
技术摘要:
本发明公开了一种声源定位方法及装置,所述方法包括:获取待估计的多通道语音;获取目标降噪模型及目标DOA估计模型;基于所述目标降噪模型及目标DOA估计模型,对所述待估计的多通道语音进行声源定位。通过本发明的技术方案,能够准确的进行声源定位。
背景技术:
声源定位(DOA)是麦克风阵列中的一项重要技术。其作用是在嘈杂环境下判断出 目标说话人与麦克风阵列的相对方向。为后续波束形成操作提供重要且准确的信息。 传统的DOA估计方法在信噪比较高的环境中估计准确率比较理想,但在低信噪比 环境下、非平稳噪声下的效果不理想。当前基于深度学习的DOA估计方法能有效提高低信噪 比环境下的估计准确率,但在多人同时讲话的噪声下的估计性能依旧有待改善。目前多人 同时讲话的识别方法是将多通道的语音同时送入模型,得到该时刻语音的DOA估计值,但该 方法对噪声的鲁棒性需要改进,且在babble等噪声下的估计效果依旧不理想,总的来说,现 有技术对带有噪音的多通道语音声源定位不准确。
技术实现要素:
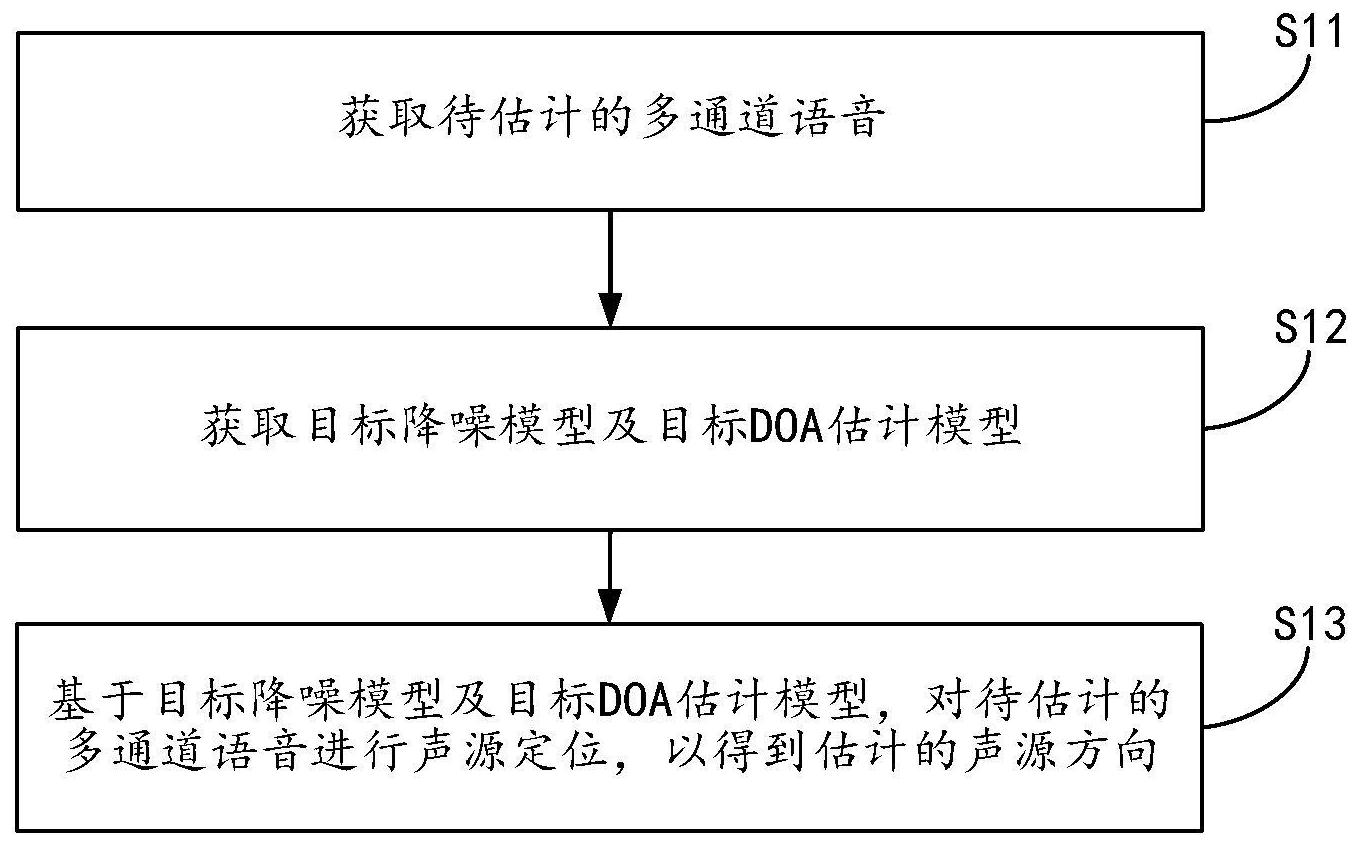
本发明提供一种声源定位方法及装置,所述技术方案如下: 根据本发明实施例的第一方面,提供了一种声源定位方法,包括: 获取待估计的多通道语音; 获取目标降噪模型及目标DOA估计模型; 基于所述目标降噪模型及目标DOA估计模型,对所述待估计的多通道语音进行声 源定位,以得到估计的声源方向。 在一个实施例中,所述获取目标降噪模型,包括: 获取原始降噪模型; 获取若干条第一单通道带噪语音; 对所述若干条第一单通道带噪语音进行特征提取,以得到若干条第一语音特征; 确定所述若干条第一单通道带噪语音分别对应的纯净语音的语谱或mask; 将所述若干条第一语音特征作为所述原始降噪模型的输入,将所述若干条第一单 通道带噪语音分别对应的纯净语音的语谱或mask作为所述原始降噪模型的输出来训练所 述原始降噪模型,以得到所述目标降噪模型。 在一个实施例中,所述获取目标DOA估计模型,包括: 获取作为训练数据的多通道带噪语音; 将所述作为训练数据的多通道带噪语音划分为第一预设数目个第二单通道带噪 语音; 对所述第一预设数目个第二单通道带噪语音进行特征提取,以得到第一预设数目 个第二语音特征; 将所述第一预设数目个第二语音特征输入至所述目标降噪模型,得到所述第一预 设数目个第二单通道带噪语音分别对应的纯净语音的语谱或mask; 5 CN 111596261 A 说 明 书 2/7 页 根据所述第一预设数目个第二单通道带噪语音分别对应的纯净语音的语谱或 mask确定所述目标DOA估计模型。 在一个实施例中,所述根据所述第一预设数目个第二单通道带噪语音分别对应的 纯净语音的语谱或mask确定所述目标DOA估计模型,包括: 获取原始DOA估计模型; 确定所述第一预设数目个第二单通道带噪语音分别对应的纯净语音的语谱或 mask分别对应的DOA标签,其中,所述DOA标签表示声源的方向。 对所述第一预设数目个第二单通道带噪语音分别对应的纯净语音的语谱或mask 进行特征提取,以得到所述第一预设数目个第三语音特征; 将所述第一预设数目个第三语音特征作为所述原始DOA估计模型的输入,将所述 第一预设数目个第二单通道带噪语音分别对应的纯净语音的语谱或mask分别对应的DOA标 签作为所述原始DOA估计模型的输出来训练所述原始DOA估计模型,以得到所述目标DOA估 计模型。 在一个实施例中,所述基于所述目标降噪模型及目标DOA估计模型,对所述待估计 的多通道语音进行声源定位,以得到估计的声源方向,包括 将所述待估计的多通道语音划分为第二预设数目个单通道语音; 对所述第二预设数目个单通道语音进行特征提取,以得到第二预设数目个第四语 音特征; 将所述第二预设数目个第四语音特征输入至所述目标降噪模型,得到第二预设数 目个单通道语音分别对应的纯净语音的语谱或mask; 对所述第二预设数目个单通道语音分别对应的纯净语音的语谱或mask进行特征 提取,以得到第二预设数目个第五语音特征; 将所述第二预设数目个第五语音特征输入至所述目标DOA估计模型,得到估计的 声源方向,得到所述估计的声源方向。 根据本发明实施例的第二方面,提供了一种声源定位装置,包括: 第一获取模块,用于获取待估计的多通道语音; 第二获取模块,用于获取目标降噪模型及目标DOA估计模型; 声源定位模块,用于基于所述目标降噪模型及目标DOA估计模型,对所述待估计的 多通道语音进行声源定位,以得到估计的声源方向。 在一个实施例中,所述第二获取模块,包括: 第一获取子模块,用于获取原始降噪模型; 第二获取子模块,用于获取若干条第一单通道带噪语音; 第一提取子模块,用于对所述若干条第一单通道带噪语音进行特征提取,以得到 若干条第一语音特征; 第一确定子模块,用于确定所述若干条第一单通道带噪语音分别对应的纯净语音 的语谱或mask; 第一训练子模块,用于将所述若干条第一语音特征作为所述原始降噪模型的输 入,将所述若干条第一单通道带噪语音分别对应的纯净语音的语谱或mask作为所述原始降 噪模型的输出来训练所述原始降噪模型,以得到所述目标降噪模型。 6 CN 111596261 A 说 明 书 3/7 页 在一个实施例中,所述第二获取模块,包括: 第三获取子模块,用于获取作为训练数据的多通道带噪语音; 第一划分子模块,用于将所述作为训练数据的多通道带噪语音划分为第一预设数 目个第二单通道带噪语音; 第二提取子模块,用于对所述第一预设数目个第二单通道带噪语音进行特征提 取,以得到第一预设数目个第二语音特征; 第一输入子模块,用于将所述第一预设数目个第二语音特征输入至所述目标降噪 模型,得到所述第一预设数目个第二单通道带噪语音分别对应的纯净语音的语谱或mask; 第二确定子模块,用于根据所述第一预设数目个第二单通道带噪语音分别对应的 纯净语音的语谱或mask确定所述目标DOA估计模型。 在一个实施例中,所述第二确定子模块,包括: 获取单元,用于获取原始DOA估计模型; 确定单元,用于确定所述第一预设数目个第二单通道带噪语音分别对应的纯净语 音的语谱或mask分别对应的DOA标签,其中,所述DOA标签表示声源的方向。 提取单元,用于对所述第一预设数目个第二单通道带噪语音分别对应的纯净语音 的语谱或mask进行特征提取,以得到所述第一预设数目个第三语音特征; 输入单元,用于将所述第一预设数目个第三语音特征作为所述原始DOA估计模型 的输入,将所述第一预设数目个第二单通道带噪语音分别对应的纯净语音的语谱或mask分 别对应的DOA标签作为所述原始DOA估计模型的输出来训练所述原始DOA估计模型,以得到 所述目标DOA估计模型。 在一个实施例中,所述声源定位模块,包括 第二划分子模块,用于将所述待估计的多通道语音划分为第二预设数目个单通道 语音; 第三提取子模块,用于对所述第二预设数目个单通道语音进行特征提取,以得到 第二预设数目个第四语音特征; 第二输入子模块,用于将所述第二预设数目个第四语音特征输入至所述目标降噪 模型,得到第二预设数目个单通道语音分别对应的纯净语音的语谱或mask; 第四提取子模块,用于对所述第二预设数目个单通道语音分别对应的纯净语音的 语谱或mask进行特征提取,以得到第二预设数目个第五语音特征; 第三输入子模块,用于将所述第二预设数目个第五语音特征输入至所述目标DOA 估计模型,得到估计的声源方向,得到所述估计的声源方向。 本发明的实施例提供的技术方案可以包括以下有益效果: 获取待估计的多通道语音;获取目标降噪模型及目标DOA估计模型;进而,基于目 标降噪模型及目标DOA估计模型,对待估计的多通道语音进行声源定位,能够得到估计的声 源方向,通过本发明技术方案,在进行声源定位时,基于目标降噪模型能够除去待估计的多 通道语音中的噪音,然后,基于目标DOA估计模型能准确的进行声源定位,进而得到准确的 声源方向。 本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变 得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明 7 CN 111596261 A 说 明 书 4/7 页 书以及附图中所特别指出的结构来实现和获得。 下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。 附图说明 附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实 施例一起用于解释本发明,并不构成对本发明的限制。在附图中: 图1为本发明一实施例中一种声源定位方法的流程图; 图2为本发明一实施例中另一种声源定位方法的流程图; 图3为本发明一实施例中一种声源定位装置的框图; 图4为本发明一实施例中另一种声源定位方法的框图。











