
技术摘要:
本发明属于网络信息技术领域,涉及一种新事件主题提取方法,基于BERT对新闻事件文本数据集进行向量化表示,其上下文的联系更密切,表达方式更准确,而且利用注意力机制的双向长短记忆网络实现了对网络中的大数据量的新闻文本进行学习,用以发现新事件,实现对数据的高 全部
背景技术:
: 伴随着大数据时代互联网的发展,人们被大量来源广泛的新闻信息环绕,比如报 纸、网络等,其中新闻最常见的载体是文本,文本是最容易获取有价值信息的方式。由于不 同来源产生的新闻信息方式各种各样,新闻文本的格式和蕴含的信息也往往杂乱无章,同 时产生新闻信息的数量也极其庞大,完全依赖人工实现中文新闻事件的检测是几乎不可能 的。同时,网络中的大量文本包含着人们对某一个事件的关注程度以及影响,因此针对网络 新闻文本进行挖掘研究有利于尽早发现热点关注事件。 目前热点新闻事件的发现方法多基于人工监控的方法,此方法在网络中的新闻事 件发现监测中需要较高的资源成本,包括以计算机为辅助的方法从网络中获取数据,再由 人工检查的方法同样也费时费力。随着机器学习的兴起,目前普遍采用的事件发现方法是 根据聚类的方法实现,此方法对新闻文本进行聚类发现新事件,但是其在新事件发现方面 精度不高,易造成错误识别。随着神经网络的兴起,其在各个领域都取得了巨大的成就,神 经网络不仅克服了人工构建特征的局限,而且对于大数据其更适用。CN201810696452.6提 供了一种面向领域的中文文本主题句生成方法,其特征在于,包括以下步骤:面向领域文本 数据集,建立相应的领域知识图谱,应用深度神经网络模型对文本进行语义信息抽取,按照 主题句式对文本进行分类,最终生成文本的主题句,该方法通过创建领域知识图谱的方法 获得数据集概念模型和内容叙述模式特性,并利用深度学习模型对文本数据进行标注和分 类训练,进而生成出文本的主题句,实现基于知识的查询和统计。但是该方法还存在以下不 足:首先,该方法只能面向特定的领域数据集,并不适用于各领域通用数据集;其次,该方法 需要创建领域知识图谱,此方式资源开销巨大且需要高度的专业素养;最后,该方法利用深 度学习方法对文本数据进行标注和分类,此操作只能针对特定领域,面对新领域新数据模 型表现较差。因此,需要提供一种新事件主题提取方法,采用深度学习方法,实现新事件的 发现,并利用主题建模的方法实现新事件的主题提取。
技术实现要素:
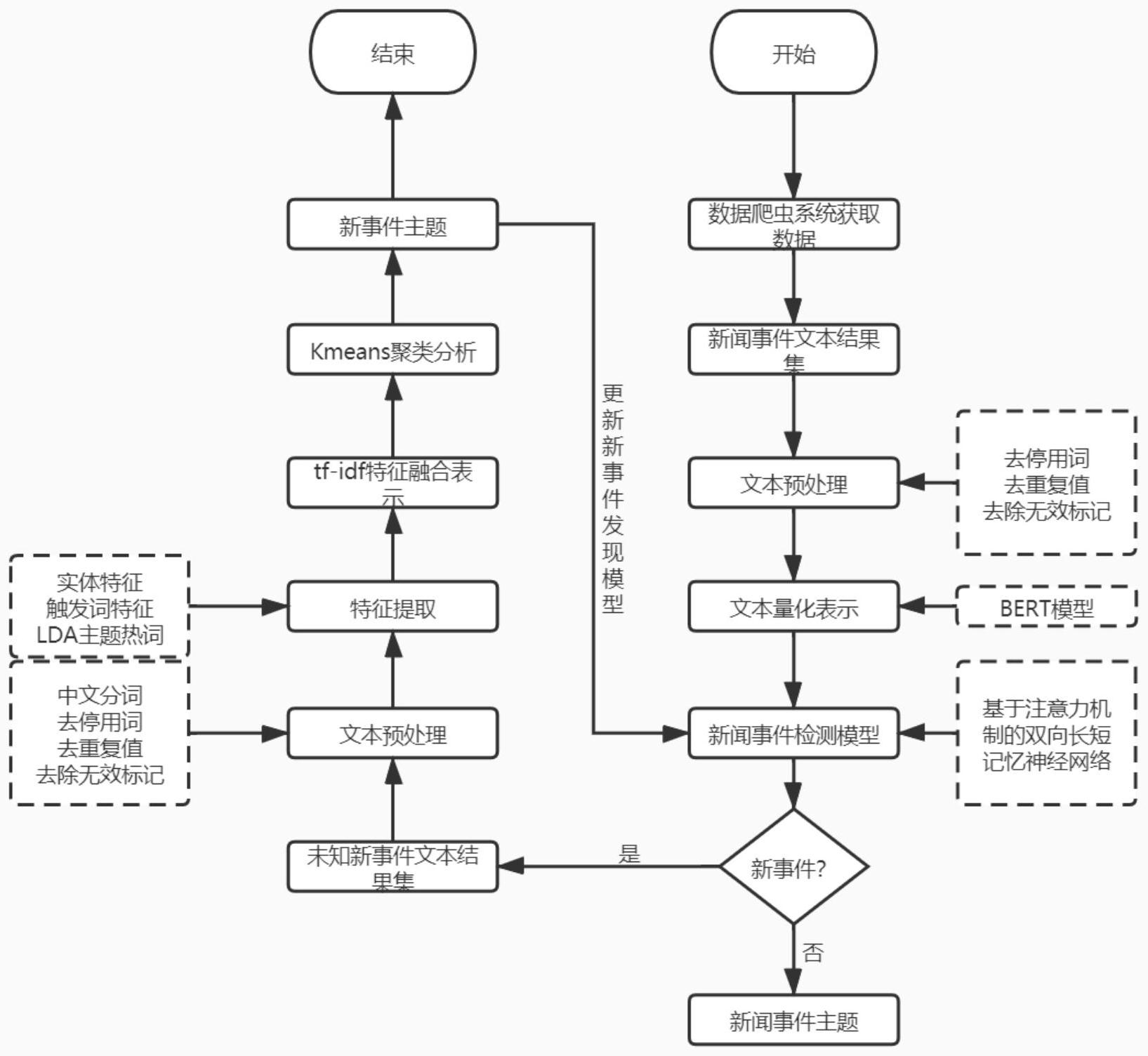
: 本发明的目的在于克服现有技术存在的缺点,设计提供一种基于BERT和注意力机 制的双向长短记忆网络训练新事件发现模型和多特征融合的主题建模分析提取新事件主 题的方法,利用深度学习中的神经网络实现对海量文本数据的挖掘与处理,实现高效准确 分析利用文本数据。 为了实现上述的目标,本发明实现新事件主题提取的过程包括以下步骤: 步骤1:根据事件关键词获取新闻事件文本数据流,根据获取的新闻事件文本数据 3 CN 111597328 A 说 明 书 2/4 页 流,构建新闻事件文本数据集,文本中的每一条记录包括新闻文本的事件类型标签以及事 件的具体文本描述,并将新闻事件文本数据集划分训练集Train、验证集Val和测试集Test; 步骤2:对步骤1划分的训练集Train、验证集Val和测试集Test,以BERT表示模型为 基础,,输出高维稠密向量表示,得到新闻事件文本数据集的高维稠密向量表示,其中BERT 表示模型的模型层数为12,隐藏大小为768,注意力头为12; 步骤3:将步骤2获得的新闻事件文本数据集的高维稠密向量表示作为输入,根据 训练集Train、验证集Val,采用Xavier进行神经网络参数初始化,采用dropout策略以梯度 下降的方法作为神经网络参数及输入特征向量的更新,得到新事件发现模型; 步骤4:设置新事件发现模型的阈值,如果识别结果大于这一阈值,则判定此事件 属于已知新闻事件类型并给出事件的主题;如果预测结果阈值小于设定的阈值则判定此事 件为新事件,对判定为新事件的新闻文本进行整合存储得到新事件文本数据集; 步骤5:对步骤4获得的新事件文本数据集中包含的无用信息进行去除操作,保留 新闻事件文本对新闻事件的描述内容,并采用结巴中文分词工具进行分词后建立自定义词 典提高分词的精度;其中无用信息包括特殊字符、停用词等没有实质价值的标记; 步骤6:对步骤5得到的预处理后的新事件文本数据集提取实体特征和LDA主题热 词特征后与原文进行词级拼接形成新的新闻文本描述,并对实体特征和LDA主题热词特征 通过对特征增加词频的方式进行加权表示;其中实体特征包括人物实体特征、地点实体特 征和组织名实体特征; 步骤7:对于步骤6处理后的新闻文本数据集,计算每个词的词频/逆文档率,用以 衡量每个词相对于当前主题的重要度,并根据计算结果为每个词赋予相应的权重值; 步骤8:根据步骤6、7获得的特征及其权重值,利用Kmeans算法对步骤7得到的新事 件文本数据集按多个事件进行聚类,并对新事件进行主题建模分析;将主题建模分析结果 结合词频/逆文档率对新事件文本集的表示,对每个事件抽取十个关键词作为新事件的主 题词,完成新事件主题的提取。 本发明所述步骤1具体包含以下步骤: 步骤1.1:根据新闻事件文本数据获取需求,确定具体新闻事件的关键词; 步骤1.2:对于确定的新闻事件关键词,构建以Scrapy框架为基础通过百度搜索引 擎获取新闻事件文本数据链接的数据爬虫系统,获取新闻事件文本数据流; 步骤1.3:对于获取的新闻事件文本数据流对文本内容进行规范化操作,去除空格 等无效内容,对剩余有效内容进行拼接处理形成一条记录为一条新闻文本的规范化表示形 成新闻事件文本集; 步骤1 .4:对于步骤1 .3得到的新闻事件文本集,按照7:2:1的比例划分训练集 Train、验证集Val和测试集Test。 本发明与现有技术相比,基于BERT对新闻事件文本数据集进行向量化表示,其上 下文的联系更密切,表达方式更准确,而且利用注意力机制的双向长短记忆网络实现了对 网络中的大数据量的新闻文本进行学习,用以发现新事件,实现对数据的高效准确利用,采 用有监督和无监督方法结合的方式,比单一的方式更有效率,其方法简单,能够深层次提取 语义信息,可以对网络中的新闻文本进行分析与挖掘,实现新事件的发现,有利于相关监管 部门及个人用户对新事件的实时掌控,便于后续的工作。 4 CN 111597328 A 说 明 书 3/4 页 附图说明: 图1为本发明的工作流程示意图。 图2为本发明构建的新事件发现模型结构图。 图3为本发明实体特征抽取模型结构图。 图4为本发明主题抽取过程流程图。











