 技术摘要:
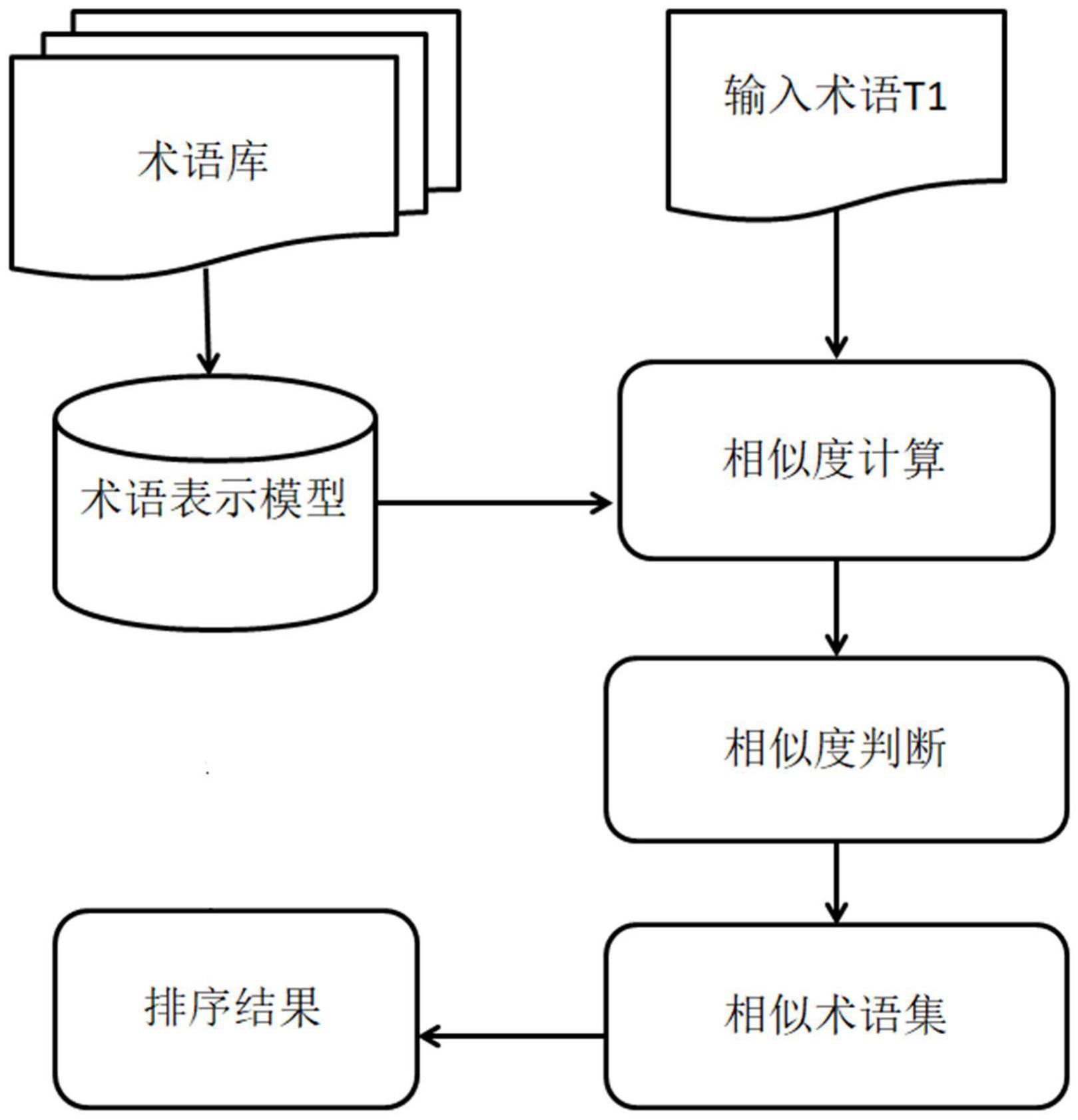
技术摘要: 本发明公开了一种基于多特征的术语检索方法,该方法包括如下步骤:建立术语的表示模型结构的步骤;基于术语的表示模型,对术语名称进行相似度计算得到术语名称相似度的步骤;基于术语的表示模型,对术语的定义及相关特征进行相似度计算得到术语相关特征相似度的步骤; 全部
背景技术:
现实生活和研究中会定义并使用大量的术语,特别是ISO标准等相关文档的撰写
中也需要定义和引用大量的术语,因此出现了越来越多的术语。
如何对术语进行检索,对术语的管理和使用至关重要,也对术语规范化使用提供
技术支撑。在定义和使用术语的时候,可以利用检索算法去检索相关的已定义和已使用的
术语,从而来规范术语的定义和使用,也可以避免重复定义带来的混乱等问题。
针对上述几个问题,本发明提出并且实现了一种基于多特征的术语检索方法。
技术实现要素:
发明目的:为了解决现有技术中的不足,本发明的目的是提供一种基于多特征的
术语检索方法。
技术方案:为解决上述技术问题,本发明提供的一种基于多特征的术语检索方法,
该方法包括如下步骤:
建立术语的表示模型结构的步骤;
基于术语的表示模型,对术语名称进行相似度计算得到术语名称相似度的步骤;
基于术语的表示模型,对术语的定义及相关特征进行相似度计算得到术语相关特
征相似度的步骤;
融合术语名称相似度及术语相关特征相似度,计算得到术语综合相似度的步骤;
融合术语名称相似度、术语相关特征相似度及术语综合相似度,进行多特征检索
得到相似术语的步骤;
对检索得到的相似术语,结合术语综合相似度和术语所属领域信息进行排序的步
骤。
优选的,所述建立术语的表示模型结构的步骤中,基于五元组建立术语的表示模
型结构为:
T=
其中,t为术语的中文名称;et为术语的英文名称;C为术语的所属领域的信息;D为
术语的标准定义;N是其它信息的结合。
优选的,其中,对于术语T1和术语T2,所述基于术语的表示模型,对术语名称进行
相似度计算得到术语名称相似度的步骤,包括:
分别将术语T1和术语T2的中文名称切分成字的集合,进而对术语T1和术语T2的中
文名称进行相似度计算得到术语中文名称相似度的步骤;以及
分别将术语T1和术语T2的英文名称切分成2-gram序列集合,进而对术语T1和术语
T2的英文名称进行相似度计算得到术语英文名称相似度的步骤;以及
5
CN 111597315 A 说 明 书 2/7 页
融合术语中文名称相似度和术语英文名称相似度,得到术语T1和术语T2的术语名
称相似度的步骤;
其中,对于术语T1和术语T2,所述基于术语的表示模型,对术语的定义及相关特征
进行相似度计算得到术语相关特征相似度的步骤,包括:
对术语T1和术语T2的定义进行相似度计算得到术语定义相似度的步骤;以及
对术语T1和术语T2的其它信息进行相似度计算得到术语其它信息相似度的步骤;
以及
融合术语定义相似度和术语其它信息相似度,得到术语T1和术语T2的术语相关特
征相似度的步骤。
作为优选的,所述融合术语名称相似度及术语相关特征相似度,计算得到术语综
合相似度的步骤中,对于术语T1和术语T2,所述术语综合相似度为术语名称相似度和术语
相关特征相似度的均值。
优选的,其中,融合术语名称相似度、术语相关特征相似度及术语综合相似度,进
行多特征检索得到相似术语的步骤,包括:
对于给定术语T1,遍历术语库Dic中的每一个术语进行相似度判断,直到术语库
Dic中所有的术语都判断完毕,得到给定术语T1的相似术语集合resultLst的步骤;
其中,对检索得到的相似术语,结合术语综合相似度和术语所属领域信息进行排
序的步骤,包括:
对于给定术语T1,首先按术语T1与resultLst中各相似术语的术语综合相似度从
大到小的顺序依次排序的步骤;以及
对于其中与术语T1的术语综合相似度的数值相同的若干相似术语,进一步结合术
语表示模型中的术语所属领域信息C进行排序的步骤。
进一步优选的,对于术语T1和术语T2,所述基于术语的表示模型,对术语名称进行
相似度计算得到术语名称相似度的步骤,包括:
21)分别将术语T1和术语T2的中文名称切分成字的集合:将术语T1的中文名称
T1.t=c1…cm切分成字的集合T1_Set={c1,c2..cm},其中m是T1.t的长度;将术语T2的中文
名称T2.t=d1..dn切分成字的集合T2_Set={d1,d2…dn},其中n是T2.t的长度;
22)对术语T1和术语T2的中文名称进行相似度计算得到术语中文名称相似度:
其中Intersection(T1_set ,T2_set)表示括号内两个集合的交集的元素个数,
Union(T1_set,T2_set)表示括号内两个集合的并集的元素个数,LCS(T1.t,T2.t)表示括号
内两个术语中文名称的最长公共子串,Len( )表示括号内串的长度,Max(m,n)表示m,n的最
大值,α为第一权值;
23)分别将术语T1和术语T2的英文名称切分成2-gram序列集合:将术语T1的英文
名称T1.et=w1..wn切分成2-gram序列集合T1_et_set={w1w2,w2w3,…wn-1wn};将术语T2的
英文名称T2.et=w1’…wn’切分成2-gram序列集合T2_et_set={w1’w2’,w2’w3’,… ,wn-1’
wn’};
24)对术语T1和术语T2的英文名称进行相似度计算得到术语英文名称相似度:
6
CN 111597315 A 说 明 书 3/7 页
其中Intersection(T1_et_set,T2_et_set)表示括号内两个集合的交集的元素个
数,Union(T1_et_set,T2_et_set)表示括号内两个集合的并集的元素个数;
25)融合术语中文名称相似度和术语英文名称相似度,得到术语T1和术语T2的术
语名称相似度:
Simname(T1,T2)=β*Simt(T1.t,T2.t) (1-β)*Simet(T1.et,T2.et)
其中,β为第二权值。
进一步优选的,对于术语T1和术语T2,所述基于术语的表示模型,对术语的定义及
相关特征进行相似度计算得到术语相关特征相似度的步骤,包括:
31)对术语T1和术语T2的定义进行相似度计算得到术语定义相似度:
其中Same(T1.D,T2.D)表示括号内两个集合中相同词的个数,Union(T1.D,T2.D)
表示括号内两个集合中所有不同词的个数;
32)对术语T1和术语T2的其它信息进行相似度计算得到术语其它信息相似度:
其中Same(T1.N,T2.N)表示括号内两个集合中相同词的个数,Union(T1.N,T2.N)
表示括号内两个集合中所有不同词的个数;
33)融合术语定义相似度和术语其它信息相似度,得到术语T1和术语T2的术语相
关特征相似度:
Siminfo(T1,T2)=γ*Sim_D(T1.D,T2.D) (1-γ)*Sim_N(T1.N,T2.N)
其中,γ为第三权值。
进一步优选的,所述融合术语名称相似度、术语相关特征相似度及术语综合相似
度,进行多特征检索得到相似术语的步骤中,包括对于给定术语T1,遍历术语库Dic中的每
一个术语进行相似度判断,直到术语库Dic中所有的术语都判断完毕,得到给定术语T1的相
似术语集合resultLst;
其中对于给定术语T1与术语库Dic中的术语T2进行相似度判断的步骤包括:
41)计算术语T1和术语T2的术语名称相似度Simname(T1,T2),判断Simname(T1,T2)是
否大于第一预设阈值θ1,如是,则将T2放入到相似术语集合resultLst中,如否,则进入步骤
42);
42)计算术语T1和术语T2的术语相关特征相似度Siminfo(T1,T2),判断Siminfo(T1,
T2)是否大于第二预设阈值θ2,如是,则将T2放入到相似术语集合resultLst中,如否,则进
入步骤43);
43)计算术语T1和术语T2的术语综合相似度Sim(T1,T2)=(Simname(T1,T2) Siminfo
(T1 ,T2))/2,判断Sim是否大于第三预设阈值θ3,如是,则将T2放入到相似术语集合
resultLst中;如否,则继续进行给定术语T1与术语库Dic中的下一个术语的相似度判断直
至遍历结束。
7
CN 111597315 A 说 明 书 4/7 页
进一步优选的,其中第一权值α、第二权值β和第三权值γ数值相同;所述第一预设
阈值θ1、第二预设阈值θ2、第三预设阈值θ3的取值依次递减。
进一步优选的,所述对检索得到的相似术语,结合术语综合相似度和术语所属领
域信息进行排序的步骤中,对于术语T1,将其通过相似度判断得到的相似术语集合
resultLst中的相似术语进行如下排序:
51)首先按术语T1与resultLst中各相似术语的术语综合相似度从大到小的顺序
依次排序;
52)对于其中与术语T1的术语综合相似度的数值相同的若干相似术语,进一步结
合术语表示模型中的术语所属领域信息C进行排序,排序规则如下:
521)如T1.C=T2.C,则排在此若干相似术语的第一顺序;
522)如 则排在此若干相似术语的第二顺序;
533)如 则排在此若干相似术语的第三顺序;
534)如 则排在此若干相似术语的第四顺序;
535)否则,排在此若干相似术语的最后顺序。
优选的,其中第一权值α=0.8和/或第二权值β=0.8和/或第三权值γ=0.8。
作为进一步的优选方案,其中第一预设阈值θ1=0.75;所述第二预设阈值θ2=
0.7;所述第三预设阈值θ3=0.5。
有益效果:本发明提供的一种基于多特征的术语检索方法,与现有技术相比,其利
用相似度计算方法,计算术语和术语库中的术语的相似度,并经过相似度判断条件得到相
似术语集合,最后利用相似度和术语所属领域信息/分类特征对相似术语进行排序。该方法
能有效的发现检索出相关术语,亦可应用于术语管理平台,一方面可有效节省术语检索的
时间,另一方面能精确的检索出相似术语,并且提供的基于多特征的检索和排序方法对相
似术语集合进行合理排序,满足多种术语检索的应用要求,如对术语检索、使用、录入时按
照相似度排序给出关联展示等等,对术语的编写和规范使用均提供有效的支撑。
附图说明
图1为实施例提供的术语检索方法的流程示意图。












