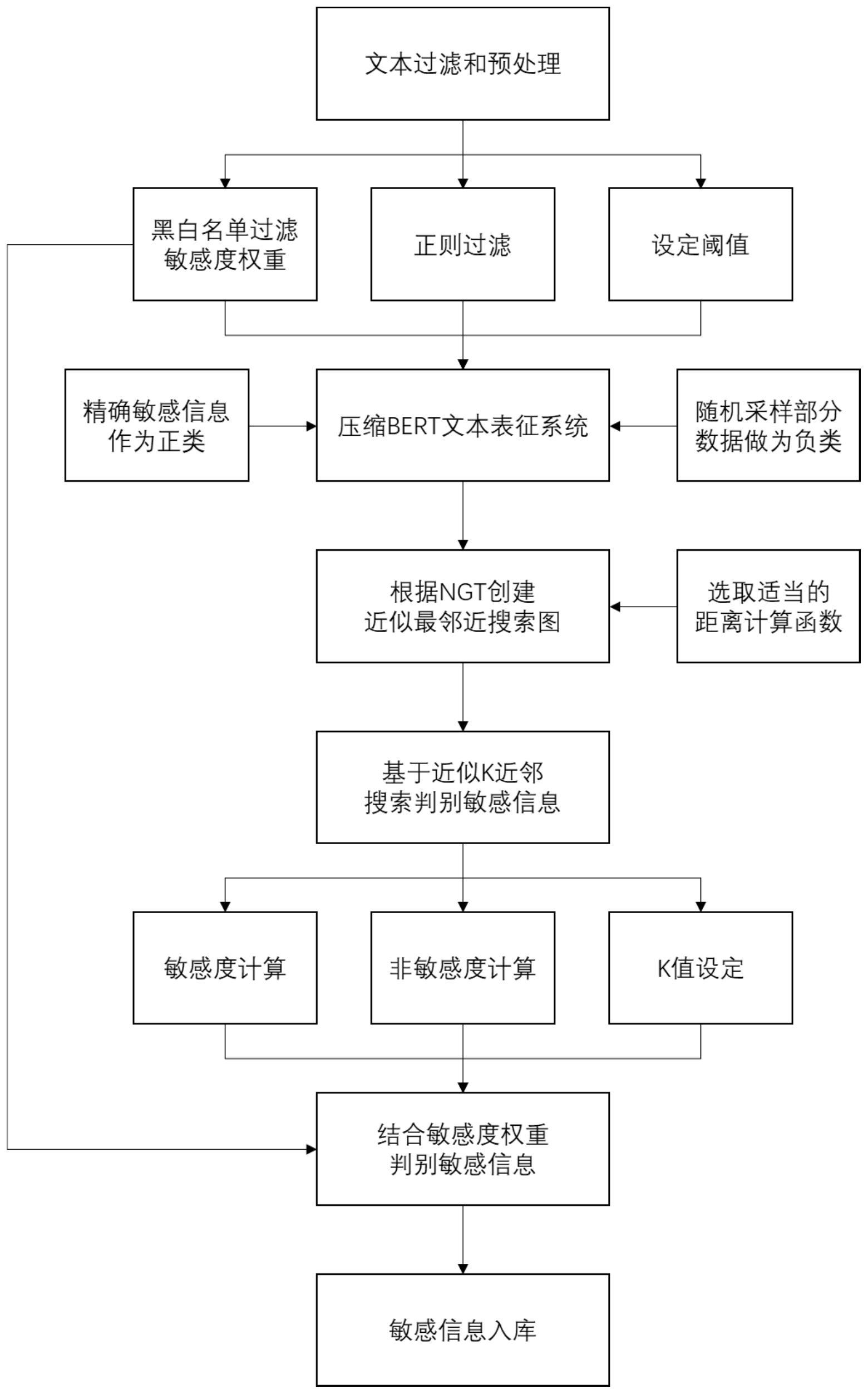
本发明公开了一种基于BERT模型和K近邻的敏感信息识别方法,包括:步骤一、对文本进行预处理;步骤二、标注多条预处理文本为敏感信息和非敏感信息,步骤三、表征得到敏感信息的向量表征和非敏感信息的向量表征;步骤四、以敏感信息的向量表征为正类数据、以非敏感信息的 全部
背景技术:
敏感信息识别作为一项基本技术,已经被各大企业和机构研究多年,并大范围使 用在自己的产品上,以达到对信息的精准识别、过滤和控制。传统的敏感信息识别技术主要 基于敏感词词典的构建与过滤规则的制定,且目前已在各大文本产品,比如论坛、微博上进 行使用,具有快速、准确、易维护的特点。传统的敏感信息识别技术可以在不耗费大量人力 和算力的情况下,对大部分敏感信息进行过滤,对于平常的一般化的使用效果可以满足需 求。 但是随着大数据与人工智能技术的不断发展,人们使用网络的频率越来越高,网 民数量也大幅度提升,从而导致现有的传统技术的精度和速度均已经无法满足要求;而且 随着大量网络词汇的出现,系统的维护成本也不断提升,词典和规则的扩充速度往往无法 超越新词的增长速度。所以在这种情况下,一种仍然拥有传统技术优点,但能够结合新技 术,进一步提升敏感信息识别的速度、精度和易维护性的方法急需等待提出。鉴于目前传统 技术解决敏感信息识别无法满足实际需求的状况。
技术实现要素:
本发明的一个目的是解决至少上述问题,并提供至少后面将说明的优点。 本发明还有一个目的是提供一种基于BERT模型和K近邻的敏感信息识别方法,在 传统技术稳定、快速的优点之上,结合新型深度学习技术的精准、高效的优点,进一步提高 了对敏感信息识别的精度、速度和易维护性。 本发明提供一种基于BERT模型和K近邻的敏感信息识别系统,敏感信息识别的速 度快、精度高,且易维护。 为了实现根据本发明的这些目的和其它优点,提供了一种基于BERT模型和K近邻 的敏感信息识别方法,包括以下步骤: 步骤一、收集多条文本,并对收集到的文本进行预处理:将每条文本经预设的白名 单词汇过滤掉含有白名单词汇的文本,得到文本Ⅰ,并对文本Ⅰ赋予敏感度权重,文本Ⅰ经预 设的黑名单词汇过滤,得到含有黑名单词汇的文本Ⅱ和不含有黑名单词汇的文本Ⅲ,提高 文本Ⅱ的敏感度权重,文本Ⅲ的敏感度权重不变,然后对文本Ⅱ和文本Ⅲ进行去噪处理,得 到多条预处理文本,其中,若文本中含有某一词汇时,则该文本为非敏感信息的概率大于一 阈值,则该词汇即为白名单词汇,若文本中含有某一词汇时,则该文本为敏感信息的概率大 于一阈值,则该词汇为黑名单单词汇; 步骤二、选取多条预处理文本,判断选取出的预处理文本是否为敏感信息,若是敏 感信息则标注为敏感信息,并统计敏感信息的数据量,若不是敏感信息则标注为非敏感信 4 CN 111581956 A 说 明 书 2/8 页 息,并统计非敏感信息的数据量,以及 若非敏感信息的数据量达到敏感信息的数据量的倍数阈值,则执行步骤三; 若非敏感信息的数据量未达到敏感信息的数据量的倍数阈值,则从未被选取的预 处理文本中随机选取多个文本,使随机选取的多个文本和标注为非敏感信息的文本二者一 起的数据量达到敏感信息的数据量的倍数阈值,并将随机选取的多个文本和标注为非敏感 信息的文本一同视为非敏感信息,然后执行步骤三; 步骤三、将敏感信息的文本和非敏感信息的文本输入至经压缩的BERT模型中,得 到多条敏感信息的向量表征和多条非敏感信息的向量表征; 步骤四、以步骤三中的敏感信息的向量表征为正类数据、以非敏感信息的向量表 征为负类数据,构建基于近似最近邻搜索算法的近似最邻近搜索图并保存; 步骤五、将待测文本经步骤一中的预处理和经压缩的BERT模型的处理后得到的待 测文本的向量表征,并输入至步骤四建立的近似最邻近搜索图,搜索得到近似最近邻的K个 节点,判断该K个节点的每一节点的属性,若为正数据,则提升该待测文本的敏感度值,若为 负数据,则提升该待测文本的非敏感度值,然后根据经步骤一处理得到的该条待测文本的 敏感度权重,修正该条文本的敏感度值,若该条文本的修正后的敏感度值高于该条文本的 非敏感度值,则标记该条文本为敏感信息。 优选的是,步骤一中的去噪处理采用正则匹配的方法过滤,并且根据预设的文本 长度阈值过滤掉经正则匹配过滤后的文本,即得所述预处理文本。 优选的是,步骤二中的倍数阈值为十倍。 优选的是,步骤五中待测文本的敏感度值的提升的数值由该节点和待测文本间的 距离计算得到。 优选的是,距离计算采用L1距离、L2距离、余弦相似度、角度距离、汉明距离中的任 意一种。 提供一种基于BERT模型和K近邻的敏感信息识别系统,包括: 存储模块,其用于存储多条文本、白名单词汇、黑名单词汇; 预处理模块,其用于过滤掉每条文本中含有白名单词汇的文本,得到文本Ⅰ,并对 文本Ⅰ赋予敏感度权重,及用于采用黑名单词汇过滤文本Ⅰ,得到含有黑名单词汇的文本Ⅱ 和不含有黑名单词汇的文本Ⅲ,提高文本Ⅱ的敏感度权重,文本Ⅲ的敏感度权重不变,然后 对文本Ⅱ和文本Ⅲ进行去噪处理,得到多条预处理文本; 数据模块,其用于存储标注为敏感信息的文本和统计敏感信息的数据量,用于存 储已标注为非敏感信息的文本和统计非敏感信息的数据量; 以及用于比较数据量大小,若非敏感信息的数据量未达到敏感信息的数据量的倍 数阈值,则从未被选取的预处理文本中随机选取多个文本,使随机选取的多个文本和标注 为非敏感信息的文本二者一起的数据量达到敏感信息的数据量的倍数阈值,并将随机选取 的多个文本和标注为非敏感信息的文本一同保存为非敏感信息; 表征模块,其用于分别将敏感信息的文本和随机选取多条非敏感信息的文本输入 至经压缩的BERT模型中,得到多条敏感信息的向量表征和多条非敏感信息的向量表征; 建模模块,其用于以敏感信息的向量表征为正类数据、以非敏感信息的向量表征 为负类数据,构建基于近似最近邻搜索算法的近似最邻近搜索图并保存; 5 CN 111581956 A 说 明 书 3/8 页 输出模块,其用于调用所述预处理模块对待测文本进行预处理,用于调用所述表 征模块对预处理后的待测文本进行向量表征,用于将待测文本进行向量表征输入至保存的 近似最邻近搜索图,搜索得到待测文本的向量表征的近似最近邻的K个节点,判断该K个节 点的每一节点的属性,若为正数据,则提升该待测文本的敏感度值,若为负数据,则提升该 待测文本的非敏感度值,然后根据预处理模块得到的该条待测文本的敏感度权重,修正该 条文本的敏感度值,若该条文本的修正后的敏感度值高于该条文本的非敏感度值,则标记 该条文本为敏感信息。 优选的是,所述预处理模块采用正则匹配的方法过滤,并且根据预设的文本长度 阈值过滤掉经正则匹配过滤后的文本,即得所述预处理文本。 优选的是,所述输出模块采用计算各节点和待测文本间的距离得到,该距离的计 算方法采用L1距离、L2距离、余弦相似度、角度距离、汉明距离中的任意一种。 提供一种电子设备,包括: 一个或多个处理器; 存储器;以及 一个或多个程序,其中所述一个或多个程序被存储在所述存储器中,并且被配置 成由所述一个或多个处理器执行,所述程序包括用于执行权利要求1~5任一项所述的指 令。 提供一种计算机可读存储介质,存储于具有一种电子设备结合使用的计算机程 序,所述计算机程序可被处理器执行以实现权利要求1~5任一项所述的方法。 本发明至少包括以下有益效果: 第一、在传统的敏感词词典过滤方法的基础上,增添黑白名单词典,进一步过滤掉 噪声数据,提升文本的质量,并结合BERT深度学习文本表征系统获取向量表征,根据NGT第 三方开源库创建近似最近邻搜索图,再基于近似K近邻搜索判别敏感信息,并将敏感信息存 入数据库,从而提升了敏感信息识别的速度和精度,并减少了BERT模型和近似最近邻搜索 图的维护工作,便于相关企业和机构进行敏感信息的分析处理和社会舆情的监控。 第二、海量的文本如果不经过任何过滤,直接输入至BERT模型进行运算,将会对系 统产生巨大压力,本发明使用黑白名单词汇词典对文本进行联合过滤,将文本数量降低到 合理的范围内,减少不必要的计算。针对某次特定的识别任务,使用者可以通过对任务的了 解,结合互联网上开源可获取的敏感词词典,构造各个任务的事件自身的黑名单词汇和白 名单词汇,并存入数据库。 第三、本发明使用BERT模型,加载BERT模型中已经训练好的参数,输入经步骤一过 滤和处理后的纯文本,即可在很短时间内推理得到BERT模型输出的对应向量表征,该向量 表征能够代表对应文本的语义信息,使用该向量表征可以进行进一步BERT模型计算,提升 整体模型精度。 第四、NGT提供命令和库,用于对高维向量数据空间中的大量数据(执行高速近似 最邻近搜索。由于BERT模型返回的向量表征属于高维向量空间,因此基于NGT创建近似最邻 近搜索图,以便于在大量高维数据集中高效的进行近似最近邻搜索。 本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本 发明的研究和实践而为本领域的技术人员所理解。 6 CN 111581956 A 说 明 书 4/8 页 附图说明 图1为本发明的其中一种技术方案的所述敏感信息识别方法的框架图。











