
技术摘要:
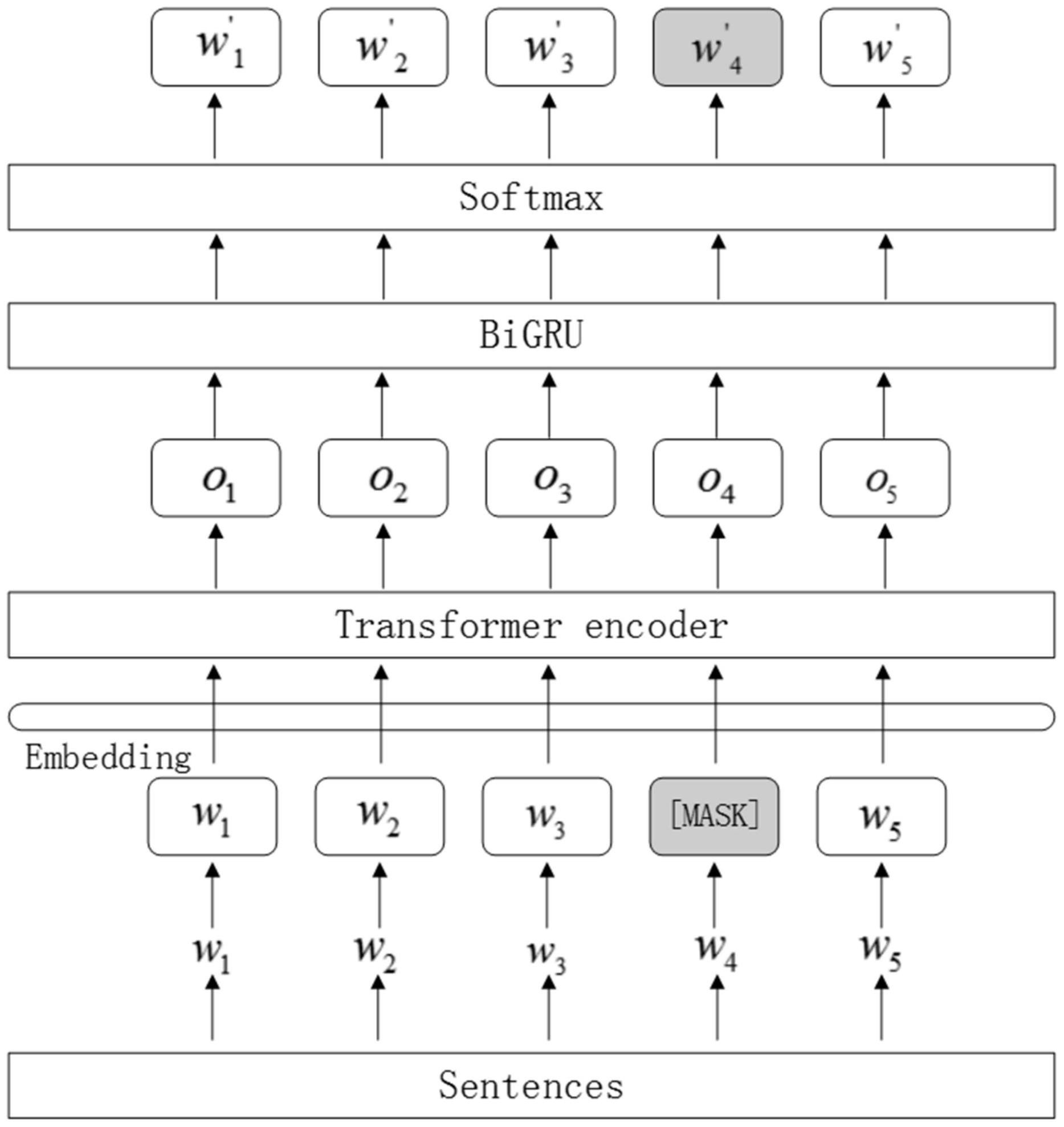
本发明涉及一种基于ERNIE‑BiGRU的中文文本分类方法,该方法包括以下步骤:步骤1:对待中文文本分类的数据集进行预处理,得到经过预处理的数据集;步骤2:建立ERNIE‑BiGRU整体模型,将经过预处理的数据集输入其中的ERNIE预训练模型,得到句子级的词向量表示;步骤3: 全部
背景技术:
文本分类是自然语言处理领域重要的一部分,其研究内容主要包括新闻文本的类 别划分以及情感分析。得益于网络媒体的迅速发展,使得该领域的研究具备海量文本数据 的支持,这些数据蕴含着丰富的信息,如何管理这些数据并从这些数据中准确高效地获取 有价值的信息,这是现在很多研究者正在研究的问题。 近年来,对于文本分类的研究已经取得了不错的进展,Pang等利用词袋模型,结合 贝叶斯、最大熵、支持向量机等分类器对电影评论数据进行情感分类,并取得了不错的结 果。但随着技术的更新,浅层的分类模型在分类任务中无法很好的保留文本上下文信息的 问题逐渐暴露出来,因此研究者开始将目光转向对深度学习模型的研究。 深度学习模型比起传统的浅层模型,强调模型结构的深度和对特征的学习,因而 广泛应用于图像领域的研究。LeCun等人将卷积神经网络(Convolutional Neural Network,CNN)应用于文本分类任务中,显著地提升了文本分类的准确率。Mikolov等人提出 将循环神经网络(Recurrent Neural Network,RNN)应用于文本分类任务中,相较于CNN利 用卷积层提取特征,RNN由于当前时间的输出是根据上一时间的输出和当前时间的输入共 同决定,所以能更好的学习该词上下文的信息。但是RNN模型随着时间序列的增长,模型容 易出现梯度消失和梯度爆炸的问题,导致网络无法从训练数据中得到很好的学习。为了解 决RNN结构上的缺陷,基于RNN的各种变体孕育而生,如长短期记忆神经网络(Long Short- Term Memory,LSTM)、门限循环单元(Gated Recurrent Unit,GRU)等,并在自然语言任务中 取得了不错的结果。 这些模型的共性是对分词后的文本利用词嵌入模型(word2vec)将每个单词映射 成一个向量,将文本细化成句,词级别,然后将结果传入下游模型进行特征提取和分类处 理。因此,文本信息的特征表示好坏与否对下游模型的准确率影响重大,而文本本身存在特 征稀疏的情况。分词后的文本特征已经有相当程度的丢失,词嵌入模型的输出结果并不能 完整的表示原始文本的语义。另一方面,由于应用场景的不同,使得每一次任务都需要对当 前场景下的语料进行训练,这对于模型的灵活性和泛化性都是较大的挑战。因此,为了最大 限度的保留句子本身的含义,人们开始将研究重点转向以句子为单位的特征表示方法。 目前,基于大语料库的预训练模型已经逐步成为了自然语言处理技术的研究趋 势。由于这些预训练模型是以庞大的语料库作为基础训练出来的,因此相较于特定场景的 语料库训练出的模型更能适应不同场景下的文本任务。为了更好地解决预训练模型中句子 级的文本分类问题,尽可能的保留句子中词与词之间的内在联系,Peters等人对预训练模 型进行了改进,提出语言模型嵌入(Embeddings from Language Models,ELMO)算法。ELMO 是一种新型深度语境化词表征,利用深度双向语言模型(Bi-directional Long Short- 4 CN 111581383 A 说 明 书 2/5 页 Term Memory,BiLSTM)内部状态的函数在大语料上训练出对应的语言模型,以此来获取句 子中的句法特点以及词在不同语境中的语义特征。在此基础上,Google提出了使用 Transformer解码器的思想,利用注意力机制的模型结构,计算的时间复杂度相较于传统的 深度神经网络有很大的提升,同时可以捕捉长距离的依赖关系。但是ELMO严格来说是属于 单向训练的语言模型,其双向的结构存在着时间先后的关系,不是真正意义上同步进行的, 因此google提出了真正意义上使用双向的预训练语言模型BERT。BERT利用attention机制, 使得模型的上下层直接全部互相连接,真正实现了模型中所有层都是双向连接的。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于ERNIE- BiGRU的中文文本分类方法。 本发明的目的可以通过以下技术方案来实现: 一种基于ERNIE-BiGRU的中文文本分类方法,该方法包括以下步骤: 步骤1:对待中文文本分类的数据集进行预处理,得到经过预处理的数据集,并建 立ERNIE-BiGRU整体模型; 步骤2:将经过预处理的数据集输入ERNIE-BiGRU整体模型中的ERNIE预训练模型, 得到句子级的词向量表示; 步骤3:将句子级的词向量表示输入ERNIE-BiGRU整体模型中的BiGRU层进一步提 取句子中每个词的上下文信息; 步骤4:将句子级的词向量表示和句子中每个词的上下文信息输入ERNIE-BiGRU整 体模型中的softmax层,得到最终中文文本分类结果。 进一步地,所述的步骤1中的预处理包括针对数字、英文和特殊符号的数据清洗处 理。 进一步地,所述的步骤2中的ERNIE预训练模型由Transformer编码器和知识整合 组成。 进一步地,所述的步骤2包括以下分步骤: 步骤201:设置ERNIE-BiGRU整体模型中的ERNIE预训练模型的参数,并将经过预处 理的数据集输入ERNIE-BiGRU整体模型中的ERNIE预训练模型; 步骤202:利用ERNIE预训练模型中的Transformer编码器对文本信息进行编码,得 到经过预处理的数据集对应的词向量表示; 步骤203:利用ERNIE预训练模型中的知识整合的基本遮掩在字的层面上对文本进 行遮蔽,得到字的层次的知识整合信息; 步骤204:利用ERNIE预训练模型中的知识整合的短语级遮蔽将句子中的短语成分 进行遮蔽,得到短语的层次的知识整合信息; 步骤205:利用ERNIE预训练模型中的知识整合的实体级遮蔽将句子中的实体信息 进行遮蔽,得到实体的层次的知识整合信息; 步骤206:将字、短语和实体的层次的知识整合信息整合到经过预处理的数据集对 应的词向量表示中,得到句子级的词向量表示。 进一步地,所述的步骤202中的Transformer编码器采用全attention机制的结构。 5 CN 111581383 A 说 明 书 3/5 页 进一步地,所述的步骤202中的Transformer编码器的self-attention机制的描述 公式为: 式中,Q、K、V均为输入字向量矩阵,dk为输入向量维度,T表示转置。 进一步地,所述的步骤3中的BiGRU层的基本单元有前向传播的GRU单元和后向传 播GRU单元组成。 进一步地,所述的步骤3中的BiGRU层,其对应的计算处理公式为: zt=σ(ωz·[ht-1,xt]) rt=σ(ωr·[ht-1,xt]) 式中,ωr、ωz和ω为权值矩阵,xt为t时刻的输入,rt为重置门,zt为更新门,ht-1为 前一时刻的隐藏层状态,ht为t时刻的隐藏层状态,σ为sigmoid非线性激活函数。 与现有技术相比,本发明具有以下优点: (1)为解决传统文本分类任务中词向量的表示无法很好的保留字在句子中的信息 和其多义性的问题,本发明方案提出的ERNIE模型,根据上下文计算出字的向量表示,在保 留该字上下文信息的同时也能根据字的多义性进行调整,增强了字的语义表示; (2)为解决传统文本分类模型在不同应用场景内的泛化能力低下的问题,本发明 方案提出的ERNIE模型是基于大语料库的预训练模型,是以庞大的语料库作为基础训练出 来的,因此相较于特定场景的语料库训练出的模型更能适应不同场景下的文本任务; (3)为解决传统深度学习模型结构复杂且运算的时间成本和设备成本过高的问 题,本发明方案提出的BiGRU模型,可以大幅减少模型训练的时间成本,同时也解决了循环 神经网络普遍存在的梯度消失问题。 附图说明 图1为本发明一种基于ERNIE-BiGRU的中文文本分类方法的整体模型结构图; 图2为本发明一种基于ERNIE-BiGRU的中文文本分类方法整体模型中的ERNIE预训 练模型结构图; 图3为本发明一种基于ERNIE-BiGRU的中文文本分类方法整体模型中的 Transformer编码器结构图; 图4为本发明一种基于ERNIE-BiGRU的中文文本分类方法整体模型中的BiGRU模型 结构图。











