
技术摘要:
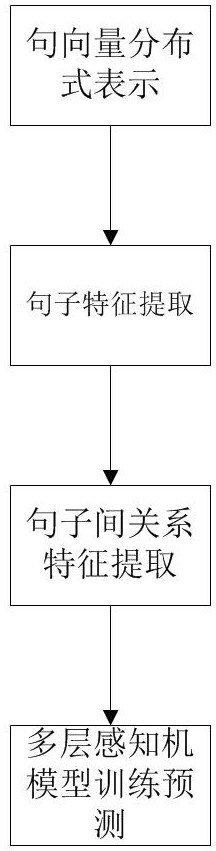
本发明公开了一种基于语句通顺度的自动作文评分计算方法,该方法包括S1:句向量分布式表示;S2:句子特征提取;S3:句子间关系特征提取;S4:多层感知机模型训练预测。本发明提出了将语句通顺度指标应用到自动作文评分领域,用于实现检测发现作文中语义不通顺语句的功 全部
背景技术:
连贯文本的结构建模是自然语言处理中的一个重要问题。连贯性是任何组织良好 的文本的关键特性,它评估文本的逻辑一致性程度,帮助将一组句子按逻辑一致的顺序记 录下来,这是文本生成和多文档摘要等许多文本合成任务的核心。一篇好的文章有一个特 殊的高层逻辑和主题结构,实际的单词和句子选择以及它们之间的转换是为了传达文本的 目的。由于连贯的概念过于抽象,难以捕捉和衡量,很难明确描述文本连贯的属性,语句通 顺度计算模型试图通过学习导致句子以特定顺序出现在人类编写的文本中的高级结构来 理解这些属性。 语句通顺度计算方法,目前的方法集中在以下几个方面: (1)语义中心理论 每一个语段都表现出局部连贯性,即该语段中话语之间的连贯性,以及与语篇中 其他语段的连贯性。与这两个连贯水平相对应的是注意状态的两个组成部分:语段内注意 状态的局部变化模型和语段间注意状态属性的全局变化模型。中心效应被提出作为注意状 态局部成分的模型,局部连贯性与指称表达式选择之间存在相互作用,连贯性的差异在一 定程度上对应于特定注意状态下不同类型指称表达式对推理的不同要求。 (2)基于内容的方法 将文本视为主题序列,并在特定领域内进行主题转移,使用HMMs等条件概率模型, 可以将文本主题进行建模,并提供全局一致性的支持。 (3)基于传统机器学习的方法 将输入文本编码成一组复杂的词汇和句法特征,然后应用机器学习方法(例如SVM 等)来测量基于特征的这些表示之间的相干性。特征包括基于实体的特征、语法特征、命名 实体特征等。但是,识别和定义这些特征始终是一个经验过程,需要大量的经验和领域专业 知识。 (4)基于深度学习的方法 基于深度学习的方法通过克服传统方法的一些问题获得了显著的进步。通过对句 子进行句嵌入和词嵌入编码,句子之间的语义交互作用通过深度神经网络建模,可以实现 端到端的操作,自动发现重要特征。目前,包括递归神经网络,循环神经网络,卷积神经网 络,基于注意力的神经网络等方法都开始应用在语句通顺度计算中,取得了较好的效果。
技术实现要素:
本发明的目的在于,针对现有技术的不足,提出一种基于语句通顺度的自动作文 评分计算方法,通过一种新颖的方式构建了图神经网络,综合了各个句子的相似度计算文 4 CN 111581392 A 说 明 书 2/6 页 档相似度,提高了模型准确性和鲁棒性,同时使用Triplet network引入第三个文档建模句 子间相似度。本发明应用到自动作文评分领域,语句通顺度特征是作文评分的一个重要特 征,可以对作文中出现的语义无关词语和病句有更低的打分,增加了作文评分的准确性和 鲁棒性。 一种基于语句通顺度的自动作文评分计算方法,包括以下步骤: S1:句向量分布式表示; S2:句子特征提取; S3:句子间关系特征提取; S4:多层感知机模型训练预测; 所述句向量分布式表示,用于通过不同词向量分布式表示方法形成句子表示矩 阵; 所述句子特征提取,用于通过卷积层和池化层提取句子特征; 所述句子间关系特征提取,用于通过Self-attention模型提取出句子间关系特 征; 所述多层感知机模型训练预测,用于计算最终语句通顺度得分。 进一步的,步骤S1具体包括以下子步骤: S11:对句子进行分词和去除停用词处理; S12:将分词和去除停用词的结果形成不同类型的词向量; S13:设句子分词和去除停用词后包含词语数量为m,词向量的维度为n,形成一个 n*m维的矩阵作为句子表示。 进一步的,步骤S12所述不同类型的词向量包含以下四种词向量: A.使用预训练过后的100维word2vec词向量; B.使用预训练过后的300维glove词向量; C.使用基于外部知识库的方法,使用TransE知识库图表示算法,训练wordnet知识 库,得到100维wordnet词向量; D .使用分布式同义词方法,计算向量的余弦相似度,得到词语最相似的3个 word2vec词向量,拼接这三个100维的词向量形成代表这个词的300维词向量。 进一步的,基于外部知识库的方法具体包括以下子步骤: C1:基于wordnet知网数据构建知识图谱; C2:构建好的知识图谱中,对于一个三元组(h,l,t),其中h是头实体,t是尾实体,l 是头实体和尾实体的关系,通过采样负样本,构造出了如下损失函数: 其中,d表示L1或L2距离; C3:使用如下方式进行模型的训练:随机初始化实体e和关系l的表示向量正则化 关系l; 每一轮训练都重新将实体e正则化;随机采样出一批正例,对每一条正例采样一些 负例,用hinge loss更新embedding参数; 5 CN 111581392 A 说 明 书 3/6 页 进一步的,步骤S2具体包括以下子步骤: S21:定义一个卷积层,设卷积核的宽度为p,高度为词向量的维度n,则用n*p维的 卷积核进行卷积操作,设卷积核数量为w,形成w个(m-p 1)*1维向量; S22:使用Relu非线性激活函数; S23:加入一个max pooling池化层形成一个w*1维特征向量。 进一步的,步骤S3具体包括以下子步骤: S31:输入三个句子,将这三个句子分别进行步骤S1和S2处理,对于每一个句子,有 四个不同的句向量矩阵表示,因此一共有12个不同的w*1维特征向量; S32:对这12个不同的特征向量加入Self-attention层进行处理; S33:将S2中Self-attention层处理后12个输出向量结果进行拼接,形成一个12*w 维的向量。 进一步的,步骤S4具体包括以下子步骤: S41:对数据训练集进行处理,具体处理方式如下,设一段文字句子数量为k,每三 个句子为一组,最终分组情况为











