
技术摘要:
本发明公开了一种渐进增强自学习的无监督跨领域行人再识别方法,该方法首先是在有标签原始域数据集上训练得到的网络模型上提取无标签目标域数据集的初始特征,计算相似度得分矩阵,利用HDBSCAN聚类给予目标域数据伪类标,并利用基于Triplet损失函数进行模型重训,随后 全部
背景技术:
行人再识别是指:给定某摄像头下待检索目标行人,在不同摄像头下将其定位出 来,即逐一确认该目标行人是否出现在其他摄像头下。 行人再识别在视频监控、安全防护、辅助侦查等领域具有十分重要的现实意义。 近年来,随着深度学习的快速发展,许多有监督条件下的行人再识别工作取得了 突飞猛进的效果,即在大量有身份信息的行人数据集上进行深度神经网络训练,并在同一 场景下进行行人再识别。然而,标注大量数据需要巨大的人力和时间成本,因此出现了许多 无监督学习方法,无监督学习方法可以充分利用极易获取的无标签数据。相比于有标签数 据,无标签数据不提供身份信息,使得网络训练缺少指导性,因此采用无监督学习方法进行 行人再识别的效果很差,无法应用于实际生活中。 为了解决无监督学习方法存在的行人再识别效果很差的问题,许多无监督跨领域 方法提出了同时使用有标签数据和无标签数据。然而,直接将在有标签数据(原始域)上训 练好的模型应用到无标签数据(目标域)上会造成极大的性能偏差,主要问题表现在: 1)由摄像头不同所带来的两个不同领域的图片差异性,例如:光照、颜色、清晰度 等; 2)由不同场景所带来的人物特性差异,例如:学校场景下行人多背包或骑车、商场 场景下行人的遮挡问题等。 为了解决上述问题,提高在目标域的识别精度,常用的方法是给予目标域的数据 伪标签,即利用原始域训练好的模型,在目标域上提取特征,并根据特征之间的相关性来对 目标域数据进行分类。该类方法目标是简单有效地对无标签目标域数据进行标注,进而扩 充有标签数据,实现数据增强,提高模型的泛化能力。由于没有使用目标域的真实类标,且 有效利用了原始域所得到的信息,因此该类方法也统称为无监督跨领域方法。 目前,常用的无监督跨领域方法主要是k-means、DBSCAN等聚类方法,这些方法将 无标签目标数据分离成不同的聚类簇,并假设同一个聚类簇的样本属于同一个人。通过这 种方法,将无标签目标数据给予伪类标,进而像有监督学习一样利用带有伪类标的目标样 本进行模型训练。然而,该类方法模型的性能很大程度上取决于聚类效果的好坏,即是否真 实属于同一个人的样本被聚类到同一个聚类簇中。换句话说,模型的性能的好坏取决于样 本的真实类别和伪类标的匹配程度。错误标注的样本与正确标注的样本的比例大小很大程 度上影响了模型的泛化能力。
技术实现要素:
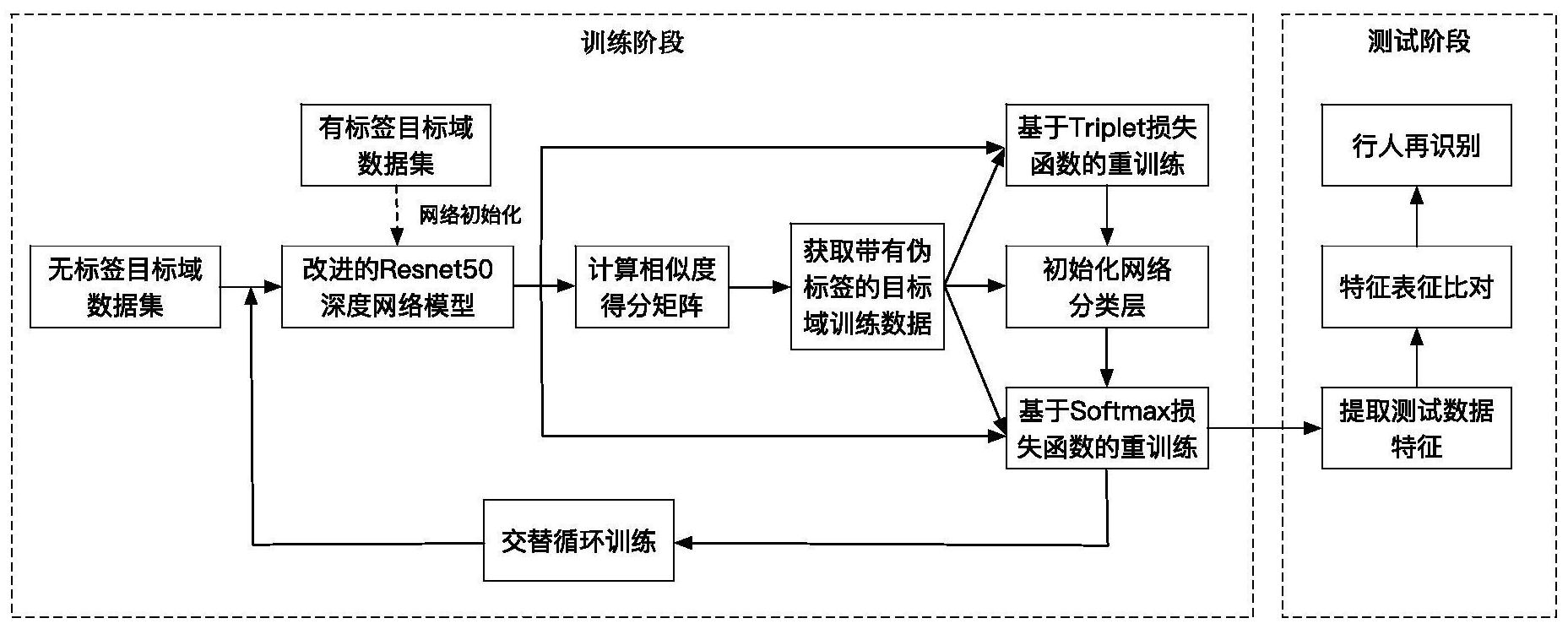
为解决现有技术的不足,本发明的目的在于提供一种渐进增强自学习的无监督跨 3 CN 111598004 A 说 明 书 2/7 页 领域行人再识别方法,该方法通过渐进自学习,能够逐渐增强聚类质量,减少聚类质量低对 于模型训练的不利影响,进而提高模型的泛化能力。 为了实现上述目标,本发明采用如下的技术方案: 一种渐进增强自学习的无监督跨领域行人再识别方法,其特征在于,包括如下步 骤: 步骤1:在有标签原始域数据集S上进行网络模型训练,得到初始的网络模型,前述 初始的网络模型为改进的Resnet-50深度网络模型,该改进的Resnet-50深度网络模型是在 原始的Resnet-50深度网络模型的基础上做的修改,修改的内容包括: (1)将卷积层的卷积核大小由7×7变为3×3; (2)将全局平均池化层变为分块平均池化层; (3)将全连接分类层根据当前网络模型HDBSCAN聚类后的类别数目进行初始化; 步骤2:提取无标签目标域训练数据集T在网络模型上的特征,并计算两两特征之 间的余弦相似度,根据余弦相似度从高到低进行排序,得到相似度得分矩阵DR; 步骤3:利用基于密度的HDBSCAN聚类算法在相似度得分矩阵DR上进行聚类,将无 标签目标域训练数据集T分为C个聚类簇,每一个聚类簇的样本给与相同的类标,得到带有 伪类标的目标域训练数据子集TU; 步骤4:联合使用基于聚类的批次难样本挖掘的Triplet损失函数和基于相似度得 分矩阵DR的Triplet损失函数,在步骤3得到的带有伪类标的目标域训练数据子集TU上进行 网络模型重训练,得到新的网络模型; 步骤5:在步骤4得到的新的网络模型上提取带有伪类标的目标域训练数据子集TU 的特征,并分别对每一个聚类簇的样本特征求均值,得到聚类簇的聚类中心特征,然后利用 得到的聚类中心特征初始化类别数目为C的网络模型分类层参数; 步骤6:将步骤5得到的分类层连接到步骤4得到的新的网络模型上,然后在带有伪 类标的目标域训练数据子集TU上对网络模型再次进行Softmax损失函数指导的网络重训 练,进一步更新网络模型的参数; 步骤7:利用步骤6得到的新的网络模型,在整个无标签目标域训练数据集T上重新 提取特征,并将提取到的特征反馈给步骤2,完成一个循环的训练然后循环执行步骤2到步 骤7,直到网络模型收敛或达到最大循环次数Imax,之后执行步骤8; 步骤8:提取步骤7中全局平均池化层特征或者分块平均池化层特征,以此特征作 为特征表征; 步骤9:利用步骤8得到的特征表征,一一对比测试集和数据库中行人图片的相似 度,并按照相似度从高到低进行排序; 步骤10:针对每一张测试图片,取步骤9中相似度排名前K的对应数据库图片的身 份信息,如果其中包含与测试图片身份信息相同的行人,则记为行人再识别成功,否则记为 行人再识别失败。 本发明的有益之处在于: 1)本发明提出了基于相似度得分矩阵的Triplet损失函数,使得三元组的生成不 依赖于聚类质量的好坏,从而增强了局部特征的表征能力; 2)本发明提出了利用聚类中心特征初始化网络模型分类层,解决了由随机初始化 4 CN 111598004 A 说 明 书 3/7 页 带来的网络模型波动,进而充分利用基于Softmax损失函数训练带来的全局特征表征能力 的提升,解决了由局部特征带来的训练波动,提高了网络模型的收敛能力和泛化性能; 3)本发明提出了渐进增强自学习训练方法,将基于Triplet损失函数的重训练和 基于Softmax损失函数的重训练循环交替进行,使得网络模型能够逐步提升在局部和全局 的特征表征,从而提高了网络模型在无标签目标数据上的表征能力; 4)本发明提取的特征能够很好地表征无标签目标域数据,进而提升了无标签跨领 域行人再识别的准确率和召回率。 附图说明 图1是本发明提出的渐进增强自学习的无监督跨领域行人再识别方法的整体流程 图; 图2是改进的Resnet-50深度网络模型的结构图; 图3是循环训练算法的流程图; 图4是以原始域为有标签Duke数据集、目标域为无标签Market-1501数据集为例, 不同循环训练阶段生成的三元组对示意图,其中,表示生成的三元组对正确, 表示生成 的三元组对错误。











