
技术摘要:
本发明公开了一种基于强化学习的服务链映射方法,属于机器学习技术领域。该方法首先考察SFC映射方式对网络资源利用情况以及SFC的QoS的影响,选取合理的QoS指标以及物理网络资源利用情况作为优化指标建立数学模型;其次,在深入理解SFC特性的基础上,针对建立的数学模型 全部
背景技术:
网络运营商提供的服务传统上基于部署在专用硬件设备上的网络功能,并且这些 服务通常具有严格的逻辑顺序。专用硬件和网络功能的紧耦合导致当用户对网络服务的需 求不断增加时,运营商必须密集添加设备,并为这些设备提供存放空间和电力供应,同时对 设备进行操作和管理以满足服务需求。但随着专有硬件设备数量不断增加,集成和操作的 复杂性和能耗也相应增大、增加,使得需要更多资本支出和运营支出。 服务功能链(Service Function Chain, SFC)是网络运营商提供的完整的端到端 服务,其中包含基于业务逻辑要求的特定顺序依次互连的网络中的服务功能。利用NFV技 术,可以将SFC的网络功能在通用设备上实现运行,使端到端服务转化为按顺序连接的VNF (Virtual Network Function,虚拟网络功能)集合,可以有效地部署和管理服务功能链,实 现业务快速提供。SFC映射主要是考虑如何为网络功能选择合适的硬件服务器节点部署和 实例化VNF。服务链的服务提供和服务器资源的利用情况会受到SFC映射的影响。为了保证 网络资源的合理使用,保证 SFC的QoS(Quality of Service,服务质量),对SFC映射算法的 研究显得尤为重要。现有的许多文献主要以最小化网络时延、最大化资源利用率、最小化成 本、最小化能耗等方面进行研究,得到问题的局部最优。 在实际环境场景中,大规模的网络拓扑错综复杂,强化学习算法中的Q-learning 算法因需存储Q矩阵而存在可扩展性问题,空间复杂度随着网络规模的增大迅速提高,并 且,当状态空间特别大的时候,遍历每个状态需要花费很长时间训练,因此并不适用在大规 模网络拓扑下运行。
技术实现要素:
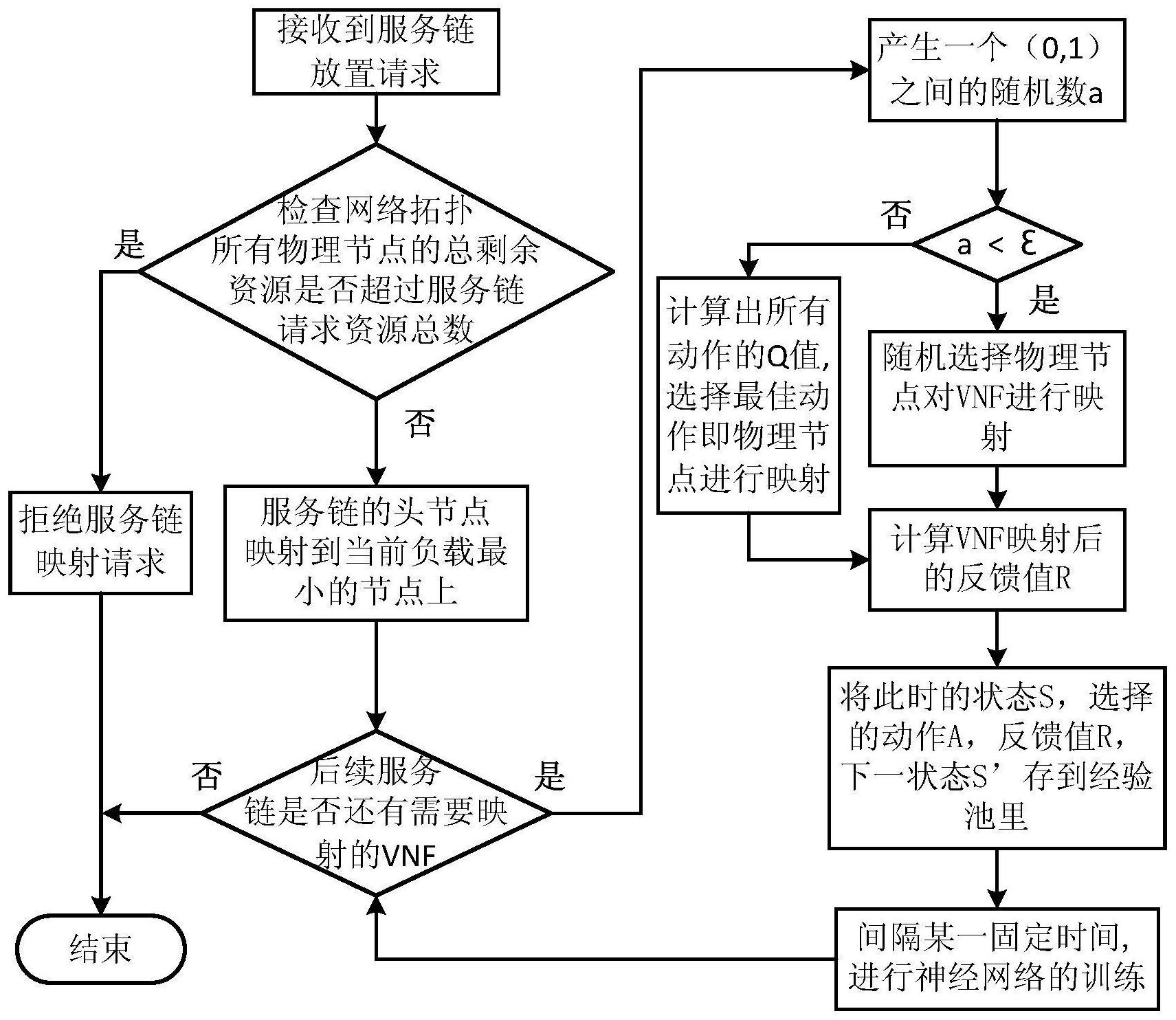
有鉴于此,本发明提出一种基于强化学习的服务链映射方法,该方法在不同规模 的网络拓扑中,均能在尽可能优化系统负载均衡情况的同时,兼顾降低SFC端到端的延时。 为了实现上述目的,本发明采用的技术方案为: 一种基于强化学习的服务链映射方法,包括以下步骤: 步骤1:当接收到服务链映射请求时,检查虚拟网络功能的数量是否超过当前物理网络 拓扑中所有服务器物理节点的总剩余资源,若超过,则转到步骤9;若没有超过,则转到步骤 2; 步骤2:将服务链的头节点映射到当前负载最小的物理节点上;若当前负载最小的物理 节点有多个,则随机选择一个; 步骤3:若单条服务链映射结束,则结束流程,若还未映射完成,则转到步骤4; 步骤4:对于单条服务链的后续虚拟网络功能,随机生成在0、1之间的随机数a,若 a小 于阈值 ,则转到步骤5,否则转到步骤6;阈值 的取值范围为0~0.1; 3 CN 111556173 A 说 明 书 2/4 页 步骤5:随机选择一个物理节点对需要映射的虚拟网络功能进行映射,然后转到步骤7; 步骤6:根据此时物理网络资源和部署情况的状态,使用神经网络计算出所有动作的Q 值,选择其中最佳动作的物理节点进行映射; 步骤7:根据此时底层物理网络资源的状况和服务质量,计算虚拟网络功能映射后的反 馈值,并将此时物理网络资源和部署情况的状态、选择的动作、反馈值以及物理网络资源和 部署情况的下一状态作为一条记录保存到经验池里; 步骤8:每隔一个固定时间后,采用经验池里的数据对所述神经网络进行训练,然后转 到步骤3; 步骤9:拒绝服务链映射请求,结束流程。 进一步的,所述物理网络资源和部署情况的状态为上一个VNF部署位置与当前VNF 全局节点的联合状态;对于VNF的每个节点,若其对vCPU的使用量超过可用vCPU的上限,则 该节点的状态为1,否则为0,所有联合状态所组成的状态空间为S={ , ,…, } ,其中,n = ,N为VNF全局节点的个数。 本发明的有益效果在于: 1、本发明利用强化学习算法,通过在线地根据系统状态、执行映射后环境所给的反馈 值来进行学习,最终确定SFC中各虚拟功能节点的实际部署位置。 2、本方法首先考察SFC映射方式对网络资源利用情况以及SFC的QoS的影响,选取 合理的QoS指标以及物理网络资源利用情况作为优化指标建立数学模型;其次,在深入理解 SFC特性的基础上,针对建立的数学模型,定义强化学习算法所需相关概念(状态机、动作集 和反馈函数),最终使用强化学习来实现映射方法。本发明通过以上步骤,有效地找到了一 种服务链映射方法,该方法在不同规模的网络拓扑中,均能在尽可能优化系统负载均衡情 况的同时,兼顾降低SFC端到端的延时。 3、本发明针对Q-learning算法训练时间长,不适用于大规模网络的的问题,使用 Q-learning的改进算法,即DQN算法,并结合Q-learning和神经网络,将Q-learning算法的 状态当作神经网络的输入,经过神经网络的学习,得到用函数拟合的结果即所有动作的Q 值,按照Q-learning算法选择最大Q值的策略来选择动作,选择动作后得到相应的反馈值, 基于此可以计算要更新的Q值,再将其作为目标值,以当前的Q值作为实际值,目标值和实际 值的偏差作为损失函数,便可以利用深度神经网络训练,以此实现对行为值函数Q(s,a)的 拟合。该方法不需要遍历就能确定最优的动作,从而显著降低了空间复杂度。 附图说明 图 1是本发明实施例中服务链映射方法的流程图。











