
技术摘要:
本发明公开了一种基于全贝叶斯方法的推荐系统评分推荐预测方法法。本发明步骤:步骤1.根据用户过去的购买信息建立用户物品评分矩阵R0;步骤2.根据物品属性信息建立物品词向量矩阵X0;步骤3.利用深度学习方法来提取物品词向量矩阵X0的特征信息,通过成批降噪变分自动编 全部
背景技术:
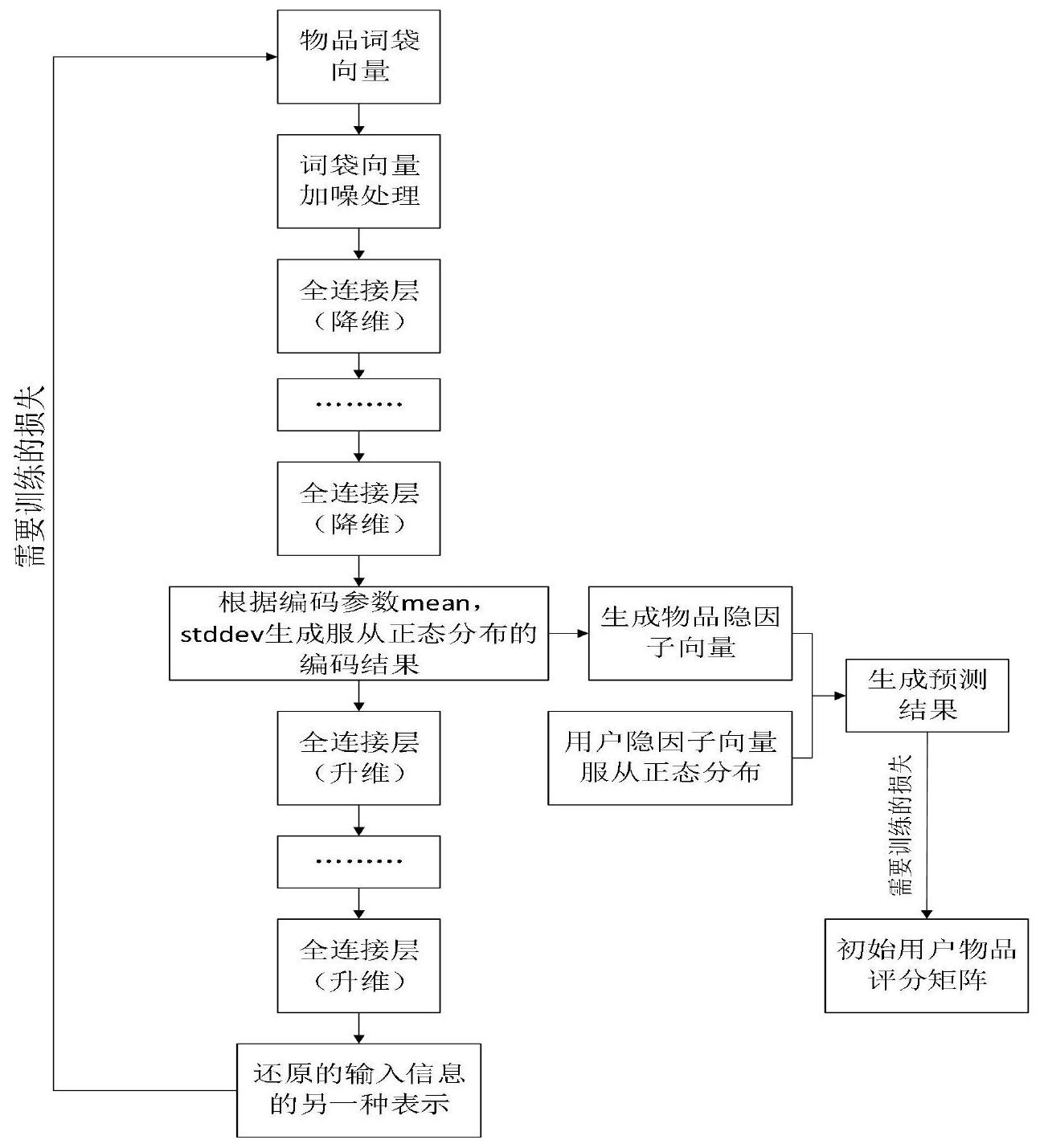
互联网的出现给用户提供了大量的信息,方便了用户的生活的同时也引起了信息 过载的问题,使得在有限时间内难以提取出对用户有效的信息,而这也是导致信息检索效 率下降的主要原因。基于此,个性化推荐技术成为热点技术,并成功地应用于电子商务、社 交网络、音乐电影等的广泛领域。推荐系统能在海量的数据面前有效地完成推荐出有效信 息的任务,迅速检索出对用户最有效的信息,提高了信息利用率,增加了电商等平台销量, 大大推动市场的发展。 但是现今存在的基于内容的推荐系统以及基于协同过滤的推荐系统都在一定程 度上受数据稀疏性以及缺失历史信息等的问题的限制,导致推荐效果大打折扣。基于内容 的推荐系统仅仅依赖于物品属性,推荐的物品基本具有相似属性,推荐结果单一且固定,从 而难以开拓推荐市场;而基于协同过滤的推荐系统则是基于用户过往的浏览信息或者是相 似用户的浏览信息来进行推荐,存在着冷启动“因为缺失用户历史信息而无法进行推荐”以 及数据稀疏性“由于用户浏览信息较海量数据来说微不足道,实际的数据往往是十分稀疏 的,这样的数据对推荐效果将带来灾难性的下降”的问题。因此,需要一种综合考量多方面 信息的个性化推荐系统,是实现高效精准的推荐任务。
技术实现要素:
本发明是针对于传统的推荐系统推荐领域单一,推荐效果差等的问题,提出了名 为协同成批降噪自动编码机的模型,即一种基于全贝叶斯方法的综合了变分自动编码机来 深度挖掘物品属性信息的深度学习综合方法,综合方法即是全面考察了物品内容以及用户 过往历史信息的、结合了基于内容以及基于协同过滤的推荐方法。预测结果为用户是否可 能购买某物品:是/否,这种预测核心为贝叶斯方法论,对于存在有极大不确定性的现实数 据,某事件的发生可能总为一个可能在一定范围内波动的概率值,通过得出的概率经过阈 值判定后得出二值化的推荐结果。 一种基于全贝叶斯方法的推荐系统评分推荐预测算法,具体包括如下步骤: 步骤1.根据用户过去的购买信息建立用户物品评分矩阵R0,矩阵为I*J维,I为参 与测评的用户总数,J为参与测评的物品总数,用户i如果曾经购买了物品j,则用户i对物品 j的评分矩阵元素R0ij为1,否则为0。 5 CN 111612573 A 说 明 书 2/6 页 以用户1举例,表格表明:他购买了物品1,3,4。对于物品2来说:用户1没有购买,但 并不能直接表明用户1不喜欢该物品,有可能是并不知道该物品的存在。 步骤2.根据物品属性信息建立物品词向量矩阵X0,矩阵为J*Voc维,J为参与测评 的物品总数,而Voc为描述物品的属性信息的词典库的大小,每个物品都由一系列在词典库 中的词描述而成,通过独热编码的方式,以0/1的方式表示是否利用x词来形容j物品。 以唱片举例,这种独热方式编码的表格表明唱片可以用:情调、娱乐以及音乐来形 容。 步骤3.利用深度学习方法来提取物品词向量矩阵X0的特征信息,通过成批降噪变 分自动编码机模型来提取这种特征信息。成批降噪变分自动编码机模型是整体构架模型的 一部分,整体构架模型则为协同成批降噪变分自动编码机,具体包含如下步骤: 3-1.用下面的公式对输入的物品词向量矩阵X0添加噪声,来增加一定的鲁棒性。 Xc=Xo*Mask (1) 其中,X c为添加噪声后的物品词向量矩阵;X 0为原始的物品词向量矩阵, [Mask]J*Voc为加噪矩阵,[Mask]J*Voc与X0具有相同的维度,同时[Mask]J*Voc元素满足二项分 布。 将增加了噪声的输入信息输入自动编码机后,仍然能够利用自动编码机的方式使 得输出信息还原出输入信息,则中间编码结果更能表明有效表征物品属性信息。 3-2.构建协同成批降噪变分自动编码机的网络结构; 物品属性信息编码部分的网络结构为一个自动编码机,将输入的物品属性向量经 过多个全连接层降维,得到降维后的物品特征向量;将得到的物品特征向量利用贝叶斯的 方法进行编码,编码的结果即为需要的物品属性向量压缩编码结果,该压缩编码结果服从 根据输入经过多个全连接层提取出来的特征向量的贝叶斯参数形成的正态分布;所述的贝 叶斯参数包括均值以及方差; 接着利用相反维度的多个全连接层进行解码还原输入的物品属性向量。 所述的编码解码方式能够根据具体需要解决的问题来进行相应的替换,如更替为 6 CN 111612573 A 说 明 书 3/6 页 卷积神经网络等,也就是说这里是基本框架。 所述的物品词向量矩中的每一行是物品属性向量; 所述的协同成批降噪变分自动编码机利用服从规则的正态分布来进行初始化,这 种构架下的模型是一种全贝叶斯方法的模型。 初始化的公式如下所示: Wl ,*n为第l层权重矩阵Wl的第n列,bl为第l层的偏执矩阵,τj为求物品特征向量的 偏置量,ui为用户隐因子向量。其中λw,λn,λu为超参数。 所述的用于降维和升维的全连接层的计算过程: Xl,j*=σ(Xl-1,j*Wl bl) Xl,*j为第l层全连接层第j行的输出结果,其中σ表示激活函数。 所述的服从正态分布的贝叶斯参数的计算过程: 其中 代表均值,而δ代表标准差,假定模型的总层数为L,则XL/2为自动编码机最 中间层的压缩特征矩阵,lens为压缩特征矩阵XL/2的列数目,而 被记为before_ XL/2, 被记为after_XL/2。Xencoded代表最终压缩结果; 进一步的,物品隐因子vj的计算: vj=τj Xencoded 所述的物品隐因子即物品特征向量; 进一步的,最终预测结果Rij的计算: 其中,C表示置信矩阵,因为之前提到的用户物品评分矩阵中的0元素,并不直接表 明该用户不喜欢该物品,所以需要用置信矩阵来控制计算结果的可信程度,如果 计算 结果大于0.5,置信矩阵中元素Cij设为a,否则,Cij则设为b。 3-3.协同成批降噪变分自动编码机的训练,训练损失函数如下所示: 7 CN 111612573 A 说 明 书 4/6 页 loss1=λu||ui||2 λw(||Wi||2 ||bi||2) (4) loss=loss1 loss2 (6) 这里的公式(1)用最大似然估计的方法来最小化自动编码机的输入X0与输出XL之 间的误差,公式(2)进行KL散度的计算,来计算编码的中间结果与标准正态分布N(0,1)之间 的近似程度,需要注意这里的编码中间结果为服从 的分布。公式(3)最小化KL散度 等同于最大化ELBO证据下界。这里的公式(6)拆分为了公式(4)、(5),但最终都属于公式(6) 里的loss函数计算。最终loss的计算包含5项,其中||·||2表示进行l2正则化,loss第一项 用于使用户隐因子ui均值保持为0,第二项用于避免过拟合,第三项用于使得物品隐因子vj 与编码结果XEncoded尽可能接近,第四项用于最大化定分下界ELBO,最后一项用于最小化预 测结果Rij与初始已知用户物品评分信息Roij。其中λw,λn,λu,λv,λx都是超参数。再次强调,这 里的所有变量都属于随机变量。 本发明有益效果如下: (1)改善了分层贝叶斯结构,使得具有不确定性的推断有了一定的弹性空间,推荐 准确度有所上升。 (2)利用全贝叶斯结构有效提取了物品隐因子向量,一定程度上解决了数据稀疏 性带来的推荐效率下降问题。 (3)本发明将增加了噪声的输入信息输入自动编码机后,仍然能够利用自动编码 机的方式使得输出信息还原出输入信息,则中间编码结果更能表明有效表征物品属性信 息。 即可以概括为推荐精度以及推荐效率的上升。 附图说明 图1是协同成批降噪自动编码机流程图; 图2是成批降噪自动编码机的一种形式示意图; 图3是概率参数均值与方差的计算示意图。











